
Version originale et plus à jour : http://troumad.org/Linux/Linux.odt
Version
originale et plus à jour : http://troumad.org/Linux/Linux.odt
Table des matières
E ) Les interfaces graphiques 5
G ) Les listes de discussions – aides en ligne 7
II ) Disques et partitions et système de fichiers 8
A ) Structure de disques dur 8
III ) Fichiers, Répertoires et Liens 10
1) présentation 10
2) Les droits 10
C ) Premiers outils pour manipuler les fichiers 10
1) Ligne de commande 10
2) Les scripts 13
3) Interface graphique 18
D ) Résumé des commandes du shell (BASH) 18
IV ) Installation de Mageia 21
B ) Cahier des charges de l'installation 21
A ) Création de comptes et de groupes 22
1) Présentation 22
2) ligne de commande 22
3) interface graphique 23
B ) Système de droits sur les fichiers 24
1) Propriétaire, groupe propriétaire et autres 24
2) Les droits sur les fichiers 24
3) Avec les répertoires 24
4) Les ACL 25
1) ps, top, kill et killall 25
2) exécution d’une commande 25
D ) Arrêt et lancement des démons 27
1) C'est quoi un démon? 27
2) En ligne de commande 27
3) Avec une interface graphique 27
E ) Ajouter/Enlever un programme 28
1) Avec les rpm ou deb 28
2) Sans les rpm 30
F ) Configuration des serveurs 30
G ) Mettre le serveur à l'heure 30
1) En sortir 31
2) Pourquoi ? 31
B ) Attribuer une adresse à la carte ethernet. 32
1) Sous Mandriva 32
2) Sous debian 33
1) Sous Mandriva 33
2) Sous debian 34
E ) Les adresses des PC du réseau 34
A ) La configuration du serveur 36
D ) Ouverture de sessions graphiques 39
E ) Génération des paires de clef privée/publique 39
G ) Se loguer par SSH sans taper de mot de passe 40
1) Le principe 40
2) La pratique 40
3) Automatisation en mode graphique 41
4) Automatisation en mode texte 41
I ) Tunnel ssh (redirection de ports) 41
1) kdessh 42
2) Konqueror 42
L ) Se connecter sur une session graphique en ssh sur un autre ordinateur 43
1) Petite protection en lecture 47
2) Répertoire personnel 47
3) Virtualhost 48
4) Répertoires des sites web sur votre PC 48
5) Ajuster la charge 48
6) Protection intranet-extranet 48
7) Les log 49
1) Mandriva / Mageia 49
2) debian 49
3) Général 49
1) Présentation 50
2) Installation/configuration 50
3) Utilisation d'un serveur DAV 50
1) Avec Mandriva (vieux tuto à arranger sûrement) 51
2) Avec Debian 51
1) Les paquetages 53
2) Répertoire des données 53
3) Plus de sécurité 53
4) Connexion avec l’utilisateur root 54
B ) Création d’une base pour un utilisateur 54
E ) Accessibilité à la base de données de l'extérieur 55
XII ) Partage de données par nfs 57
1) Installation 57
2) Avec un fire-wall 58
3) Protection avec hosts.deny et hosts.allow 58
4) derrière un routeur 59
1) Logiciels à installer 59
2) /etc/fstab 59
3) récupérer le partage 60
4) Fermer le partage 60
1) Présence de NFSv4 60
2) Configuration de kerberos 60
1) Présentations 63
2) Configurer le fichier "zones" 63
3) Configurer le fichier "interfaces" 63
4) Configurer le fichier "masq" 64
5) Configurer le fichier "policy" 64
6) Configurer le fichier "rules" 65
7) Configurer le fichier "tunnels" 67
8) Configurer le fichier "hosts" 67
9) Prendre en compte la configuration 68
1) On vérifie qu'iptables est disponible 68
2) Iptables 68
3) Fichier de configuration 68
4) Mise en place 72
5) Autres astuces 73
1) named.conf 74
2) Fichier named.local 76
3) fichier db.192.168.1 76
4) Fichier named.lycee 77
B ) Fichier de configuration 79
D ) Squid ne trouve plus votre site préféré 80
1) Interdire une personne 83
2) Plusieurs cartes réseaux 83
3) Récupérer les mac adresses des PC du réseau 83
XIX ) Gestion d'un serveur de Courriel (Mail) 85
1) Utilisation normale 85
2) Création d'adresse de groupe (nom à revoir) 85
C ) Premier test : messagerie locale. 85
D ) Second test : vers l'extérieur 86
1) Sans nom de domaine valide 86
2) Avec un nom de domaine valide 87
E ) Troisième test : lire le courriel de l'extérieur 87
F ) Quatrième test : recevoir le courriel de l'extérieur 88
G ) Cinquième test : envoyer le courriel depuis l'extérieur 88
H ) Exemple de fichiers de configuration 88
1) /etc/postfix/main.cf 88
2) /etc/postfix/access 90
L ) Améliorations possibles 90
D ) Changement de mot de passe / ajout d'utilisateurs 92
XXI ) Configurer un serveur d'impression 93
A ) Une imprimante / plusieurs ordinateurs 93
1) Serveur 93
2) Client 93
XXIII ) Configurer un serveur de temps avec ntp 95
B ) Le principe dans ses grandes lignes 95
C ) L'installation concrète 96
1) Configuration de ntp 96
2) Synchroniser un poste LINUX sur votre serveur de temps local 98
3) Synchroniser un poste windows 99
4) Synchroniser un poste MACINTOSH SYSTEME 8 OU 9 99
5) Système MacOSX 99
1) Les rpm 100
2) Le fichier de configuration 100
3) Premiers essais 101
4) Structure des données 103
1) Le schéma 104
2) Les attributs 104
3) Les classes d'objets 105
4) Le Distinguish Name 105
5) LDIF 105
E ) Utiliser OpenLDAP pour l'authentification 105
1) Manipulation sur le serveur 106
2) Installation du client 107
F ) Utiliser OpenLDap pour Samba 108
XXVI ) Configurer et compiler le noyau 112
E ) Les démons et versions de logiciels 114
G ) Visualiser vos ports ouverts 115
I ) Consultez régulièrement vos fichiers de log 116
1) Avec le système init (avant systemctl) 116
2) Avec systemctl 116
J ) La sauvegarde des données 116
1) Le script 117
2) Les besoins 117
3) Version plus simple 117
4) Encore plus simple 117
A ) Installation de Grub 1 119
1) Présentation 119
2) Installation 119
3) menu.lst 120
4) Sécuriser Grub 121
D ) Passerelle Linux avec du Wifi 122
1) Mise à jour Mageia 124
2) Mise à jour debian/ubuntu 124
F ) Onduleurs (UPS en anglais) 124
H ) Sécurité avec un changement de port 126
Le but de ce cours est de montrer que LINUX existe et qu’on peut monter plein de serveurs différents à partir des CD d’installation. Le public visé est une classe de licence professionnelle, le temps d’enseignement est de 4 heures de TD et 9 TP de 4 heures. Ce cours déborde donc largement du peu de temps disponible.
Dans ce document je ne fais que relater mon expérience et je me sers aussi de ce cours pour monter mes propres serveurs. Ceci me permet de le modifier à chaque utilisation. Je n’aborde pas l’installation de tous les serveurs, chaque serveur abordé mériterait à lui seul un livre entier et je ne peux lui consacrer que quelques pages qui sont donc incomplètes.
Je serais heureux de recevoir des remarques constructives à mon adresse : troumad@libertysurf.fr afin d’améliorer ce document qui a comme mission aussi bien d’aider les utilisateurs de LINUX à monter leurs serveurs sur leur PC que de faire découvrir LINUX à des personnes qui s’intéressent à l’installation de serveurs. Je peux aussi rajouter des chapitres sur d’autres serveurs si vous me les passez.
Informations disponibles sur :
http://www.linux-france.org/article/jdanield/V2.0/
http://fr.wikipedia.org/wiki/UNIX#.C3.80_l.27heure_actuelle
Unix est un système d’exploitation multi-utilisateur et multi-tâche né en 1969. Depuis 1973, Unix est écrit en C.
Une des forces d’UNIX est d’être disponible sur plusieurs architectures avec des normes suffisamment strictes qui permettent d’avoir seulement à recompiler un programme pour passer d’une architecture à l’autre.
Depuis 1987, UNIX est même disponible sur PC, le nom de cette première version est Minix.
L’interface utilisateur d’Unix est constituée :
- D’un ensemble de programmes exécutables : les commandes
- Du shell, interpréteur de commande mais aussi, plus que dans n’importe quel autre système d’exploitation, langage de commande permettant d’écrire des programmes, scripts, d’une grande complexité. Travailler en ligne de commande, c’est utiliser la puissance du shell sur une console texte sans interface graphique.
Le 27 septembre 1983, le projet GNUii naît dans la tête de Richard Stallman :
« À dater de ce Thanksgiving, je vais écrire un système d’exploitation complet compatible Unix appelé GNU (pour Gnu N’est_pas Unix) et le donner gratuitement à toute personne qui peut l’utiliser. Des contributions en temps, argent, programmes sont grandement nécessaires ».
« Pourquoi Je Dois Écrire GNU
Je considère que la règle d’or exige que si j’aime un programme je dois le partager avec les autres personnes qui l’aiment. Je ne peux pas, en bonne conscience signer un accord de non divulgation ou de licence sur un logiciel. »
GNU est à l’origine des licences GPL (General Public licence) et donc des logiciels libres. Parmi les logiciels libres, on trouve, entre autre, Linux et une grande partie des logiciels tournant sous Linux.
Au cours de l’année 1991, un étudiant finlandais, Linus Torvalds, trouvant Minix trop limité, décide d’écrire un noyau Unix pour PC. Il réalise quelques modules (juste de quoi faire fonctionner un lecteur de disquettes) et poste le tout sur le site Internet de son université. Depuis Linus Torvalds est resté propriétaire du noyau et en assure la maintenance.
Son initiative allait déchaîner l’enthousiasme de milliers de programmeurs, et le nom du noyau, « Linux » devait bientôt, dans l’esprit du public, supplanter celui de GNU ou de FSF. Pourtant, en nombre d’octets, la contribution de GNU est bien plus importante que celle de Linux.
Attention, Linux est le noyau. Il ne faut pas le confondre avec les interfaces graphiques qui sont disponibles sous Linux (voir chapitre suivant).
Linux est donc un Unix parmi d’autres.
Une interface graphique n’est qu’une interface permettant d’accéder à des commandes qui sont souvent si puissantes, que l’on ne peut vraiment les exploiter à fond seulement en ligne de commande. Prenez l’exemple des logiciels graveurs : 4 ou 5 (et plus) interfaces et au fond, 2, 3 commandes derrière qui sont les mêmes (c’est un peu raccourci, mais c’est quand même l’idée).
Linux dispose de plusieurs interfaces graphiques (windows manager ou WM) connues comme plasma, KDE, Gnome, xfce, ICEwm… Certaines sont plus puissante (plasma) que d’autres qui demandent moins de ressource (ICEwm). Ceci permet de pouvoir installer la version souhaitée en fonction du matériel disponible et des besoins. Sur un petit ordinateur, comme un raspberry, qui peut servir de serveur (http, ftp, samba…), nous pouvons mettre les dernières versions (avec les dernières corrections des derniers bugs trouvés) du serveur avec un WM peu gourmand. On peut même se passer de WM, car la ligne de commande suffit à configurer notre ordinateur.
Lorsque qu’on travaille avec un WM, nous avons la possibilité d’ouvrir des shells ou console pour travailler en ligne de commande ou lancer des programmes graphiques. Certains programmes graphiques, comme ceux de configurations, ne sont que des interfaces (GUI : Graphical User Interface) conviviales pour faire des manipulations faisables en ligne de commande. Personnellement, je trouve la ligne de commande plus puissante, certes elle demande un investissement au départ, mais il est vite rentabilisé !
Les interfaces graphiques sont gérées par un serveur X, iii, programme qui fournit des services graphiques. Il prend en charge la gestion des périphériques d’entrée et de sortie clavier, souris, écran). Ce serveur a d’énormes possibilités que nous ne traiterons pas ici. Par exemple, le serveur peut tourner sur un ordinateur et l’affichage se faire sur un autre.
Une petite force des interfaces graphiques, à tester avec modération (risque de saturation de RAM ou du processeur) avec le x de la fin supérieur à 0 :
startx /etc/X11/xdm/Xsession Gnome -- :X
startx /etc/X11/xdm/Xsession WindowMaker -- :X
startx /etc/X11/xdm/Xsession Enlightenment -- :X
startx /etc/X11/xdm/Xsession BlackBox -- :X
startx /etc/X11/xdm/Xsession IceWM -- :X
startx /etc/X11/xdm/Xsession Sawfish -- :X
startx /etc/X11/xdm/Xsession XFce -- :X
startx /etc/X11/xdm/Xsession KDE -- :X
Vous ouvrez ainsi un terminal, le 7+X avec l'interface choisie (F(7+X) pour y accéder).
startx /etc/X11/xdm/Xsession fluxbox -- :1 & xrandr -s 640x480 -d :1
Cette dernière ligne impose en plus la résolution.
X -query adresse-IP-de-la-machine :1
Vous êtes en Ctrl-Alt-F8 avec une session X ouverte sur un PC distant indiqué par « adresse-IP-de-la-machine ».
Remarque : il est FORT DÉCONSEILLÉ d’ouvrir une interface graphique en tant qu’administrateur. Il faut le faire en tant qu’utilisateur normal et après prendre le contrôle en tant qu’administrateur dans un shell en faisant « su » ou « su - ».
Linux et tous les programmes qui vont avec sont avant tout livrés sous forme de source à compiler. Il est tout à fait faisable de récupérer les sources (voir de les modifier) puis de les compiler. Ceci est particulièrement fastidieux, car il y a souvent une foule de paramètres à régler (il faut connaître parfaitement son système ! ) et c’est vraiment long : plusieurs journées (semaines ?) juste pour la compilation (voir http://www.fr.linuxfromscratch.org/lfs/) . Pour éviter cela, Linux est bien plus souvent diffusé sous forme d’une distribution. Une distribution est un ensemble de programmes (noyaux, commandes, applications…) qui assure une installation d’un système complet et le maintien à jour de tous les programmes.
Voici une liste de distributions :
Mageia (https://www.mageialinux-online.org ou http://www.mageia.org/fr/): c’est la distribution française qui s’est surtout orientée grand public avec un effort sur les outils d’installation et de configuration. Mageia (anciennement Mandrake puis Mandriva) distribue gratuitement une version complète.
Redhat (http://www.fr.redhat.com/), comme Mandriva, RedHat est une entreprise.
Fedora : la redhat gratuite pour test.
Debian (http://www.fr.debian.org/) est la seule distribution relevant d'un projet GNU, elle est surtout prévu pour les serveurs ou les prof.
Ubuntu (http://www.ubuntulinux.org/), une version démocratisée de la debian.
Slackware (http://www.slackware.com/) soit disant la plus Unix des distributions.
SuSE (http://www.suse.de/fr/) est une distribution professionnelle et payante.
OpenSuse : (https://fr.opensuse.org/Bienvenue_sur_openSUSE.org), la Suse gratuite.
Gentoo (http://www.gentoo.org/) fournit un système de paquetage sources qui sont recompilés au moment de l’installation.
LFS (http://www.fr.linuxfromscratch.org/) : un système où on doit tout installer à la main à partir de la compilation du noyau.
Rescuecd (http://rescuecd.sourceforge.net) qui permet en cas de gros soucis de réparer son système (Linux ou Windows), elle est basée sur Debian. Elles n'ont pas d'interfaces graphiques, mais elle est très efficace, et en plus elle est personnalisable très facilement et avec n'importe distribution.
System rescue (http://www.sysresccd.org/index.fr.php) est une autre distribution qui permet réparer un système.
La page http://www.linux-france.org/article/choix-distri/choix-distri.html vous fait un meilleur descriptif.
Nb : les distributions lives deviennent de plus en plus fréquentes. En s’exécutant directement à partir d’un DVD ou d’une clef USB, sans avoir besoin d’être installée sur le disque dur, elles se révèlent très pratiques pour intervenir sur des PC qui ont des problèmes de disques dur afin de pouvoir espérer sauver des données avant la réinstallation d’un nouveau système.
 Illustration
1: Tux
Illustration
1: Tux
Profitons en pour donner la définition de tux d’après http://www.linux-france.org/prj/jargonf/ :
TUX = Petit nom du manchot, souvent confondu avec un pingouin, qui est la mascotte de Linux. Rien à voir avec Tuxedo, même si on peut se douter que Tux est une abréviation du « smoking » que portent certains volatiles… La petite histoire dit que le nom a été choisi lors du concours « Let's Name The Penguin While Linus Is Away Contest » (« Donnons un nom au pingouin pendant que Linus a le dos tourné »).
Il existe des forums d’aide comme http://www.developpez.net/forums/viewforum.php?f=5 qui fournissent des aides complètes (avec une introduction spéciale débutant) comme : http://nepomiachty.developpez.com/config-linux/index.php .
Et surtout, on trouve énormément d’aide sur internet. Tout au long de ce document, je m’en inspire en citant mes sources.

Dessin 1 : plateau de disque dur
Un disque dur est composé de cylindres (pistes) et secteurs, têtes, plateaux. On parle de cylindre quand il y a plusieurs plateaux. Donc s’il y a qu’un seul plateau alors un cylindre = une piste. Voilà a quoi ressemble un disque dur une fois formaté.
Un disque dur peut être divisé en plusieurs partitions,donc le diviser en plusieurs parties comme si on avait plusieurs disques dur indépendants.
Avant l'installation de tout OS, il faut préparer le disque dur, c'est à dire créer des partitions et ensuite créer un système de fichiers. En général sous windows vous avez une partition, avec un système de fichiers (fat16, fat32, NTFS, suivant les versions). Un disque bien préparé devrait posséder au moins deux partitions, une pour le système et l'autre pour les données. Pour installer Linux il faut au minimum 2 partitions, mais je conseille minimum 3. La partition de swap, la partition système, et la partition des données.
La partition swap, sert de mémoire virtuelle, la mémoire virtuelle permet d’augmenter la mémoire, mais elle est très lente, car elle est sur le disque et que le disque a des temps d'accès plus lent
La partition système s’appelle « / » et elle peut être divisée en plusieurs partitions.
La partition contenant les données s’appelle « /home », et elle contient les données de tous les utilisateurs.
Il existe plusieurs types de disques dur, il y a le type IDE et le type SCSI ou SATA, je détaille ces types car Linux les nomment différemment. Avec le noyau 2.4, le nom du périphérique contient 3 lettres + un nombre. Les 2 premières lettres nous donnent le type périphérique, la deuxième le n° du disque dur, et le chiffre le n° de partition.
/dev/fd0 représente le premier (0) lecteur de disquette (fd)
/dev/hda1 représente la première (1) partition du premier (a) disque dur IDE (hd)
/dev/sdb3 représente la troisième (3) partition du deuxième (b) disque dur SCSI (sd)
Avec l’apparition du noyau 2.6, le grand ménage du répertoire /dev a fait changer ses noms en créant des sous-répertoires :
/dev/floppy/0 pour le premier lecteur de disquette (le second sera /dev/floppy/1
/dev/ pour les disques durs
Après avoir partitionné le disque il faut formater la partition, le formatage crée le système de fichiers qui va recevoir les données et le système d’exploitation. Linux reconnaît beaucoup de système de fichiers. Celui utilisé par Linux est ext2, ext3 ou ext4 pour le standard, le premier est non journalisé tandis que le deuxième est journalisé. Mais il en existe d’autres que l’on peut utiliser comme reiserfs ou xfs. Les nouvelles distributions utilisent un système de fichiers journalisé, qui a l’avantage de pouvoir de se réparer plus facilement.
Le répertoire racine est « / », il est créé par défaut, il contient tous les autres sous-répertoires. Chaque répertoire a une signification bien précise, au moins pour les répertoires système. Donc c'est un système bien organisé comme vous allez le voir.
/usr : Ce répertoire contient toutes les ressources du système, son nom signifie « Unix System Ressources ».
/usr/bin : Contient les utilitaires installés sur le système
/usr/lib : Contient les bibliothèques associées aux exécutables de /usr/bin.
/usr/include : Contient les fichiers d’entête, qui sont présents que si on installe les versions de développement. Ne sert que si on veut installer les versions sources des programmes.
/usr/X11 : Concerne tous ce qui concerne Xfree86 ou xorg (l’interface graphique).
/usr/share : Contient les ressources partagées par tous les logiciels présents dans /usr/bin
/usr/local : Il reproduit l’arborescence de /usr, et il contient les programmes installés à partir de sources.
/usr/src : contient les sources des programmes.
/boot : Il contient le noyau et tous ce qui permet à Linux de booter, Il est préférable de mettre cette partition sur les 1024 premiers cylindres, surtout pour les anciennes distributions, car sinon le bootloader ne pourra pas trouver ces fichiers. Il contient aussi le fichier de configuration de grub ou lilo (gestion de démarrage multiboot)
/boot/grub : fichiers de configurations de grub (concurent de lilo)
/root : C’est le répertoire du super utilisateur.
/lib : Contient les librairies et les modules du noyau.
/etc : Contient les fichiers de configuration.
/home : Contient les données des utilisateurs. Chaque utilisateur a son propre répertoire.
/var : Il contient les courriers (si vous avez un serveur de mail), les files d’impressions et les journaux (logs), ces derniers se trouvent dans /var/logs. Par exemple si quelque chose ne va pas, on pourra trouver la raison dans ces fichiers. L’origine de var est variable.
/dev : Contient tous les fichiers gérant les périphériques, son contenu est surtout généré lors du boot.
/proc : Contient l'état du système, à la différence des autres répertoires, « /proc » est stocké en memoire et non sur le disque dur.
/mnt : Sert à monter par exemple des disques amovibles ou disques réseaux... mnt vient de mount.
/media : Remplace parfois /mnt pour monter des « médias » comme les lecteurs de CDROM, DVD ,disquettes, clef USB...
/tmp : C'est un répertoire temporaire.
/opt : Sert à mettre des exécutables en phase de test.
1) Il existe un visualiseur graphique pour analyser l'encombrement des différents répertoires de votre arborescence : filelight. Vous pouvez l'installer avec « urpmi filelight » ou « apt-get install filelight » pour Mageia ou Debian.
2) Il faut savoir que sur Linux tout est fichiers. Pour vous convaincre : « less /home » par exemple.
3) Il arrive (surtout quand, comme moi, on fait sans arrêt des tests sur tout et n’importe quoi) qu’on pense avoir tué la table des partitions. Pour ceci il existe plusieurs programmes qui peuvent vous sauver la vie :
- sfdisk : donne des informations ce qu'il croit être avec « sfdisk -l /dev/sda »
- gpart : un peu plus bavard avec « gpart -l /dev/sda »
- estdisk : pour réparer un boot perdu, monter une partition, copier les fichiers même sans boot (il m'a déjà sauvé)
- photorec : pour récupérer des fichiers sur une partition endommagée et même reformatée.
Avant de rentrer dans le système, il faut savoir comment sont rangées les informations.
Les données sont stockées de manière hiérarchisée arborescente sur les disquettes, disques durs, CD-ROM… Les informations sont dans des cases nommées répertoires, dans ces répertoires on trouve soit des fichiers (qui contiennent les données) soit d’autres répertoires. L’ensemble des répertoires forment l'arborescence de votre système de données.
Sur Unix (Linux donc aussi), la répartition physique des données n’est pas visible de l’utilisateur final si l’administrateur fait bien son travail. On ne parle pas de disque C, du D…(comme dans DOS/Windows) tout est comme si on a un seul disque, même pour les données partagées qui viennent d’un autre ordinateur (voir IX) B) 1) /etc/fstab). Ceci permet à l’utilisateur final de passer d’un ordinateur à l’autre sur un réseau ou de changer de PC sans changer d’environnement, les données de travail étant toujours stockées dans le même répertoire au même endroit dans l’arborescence. Dire que la structure matérielle est complètement transparente, c’est un peu exagéré, car il faut bien savoir où est le CD, la clef USB ou les autres périphériques amovibles ! Régulièrement, c’est dans le répertoire /mnt ou /media. C’est aussi dans ce répertoire que Linux installe (monte) automatiquement les partitions autres comme les partitions windows. Mais Linux étant entièrement libre, on peut faire ce qu’on veut. Ceci peut être modifié lors de l’installation avec le fichier /etc/fstab. La commande « lf » permet de savoir où sont montés les différents médias présents.
Ceci n’est pas toujours évident, vous aurez par la suite une série d’essais pour mieux comprendre ( voir III) C) 1) f) liens )!
On peut, au lieu de dupliquer un fichier, mettre un lien vers ce fichier. Si on modifie le fichier à partir du lien, on modifie le fichier, en revanche, si on l’efface une fois il reste pour l’autre, mais ATTENTION si le lien créé est symbolique. On peut aussi mettre un même fichier dans plusieurs répertoires afin que différentes personnes puissent y accéder avec différents droits.
La différence entre un lien physique et symbolique se voit bien quand on efface le fichier original (voir plus loin).
Un lien symbolique peut permettre par exemple d’avoir un lien vers une application qui pourra être changée lors d’une mise à jour et notre lien lui, inchangé, indiquera la nouvelle version.
Un lien physique sur un fichier ne peut se faire que si le fichier est sur le même système de fichiers (même partition). Il peut être une protection en cas d’effacement intempestif car pour effacer réellement un fichier, il faut effacer tous les liens physiques qui pointent vers lui.
On peut aussi mettre un lien symbolique vers un répertoire pour faciliter la navigation dans l’arborescence.
En fait tout est lien sous Linux. Dans un répertoire, on a des liens vers d’autres répertoires, d’autres fichiers : une information pour savoir où ils sont stockés.
L’important pour pouvoir supprimer le lien symbolique est le propriétaire et le groupe du lien. « chown -h » permet de changer les droits du lien symbolique et non de l’objet pointé. Un « chmod » change les droits du fichier cible.
Il faut savoir que changer les droits d’un lien symbolique ne sert à rien, et ce pour la simple raison qu’ils ne sont jamais pris en compte.
La création/suppression d’un fichier dans un répertoire, dépend uniquement des droits de l’utilisateur dans ce répertoire.
Concernant la lecture/écriture du fichier en question, seul compte les droits du fichier pointé.
Un cas particulier tout de même : lorsque que le sticky bit est activé sur le répertoire qui contient le lien, le propriétaire du lien est pris en compte. Mais c’est à ma connaissance le seul cas.
Pour ceux qui ont connu le DOS, c’est fort semblable. La ligne de commande est très puissante, très rapide et importante à connaître car parfois, à distance par exemple, c’est la seule méthode disponible. Cette méthode semble certes fastidieuse, mais elle se révèle rapidement bien plus efficace et plus précise que les méthodes graphiques.
Dès que vous vous posez une question quant à une commande ayez le bon réflexe : « man la_commande », il y a aussi la possibilité de faire « la_commande --help » mais l’explication est plus restreinte. Pour plus d’explications sur la commande man, faîtes « man man » :-).
Illustration 2: Arborescence visualisée avec une interface
graphique (Konqueror sous KDE)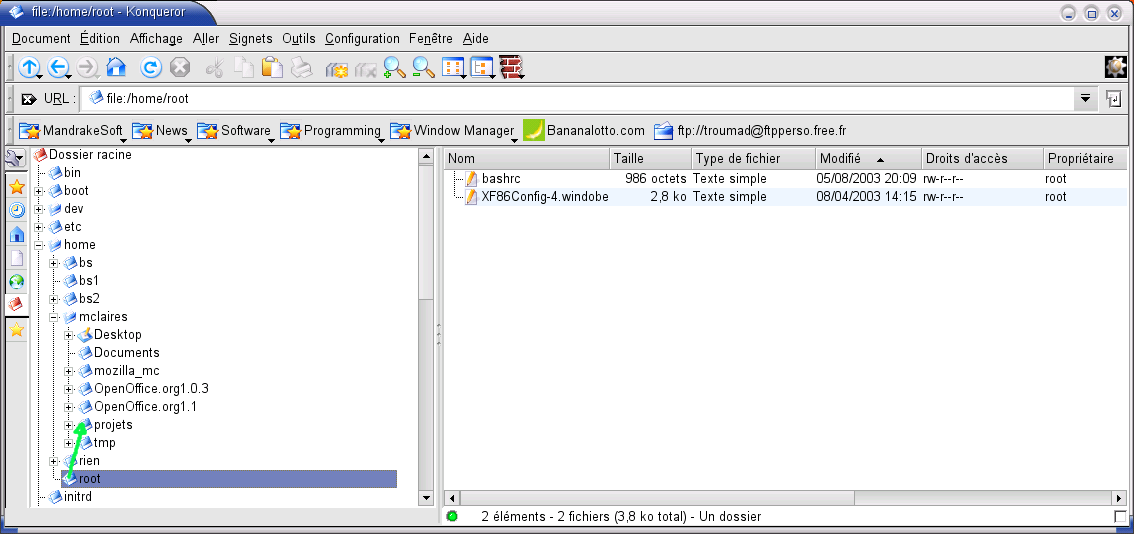
« ls » ne donne que la liste des fichiers, répertoires, liens et autres contenu dans le répertoire. Souvent, il doté d’un affichage coloré pour informer sur la nature du fichier/répertoire, bleu foncé pour un répertoire, bleu clair pour un lien, blanc pour un fichier quelconque et vert pour un exécutable… Même sans couleurs, ces informations sont visibles : un / à la fin du nom pour un répertoire, un @ pour un lien et un * pour un exécutable.
« ll » lui affiche dans l’ordre, les permissions (ou droits : voir plus loin IV) B) Système de droits), le nombre de liens physiques, le propriétaire du fichier et le groupe propriétaire, la taille en octets, l’horodatage ( par défaut l’horodatage présenté est celui de la dernière modification du fichier), et finalement le nom du répertoire/fichier/…
« la » affiche tous les fichiers des répertoires, y compris les fichiers commençant par un « . ».
Une autre information importante est de savoir où on est sur l’arborescence. Cette information est donnée par la commande « pwd ». Vous remarquerez que l’arborescence est indiquée de la manière suivante : /premier_répertoire/second/... . Le séparateur entre répertoire est le séparateur Unix « / » (normal, LINUX est un UNIX), pas le séparateur microsoft « \ ».
« ls -ltr » affiche comme un « ll » avec l’option « l », mais avec un tri par date grâce à l’option « t » dans l’ordre inverse avec l’option « r ». Ceci permet d’avoir à la fin les derniers éléments modifiés, c’est intéressant si la liste est trop longue pour s’afficher entièrement.
La commande de base est « cd » (Change working Directory).
Pour aller à la racine on fait « cd / ». Une fois sur la racine pour aller au répertoire home on fait « cd home ». Ensuite, pour aller dans le répertoire home/root (répertoire de départ de la flèche verte du l'illustration 1), on fait « cd root ». À partir de la racine, on aurait pu faire « cd home/root », en revanche si on est n’importe où, le plus simple est de faire « cd /home/root » : un déplacement absolu.
Pour faire le parcours de la flèche verte de l’illusatration précédente sans passer par la racine, on fait : « cd ../mclaires/projets », c’est un déplacement en mode relatif. On aurait pu faire ce déplacement en se référant à la racine « cd /home/mclaires/projets », cette fois, on a fait un déplacement en mode absolu : on se réfère à la racine.
La touche tabulation étant très utile : elle fait la complétion. Nous allons la tester de suite : taper « cd /ho » + tabulation vous aurez alors « cd /home/ » qui va s’afficher. En effet, elle complète l’affichage jusqu’où elle peut. Si au bout d’un certain avancement il y a plusieurs choix, elle affiche les choix possibles (ou demande s’il est utile de les afficher s’il y en a trop !).
Remarque 1 : un « cd » seul renvoie l’utilisateur sur son répertoire personnel et « cd ~/un_chemin » donne un chemin absolu à partir du répertoire personnel de l’utilisateur.
Remarque 2 : le répertoire personnel de root (administrateur système) est /root régulièrement dans la partition racine. Je copie donc des données importantes de root dans un répertoire que j’attribue à root dans la partition /home afin de sauvegarder des données importantes de root en cas de formatage de la racine si on veut changer de version de Linux. Le passage d’une version à la suivante d’une même distribution se fait sans reformatage, mais si on fait un changement de distribution, rien n’est assuré !
La commande pour créer un répertoire est « mkdir » pour MaKe DIRectory (un raccourci -alias- existe souvent : md). Pour créer un répertoire bidon dans /home, on peut faire « md /home/bidon » (on peut le faire aussi bien en relatif qu’en absolu). « md bidon » créera un répertoire bidon à l’endroit où nous sommes en ce moment, cette commande fera ce qu’on souhaite si on était dans /home.
Maintenant, on veut créer un répertoire vide dans le répertoire bidon, on peut faire « md /home/bidon/vide ». Cette commande tapée sans avoir auparavant créé le répertoire /home/bidon aurait donné une erreur : « mkdir: Ne peut créer le répertoire `/home/bidon/vide': No such file or directory ».
La commande pour effacer un répertoire est « rmdir » pour ReMove DRIectory (un alias existe souvent : rd). Maintenant, on veut effacer le répertoire /home/bidon et ce qu’il contient. Pour pouvoir effacer avec « rd » un répertoire, il faut qu’il soit vide, c’est-à-dire que si on fait « rd /home/bidon », on obtient le message suivant : « rmdir: `/home/bidon': Directory not empty ». Il nous faudra donc faire avant « rd /home/bidon/vide ». Il y a une méthode risquée pour éviter ça qu’on verra plus tard.
Encore la touche tabulation : taper « rmd » + tabulation. Vous allez avoir « rmdir » qui s’affiche car c’est la seule commande qui commence par rmd.
Pour copier (dupliquer) un fichier la commande de base est « cp » pour CoPy. cp fichier_origine fichier_arrivée.
Revenons dans le répertoire /home/root. Si nous voulons copier le fichier bashrc dans le fichier .bashrc (caché, car il a un point devant) on fait « cp bashrc .bashrc ». Si on avait voulu copier directement ce fichier dans le répertoire /home/mclaires, on aurait pu faire directement « cp bashrc ../mclaires/.bashrc » en relatif ou « cp bashrc /home/mclaires/.bashrc » en absolu. On peut faire la même chose sans mettre de nom, mais juste un chemin vers un autre répertoire. Ceci duplique le fichier dans le répertoire cible sans changer le nom : « cp bashrc ../bs » copie le fichier dans le répertoire /home/bs sans changer son nom.
Cette fois, allons dans le répertoire /home/mclaires/projets « cd ../mclaires/projets ». D’ici rapatrions le fichier XF86Config-4.s_travail qui se trouve dans le répertoire /home/root. Nous pouvons faire soit « cp ../../root/XF86Config-4.s_travail . » ou « cp /home/root/XF86Config-4.s_travail . » Vous avez remarqué, j’espère la présence du « . » à la fin des commandes, celui-ci indique le répertoire courant.
Unix dispose d’une commande équivalente pour déplacer un fichier (MoVe), c'est « mv ». Elle marche comme cp, mais l'original sera effacé et il n’existera plus que la copie. Cette fois, on peut aussi bouger une arborescence complète : « mv /home/bs1 /home/root » créera le répertoire bs1 dans /home/root et y mettra toutes les données du répertoire /home/bs1 si le répertoire /home/root existe, sinon cette commande renomme le répertoire bs1 en root.
Je peux profiter de ces commandes pour vous parler de caractères jokers :
« * » : Caractère générique qui est équivalent à n’importe quelle chaîne de caractères (y compris les points (" . ") et aucun caractère.
« ? » lui est équivalent à n’importe quel caractère (unique)
« [ ] » signifie n’importe quel caractère compris entre les crochets ( [aeiouy] sera valable pour tout mot comportant au moins une voyelle)
Par exemple, « cp * destination » copie tous les fichiers vers la destination et « cp deb* destination » copie tous les fichiers qui commence par deb vers le répertoire destination. Une astuce : pour vérifier ce qui sera copié, vous auriez pu taper tabulation avant de taper le « * », ceci vous affichera tous les fichiers qui seront bougés. « * » est compris par presque toutes les commandes.
Pour effacer un fichier, la commande est « rm ». On efface un fichier avec « rm nom_du_fichier ». Cette commande est souvent modifiée par un alias qui oblige la demande de confirmation pour chaque effacement (alias rm='rm -i'). Pour éviter cela, on peut utiliser « rm -f », mais c'est dangereux.
Encore plus dangereux, il y a « rm -f -r * » qui efface tout à partir de l'emplacement actuel en parcourant les sous-répertoires. Ceci aurait pu nous être utile pour effacer le répertoire bidon quand il avait encore le répertoire vide : « rm -r -f /home/bidon ». Ceci est d’autant plus dangereux que si on fait « rm -f -r * » sur la racine avec les droits administrateur, on efface toutes les données! Peut-être pas celle qui sont sur d'autres ordinateurs suivant comment ont été définis les partages car l'administrateur de notre ordinateur n'est pas administrateur sur les autres ordinateurs a priori !
Revenons dans notre répertoire /home/root. Si nous voulons visualiser le fichier bashrc, nous pouvons faire « cat bashrc ». Mais si ce fichier est trop long, il est utile d'utiliser la commande « less bashrc » ou « more bashrc ». Dans ce dernier cas, on parcourt le fichier avec les touches flèche vers le haut/vers le bas (comme les touches j et k) et/ou page suivante/page précédente. On dispose de la touche h pour faire afficher une aide et on sort avec la touche q.
Parfois il est aussi utile de modifier en ligne de commande un fichier. Les deux éditeurs principaux en ligne de commande sont « vi » et « emacs ». Les férus d’Unix qui ont appris à utiliser ces éditeurs avant l’existence des modes graphiques vous diront qu’ils sont plus puissants que n’importe quel éditeur graphique. Je pense qu’ils ont raison, mais je ne les maîtrise pas assez pour en profiter ! Je vous indiquerais donc les commandes utiles de vi (le seul que je suis arrivé à utiliser). En mode graphique, vous avez par exemple kwrite.
Nous allons donc chercher à modifier le fichier bashrc : « vi bashrc ». Pour se déplacer dans le fichier, vous avez soit les touches h,j,k et l (très utile avant l'apparition des claviers avec pavé numérique : les flèches et les chiffres), soit les flèches. Pour avoir une aide tapez « :h » pour en sortir « :q ». Pour insérer du texte, allez où vous voulez insérer le texte, puis, tapez « i » (ou « a » pour aller après), après tapez « échappe » (touche escape, ESC ou Echap en haut à gauche). Pour effacer le texte, en mode insertion avec les nouvelles versions, vous pouvez utiliser les touches supprime et backup de votre clavier. En revanche si vous n’êtes pas en mode insertion, vous pouvez commencer à goutter la force de vi : « 10 x » effacera 10 caractères à partir du curseur et s'arrêtera à la fin de la ligne. « 5 dd » effacera 5 lignes. « x » seul effacera une lettre et « dd » une ligne. « u » (undo) annulera les précédentes commandes. Pour sauver taper « :w ». vi refusera de se fermer avec « :q » si les dernières modifications n’ont pas été sauvées : « :q! » pour sortir sans sauver et « :wq » pour sauvegarder et quitter. Ceci est une « sous-utilisation » de vi, mais suffisante pour de petites utilisations.
Parfois, on n’a qu’un vi minimaliste installé, Il faut alors installer « vim » qui intègre par exemple la coloration syntaxique. Ceci se fait simplement sous Mageia avec « urpmi vim ».
Les liens se font avec la commande « ln ».
Allons encore une fois sur notre répertoire /home/root et créons un répertoire liens.
Nous allons pouvoir tester les différents liens avec les trois fichiers dont nous disposons dans ce répertoire : bashrc, .bashrc et XF86Config-4.s_travail.
Commençons par créer un lien matériel : « ln .bashrc surprise ». Si on regarde le répertoire, « ll », on voit nos 4 fichiers sans distinction entre les 4, si ce n’est que le chiffre de la seconde colonne est 2 pour .bashrc surprise, alors que pour les autres il n’est que de 1 : le nombre de liens physiques. Modifions avec vi le fichier surprise. On rajoute une première ligne par exemple. Regardons ensuite le fichier .bashrc « less .bashrc » : nous y voyons notre modification. Ensuite, on efface .bashrc « rm .bashrc » et on regarde le contenu du répertoire « ls ». Nous avons quatre fichiers bashrc, surprise, surprise~ et XF86Config-4.s_travail. surprise~ est la sauvegarde faîte par vi de notre fichier avant la dernière sauvegarde, on l’efface « rm surprise~ » Il est possible de vérifier notre fichier surprise. Pour finir avec les liens physiques, essayons à partir du répertoire /home/root de faire un lien physique vers un fichier se trouvant à /root. « ln /root/.bashrc baba » et le système répond : « ln: création d'un lien direct `baba' vers `/root/.bashrc': Invalid cross-device link ». Ceci est normal car /root est dans une autre partition !
Continuons par un lien physique « ln -s surprise .bashrc » et regardons le contenu de notre répertoire « ls ». Nous voyons que .bashrc s'affiche différemment : il a au moins un @ dernière le nom. Si on modifie .bashrc avec vi la modification apparaît aussi sur le fichier surprise. Maintenant on efface surprise et on liste le répertoire « ll ». L'affichage de .bashrc a changé : maintenant il clignote car il est relié à un fichier inexistant! Essayons de résoudre le problème en faisant « cp bashrc surprise » et « ll » : tout est revenu dans l'ordre. Pour aller plus loin vous pouvez tester un lien (les 2 sortes) sur un lien symbolique et comprendre ce qui se passe.
Il est même possible de créer un lien vers un répertoire, mais uniquement un lien symbolique.
Je conclurai que ces commandes sont très pratiques et rapide. La ligne de commande est un peu austère mais très rapide. Un expert de script bash m’a dit que tout était dans « man bash »...
Je conseillerais aussi d’éviter les noms avec des espaces très facilement faisables en mode graphique car en ligne de commande l'espace devient '\' + espace. Au lieu de mettre un espace dans un nom essayer de mettre un « _ » (souligné).
Un autre intérêt de la ligne de commande est l’intervention à distance sur des systèmes lointains. Quand on prend la main en passant par internet sur un PC, parfois les applications graphiques passent mal à cause du débit, ou parce que le système à partir duquel on prend ma main ne gère pas les applications graphiques linux distantes, par exemple si vous êtes sur un poste sous windows où sur un téléphone portable avec android.
http://abs.traduc.org/index.html
Voici un exemple très simple de script bash à placer dans un fichier :
#!/bin/bash
echo -n "password: "
read pass
echo "Votre pass est $pass"
La première ligne #!/bin/bash sert à indiquer le type de shell à utiliser avec le script.
La deuxième ligne echo -n "password: " sert à afficher à l’écran le texte entre guillemet. L’option -n évite un retour à la ligne automatique.
La troisième ligne read pass va lire ce que l’utilisateur tape au clavier et le sauver dans la variable $pass. Du fait de l’option -n, ce que tape l’utilisateur apparaîtra à la suite du mot password.
La dernière ligne affiche à l’écran la phrase « Votre pass est » ainsi que le contenu de la variable $pass.
Une fois ces lignes sauvegardées dans un fichier monscript.sh par exemple, vous pouvez le rendre exécutable en tapant: chmod a+x monscript.sh puis en tapant uniquement le nom de votre fichier dans le shell précédé de ./: ./monscript.sh . On pourrait exécuter ce script sans la rendre exécutable en faisant : « bash monscript.sh »
Le ./ permet d’indiquer que le fichier monscript.sh se trouve dans le répertoire courant.
Voir man chmod et man chown pour apprendre plus de ces deux fonctions très utiles.
Il est également possible de taper ce script en ligne de commande en séparant chaque fonction par un point virgule :
echo -n "password: " ; read pass ; echo "Votre pass est $pass"
Il est possible d'utiliser le bash comme une calculatrice. En ligne de commande, voilà ce que cela donne:
echo $[ 4 * 2 ]
8
echo $[ 10 + 5 ]
15
ou parfois
echo $(( 10 + 5 ))
15
Voici un exemple de comparaison utilisant les tests conditionnels « if »
#!/bin/bash
echo -n "entrez un nom: "
read var1
echo -n "entrez un autre nom: "
read var2
if [ "$var1" = "$var2" ]; then
echo "Les noms sont les mêmes"
else
echo "Les noms sont différents"
fi
exit 0
"fi" est la fermeture de if, tout comme "}" est la fermeture de "{", exit 0 termine le script proprement et vous ramène au prompt.À la place de '=' vous pouvez utiliser '-eq' pour tester si deux expressions sont équivalentes, ou '-eg' pour vérifier si deux entiers sont égaux.
À noter qu’une variable '$var' peut être écrite ${var}.
if test -f $1
then
file $1
else
echo "Le fichier \"$1\" n'existe pas"
fi
Dans le script suivant, $1 renvoie le premier argument entré après le programme ou la fonction à l'exécution. -f renvoie vrai si le fichier (stocké dans $1) existe.
Voici quelques fonctions de test utiles :
Expression Signification
-r fichier vrai si le fichier existe et est accessible en lecture (r)
-w fichier vrai si le fichier existe et est accessible en écriture (w)
-x fichier vrai si le fichier existe et est exécutable (x)
-f fichier vrai si le fichier existe et est un fichier "régulier" (file)
-d fichier vrai si le "fichier" existe et est un répertoire (directory)
-s fichier vrai si le fichier existe et a une taille non nulle (size)
c1 = c2 vrai si les deux expressions sont égales (des chaînes, en sh)
c1 != c2 vrai si les deux expressions sont différentes (des chaînes, en sh)
c1 vrai si c1 n’est pas la chaîne nulle (vide)
e1 -eq e2 vrai si les deux entiers e1 et e2 sont algébriquement égaux (equal)
e1 -ne e2 vrai si les deux entiers e1 et e2 sont algébriquement différents (not equal)
e1 -gt e2 vrai si l'entier e1 est plus grand que l'entier e2 (greater than)
e1 -lt e2 vrai si l'entier e1 est plus petit que e2 (lower than)
! expr négation de l’expression booléenne expr
expr1 -a expr2 et logique entre les deux expressions booléennes expr1 et expr2 (and)
expr1 -o expr2 ou logique entre les deux expressions booléennes expr1 et expr2 (or)
Séparateurs/contrôles en shell:
| pipe prendra la première commande en argument de la seconde.
|| OR si la première commande est fausse, il prendra la seconde.
|= OR IS (surtout utilisée dans les tests conditionnels "if").
&& AND si la première commande est vraie, il exécutera la seconde.
! NOT (surtout utilisée dans les tests et tests conditionnels "if"), mais utilisé en commande shell, il ouvre un shell pour lancer une commande (ex. `! echo foo`).
!= NOT IS (surtout utilisée pour les tests conditionnels).
!$ dernières commandes, dernier argument.
!! répète la dernière commande.
= IS (surtout utilisé pour les tests conditionnels).
; séparera 2 commandes comme si elles étaient écrites sur 2 lignes.
;; fin d’une fonction `case` (voir `case` plus loin).
$ préfixe d’une variable comme "$myvar".
$! PID du dernier processus enfant.
$$ PID du process courant (PID == Process ID).
$0 Montre les programmes possesseurs du processus courant.
$1 Premier argument entré après le programme ou la fonction à l'exécution.
$2 Second argument entré après le programme ou la fonction ($3 etc.).
$# Affiche le nombre d'arguments.
$? N'importe quel argument (bon à utiliser dans les tests conditionnels).
$- flags de l’option courante (Je n’ai jamais eu à m’en servir).
$_ Dernier(ère) argument (commande).
$* Tous les arguments.
$@ Tous les arguments.
# ligne de commentaire, tout ce qui suit sur la ligne n’est pas interprété.
{ accolade ouvrante (début de fonction).
} accolade fermante (fin de fonction).
[ crochet ouvrant (pour des arguments multiples).
] crochet fermant (pour des arguments multiples).
@ $@ est équivalent à "$1" "$2" etc. (tous les arguments).
* wildcard (* remplace un nombre indéterminé de caractères).
? wildcard (? remplace un unique caractère).
" quote
' quote précis (inclura même des " dans le quote).
` quote de commande (variable=`ls -la` affichera le contenu du répertoire en utilisant $variable).
. le point lira et exécutera des commandes à partir de fichiers (. .bashrc).
& and. utilisé en suffixe, il exécute une tâche en background (./program &).
0< stdin stream director (Je ne l’ai vu dans aucun script).
1> stdout stream director (standard output)
2> stderr stream director (standard error output)
% caractère des tâches, %1 = fg job 1, %2 = fg job 2, etc.
>> stream director (inclusion dans un fichier).
<< stdin stream director. (cat > file << EOF ; anything ; EOF)
> stream director qui commencera au tout début du fichier (dans les tests conditionnels "if" < et > seront utilisés en comparateurs mathématiques par exemple: if [ "$1" >= "2" ])
\ back-slash, retire le méta-caractère de n'importe quelle chaîne. Ainsi, \$var ne sera pas traité comme une variable. (et une nouvelle ligne ne sera pas traitée comme une nouvelle ligne) De plus, un \ avant une commande, retire tous les aliases appliqués à cette commande: \rm>& stream director to stream director, ie. echo "a" 1>/dev/null 2>&1 dirigera 2> au même endroit que 1>
case, tout comme if, se termine par la commande inversée esac.
#!/bin/bash
case "$1" in
--help)
echo "Aide..."
;;
--version)
echo "Version 1.0"
;;
esac
Dans cet exemple, si l’argument $1 est '--help', « Aide… » est affiché, si $1 est égale à '--version' etc.
Chaque condition se termine par ;;
sed est utilisé pour formater/modifier du texte.
Par exemple, si vous possédez un fichier tmp contenant des urls et que vous désiriez changer tous les www par ftp, tapez :
sed 's/www/ftp/g' tmp
et sed 's/www/ftp/g' tmp > tmp2 si vous désirez enregistrer les modifications dans un fichier tmp2.
sed -n 3 p tmp2 permet d’afficher la 3ème ligne du fichier tmp2.
La fonction more (comme la fonction less) peut être utilisée pour lire des fichiers
more -8 fichier1
affiche le contenu du fichier fichier1 8 lignes par 8 lignes (barre d’espace pour les 8 suivantes, return pour une ligne suivante, q pour quitter).
Ce système au cours du début des années 2010 remplace petit à petit 'system V init'. Il gère les démons et permet surtout de passer d’un démarrage séquentiel des démons à un démarrage parallèle : on indique à un démon quels démons doivent être actifs pour qu’il puisse lui aussi se lancer.
Source : http://lea-linux.org/documentations/Systemd ou https://doc.ubuntu-fr.org/systemd
Pour lancer/arrêter/vérifier un démon on fait : systemctl (re)start/stop/status nom_du_demon . Si on a la complétion installée (urpmi bash-completion sous mageia), on peut compléter avec la touche tabulation aussi bien (re)start/stop/status que le nom du démon.
Pour avoir la liste des dépendances d’un démon, sshd par exemple, on peut lancer : systemctl list-dependencies sshd. Si l’auto-complétion est installée systemctl + tabulation et on a tout ce qui est possible.
Les actions les plus courantes sont :
start : démarrer le service
stop : arrêter le service
restart : relancer le service
reload : recharger le service
status : connaître l’état du service
Quelle que soit l’action menée sur un service, au prochain démarrage de la machine celui-ci devrait retrouver le status qui lui a été défini par défaut.
Pour obtenir la liste triée des services accompagnés de leur état, saisissez dans un terminal :
systemctl list-unit-files | grep service | sort
Vous pouvez également obtenir la liste des services lancés au démarrage, triés selon leur temps d’exécution :
systemd-analyze blame
Cela peut être pratique pour trouver le service qui ralentit votre démarrage.
Pour désactiver un service, il faut taper :
systemctl disable <Nom_du_service>.service
Ainsi, au prochain redémarrage du système, le service correspondant ne sera plus lancé.
Pour activer un service (c’est-à-dire le lancer à chaque démarrage de l’ordinateur) ou relire son fichier de configuration, il faut taper :
systemctl enable <Nom_du_service>.service
Néanmoins si vous souhaitez modifier l’état d’un service selon certaines conditions, vous devrez modifier ou créer /etc/systemd/system/<nom_du_service>.service. Les fichiers de configuration par défaut se trouvent dans /lib/systemd/system/
Il faut mettre un fichier /etc/systemd/system/firewall.service du type :
[Unit]
Description=Gestion des règles Iptables et du service de passerelle
After=network.target auditd.service sshd.service
[Service]
Type=simple
User=root
Group=root
UMask=007
ExecStart=/etc/init.d/firewall start
[Install]
WantedBy=multi-user.target
#Alias=firewall.service
Et indiquer au début du fichier /etc/init.d/firewall quand il doit faire quoi :
#!/bin/sh
### BEGIN INIT INFO
# Provides: scriptname
# Required-Start: $remote_fs $syslog
# Required-Stop: $remote_fs $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start daemon at boot time
# Description: Enable service provided by daemon.
### END INIT INFO
# ATTENTION la ligne du dessus
# n'est pas un commentaire
Et finalement activer le service :
systemctl enable firewall.service
Le 'system V init', qui était l’init le plus utilisé pour Linux dans les années 2000. Les startup scripts permettent de lancer/stopper les services tels que serveur http, ftp, base de données postgresql etc. et ils sont écrits en bash ! Ils sont stockés dans :
/etc/rc.d/rc0.d/
/etc/rc.d/rc1.d/
/etc/rc.d/rc2.d/
/etc/rc.d/rc3.d/
/etc/rc.d/rc4.d/
/etc/rc.d/rc5.d/
/etc/rc.d/rc6.d/
/etc/rc.d/init.d/
Régulièrement dans les 7 premiers répertoires, nous avons des liens symboliques vers les scripts qui sont dans le dernier. Le rôle des 7 premiers répertoires est indiqué dans /etc/inittab.
Voici un script permettant de démarrer un démon nommé daemon :
#!/bin/sh
# example Exemple de script qui lancerait 'daemon'
#
# Version: @(#) /etc/rc.d/inet.d/example 0.01 19-Feb-2001
#
# Author: Billy (Alien), <alien@ktv.koping.se>
#
. /etc/rc.d/init.d/functions
function status() {
ps aux | grep daemon &&
echo "Daemon is running." ||
echo "Daemon is not running."
}
case "$1" in
start)
# Vérifie si daemon est dans notre path.
if `which daemon` > /dev/null; then success || failure; fi
echo -n "Starting Daemon"
daemon
echo
;;
stop)
# Vérifie encore si daemon est dans notre path.
if `which daemon` > /dev/null; then success || failure; fi
echo "Stopping Daemon"
killall -15 daemon
;;
status)
echo "Status of Daemon:"
status
;;
reload)
echo "Restarting Daemon."
killall -1 daemon
;;
restart)
if `which echo` > /dev/null; then success || failure; fi
$0 stop
$0 start
;;
*)
echo "Usage: $0 start|stop|restart|status"
exit 0
esac
alors à vous de lire les scripts de votre système et d’essayer de les comprendre ;-)
Ceci est dépendant de l’environnement graphique choisi (WM). Pour trouver votre bonheur, parcourez les menus ! Souvent il existe un raccourci du nom de « Dossier personnel », il vous ouvrira un gestionnaire de fichiers « drag and drop ». En cliquant sur un fichier ou un répertoire, l’action automatiquement configurée se passe. Pour faire plus de chose, essayez de cliquer avec le bouton droit et de parcourir les menus... Tout doit être faisable, mais pas aussi facilement. Certes les manipulations courantes comme copier-coller sont très simplifiées.
http://www.lea-linux.org/admin/shell.php3
voici les commandes de base sous Linux :
Commandes linux |
équivalent MsDos |
à quoi ça sert |
Exemples : |
|
cd |
change le répertoire courant. |
|
ls |
dir |
affiche le contenu d'un répertoire |
|
|
|
copie un ou plusieurs fichiers |
|
rm |
|
efface un ou plusieurs fichiers |
|
rm -rf |
|
efface un répertoire et son contenu |
|
|
md |
crée un répertoire |
|
rmdir |
|
efface un répertoire s'il est vide |
|
|
|
déplace ou renomme un ou des fichiers |
|
|
dir -s |
trouve un fichier répondant à certains critères |
|
|
|
trouve un fichier d'après son nom |
|
man |
|
affiche l'aide concernant une commande particulière |
|
|
attrib |
modifie les permissions d'un fichier |
|
chown |
pas d'équi-valent |
modifie le propriétaire d'un fichier |
|
|
pas d'équi-valent |
modifie le groupe proprétaire d'un fichier |
|
|
pas |
crée un lien vers un fichier |
|
|
pas d'équi-valent |
recherche une chaine dans un fichier (en fait recherche une expression régulière dans plusieurs fichiers) |
|
which |
pas d'équi-valent |
trouve le répertoire dans lequel se trouve une commande |
|
cat |
type |
affiche un fichier à l'écran |
|
Remarque :
Pour en savoir plus
sur toutes ces commandes, je vous conseille de consulter leur page de
man !
Voir aussi :
http://abs.traduc.org/index.html
Il existe plusieurs manières d’installer la distribution Mageia ( https://www.mageialinux-online.org/wiki/installer-mageia ). La plus courante est l'installation à partir des DVD de base dont on peut copier l’iso sur une clef USB ( https://www.mageialinux-online.org/wiki/creation-facile-d-une-cle-usb-bootable )si on ne souhaite/peut pas utiliser un DVD. Avec l’installation simple, on a le système d’exploitation avec plusieurs WM disponibles (windows n’apporte qu’un choix), la suite libreoffice (le DVD de MS Office), des logiciels de dessins, des logiciels de gravures, des jeux…
Pour le partitionnement, il faut obligatoirement avoir une partition / (racine du système), une partition swap (que le système utilise pour stocker des données utiles qui encombrent la RAM). Il est conseillé d’avoir la partition /home où sont stockées les données personnelles (les répertoires personnels) des utilisateurs, (que rien n’empêche de nommer /maison !) afin qu’elles échappent à d’éventuels reformatage du système (répertoire /). Vous allez laisser intactes les éventuelles partitions windows (ou autres ?) déjà présentes. Si vous avez un windows d’installé il sera intéressant de prévoir une partition FAT32 pour simplifier les échanges de données d’un système à l’autre.
Nous choisirons l’installation en mode expert. Nous allons installer :
Les environnements graphiques (tous pour tester).
les serveurs suivants : ftp, ssh, httpd, nfs.
Les outils de configuration.
firefox (butineur internet).
LibreOffice pour lire l’original de ce document.
Pour avoir une telle précision, il faudra sélectionner les paquets à la main.
Il faudra configurer l'amorçage (grub) pour bien booter sur la bonne partition.
Les fenêtres de dialogues sont en général bien faîtes.
Booter simplement sur le média contenant l’image de la distribution.
Sur chaque PC, vous allez créer un seul compte : le compte root (obligatoire) avec comme mot de passe linux. Pour le compte suivant, ne pas rentrer de données, et faire directement [Accepter] afin d’être sûr de ne pas le créer.
Il vous faudra aussi le réseau : vous vous mettez en DHCP et surtout lors de la configuration réseau, choisissez le mode expert et cocher lors de la configuration de la carte réseau « ne pas affecter le nom d’hôte à partir de l’adresse DHCP, mais donner vous-même le nom du PC.
Il faudra aussi configurer l'affichage.
Pour le moment, surtout, on ne met pas de fire-wall.
Après ceci, vous rebootez la machine. Laissez tomber la mise à jour, elle peut être très longue (on n’aura pas le temps à ce moment), elle est pourtant très importante pour la sécurité !
Avec Mageia, on peut lancer un exécutable : mcc (centre de contrôle Mageia) qui fait beaucoup de choses. Il est même disponible en partie en dehors de tout environnement graphique, mais sa version graphique est bien plus avantageuse. Il peut configurer presque tout, mais pour avoir plus de précision, rien ne vaut le travail manuel des fichiers de configuration. Nous allons aussi bien travailler en ligne de commande qu’avec des interfaces graphiques, chaque mode ayant son avantage en fonction du travail à effectuer et de notre connaissance de l’OS.
Pour permettre à de nombreux utilisateurs de travailler sur la même machine, Unix met en œuvre des mécanismes d’identification des utilisateurs, de protection et de confidentialité de l'information, tout en permettant le partage contrôlé nécessaire au travail en groupe. Tout utilisateur est identifié par son nom (login) et ne peut utiliser le système que si son nom (login) a préalablement été défini par l’administrateur du système (root ou super-utilisateur) qui lui donnera en même temps des droits. La définition d’un nouvel utilisateur s’appelle aussi créer un compte.
root a tous les droits et aucune restriction ne lui est applicable. Travailler en tant qu’administrateur (se loger sous root) est donc dangereux, mais utile pour paramétrer le système.
La première question à se poser c’est que doit avoir chaque compte ?
Un compte doit avoir des données personnelles et un endroit propre pour les laisser. On crée donc un répertoire personnel à chaque utilisateur. Ce répertoire est régulièrement placé dans /home : /home/repertoire_personnel. Sa création est normalement automatique.
Les fichiers spécifiques sont (source : « man useradd ») :
- /etc/passwd - information sur les comptes utilisateurs
- /etc/shadow - information sécurisée sur les comptes utilisateurs
- /etc/group - information de groupes
- /etc/default/useradd - information par défaut modifiée avec « useradd -D »
- /etc/login.defs - réglages globaux du système
- /etc/skel - répertoire contenant les fichiers qui seront mis par défaut dans les comptes personnels lors de leur création.
Ce répertoire contient plusieurs fichiers cachés, afin de voir tout son contenu, faire « ll -a /etc/skel ». Un des fichiers caché est .bashrc qui contient la configuration du bash (ligne de commande) de l'utilisateur.
nb : Il se peut que votre .bashrc ne se lance pas en vous loguant sur une console texte. Dans ce cas, il faut rajouter dans ~/.bash_profile les lignes suivantes :
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
BASH_ENV=~./bashrc
export BASH_ENV
Le premier test et lancement permet lors du login d'exécuter le .bashrc s'il existe, en effet le bash ne tiens pas compte de la variable BASH_ENV ou moment du login sous X (environnement graphique)(contre toute attente d’ailleurs).
La variable BASH_ENV indique à bash de reexécuter .bashrc à chaque nouveau shell.
Normalementiv, vous ne pouvez pas vous loger sur un Windows Manager, car vous n’avez que root comme utilisateur et que pour des raisons de sécurité évidente Mandriva interdit l’utilisation d’un WM sous root car toutes les applications pourraient alors écrire n’importe où ce qui ouvrirait la porte à tous les virus (il est faisable de lancer des applications windows sous LINUX...)
Vous allez donc utiliser un shell, ceci est toujours faisable et fort utile. On dispose en effet de 7 terminaux, on passe d’un à l’autre en faisant Ctrl-Alt-FX (les 3 touches appuyées simultanément) où X est entre 1 et 7. Ctrl-Alt-F7 est le terminal du windows manager, vous allez donc faire un des 6 autres, Ctrl-Alt-F2 par exemple. Ctrl-Alt-F1 est parfois « décoré » par Mandriva ce qui diminue la taille de la fenêtre.
Vous allez utiliser la commande « useradd » (ou « adduser »). Pour avoir plus d'information, faîtes « man adduser ». Nous n’allons pas utiliser toutes les options disponibles! Si nous faisons « useradd nom_de_l_utilisateur » tout se fait correctement car le fichier /etc/login.defs est configuré pour. En plus, cette instruction créera automatiquement un répertoire personnel dont le contenu sera la copie du répertoire /etc/skel comme c’est normalement défini dans le fichier /etc/default/useradd.
Créez-vous votre compte personnel avec comme id 1000+n°_de_votre_pc (il faudra ajouter une option à la ligne que je vous ai indiqué au chapitre précédent). Les autres comptes que vous créerez sur votre ordinateur auront un id du style X00+n°_de_votre_pc avec X>10.
Les utilisateurs sont stockés dans le fichier /etc/passwd. Ce fichier a une ligne par utilisateur. Chaque ligne contient des champs séparés par des « : » (doubles points).
Le premier champ contient le nom,
le second un x (activer protégé), une * (désactivé) ou rien (compte sans mot de passe : une faille de sécurité),
le troisième l’identificateur de l'utilisateur (son id : un numéro supérieur à 500 pour un utilisateur non système),
le suivant d’id de son groupe principal,
l’antépénultième un commentaire sur l’utilisateur, l’avant-dernier l’emplacement de son répertoire personnel (qui peut donc être vraiment quelconque)
le dernier le shell qu’on lui attribue (il existe par exemple des shells qui empêchent à l’utilisateur de se loger, ceci peut permettre à un compte de ne pouvoir faire que du ftp).
Pour enlever un utilisateur, faîtes « userdel utilisateur ».
Pour changer les paramètres d’un utilisateur, utilisez « usermod ». Après avoir lu « man usermod », définissez-vous un mot de passe, car la commande « useradd » ne l’a pas fait puisque vous ne lui avez pas demandé !
Ajoutez un groupe essai avec la commande « groupadd essai ».
Les groupes sont stockés dans le fichier /etc/group qui a la même structure que le fichier /etc/password. Les informations sur chaque ligne sont dans l’ordre : le nom du groupe, un second champ qui peut contenir soit un x, un * ou rien, un troisième d’identification du groupe (son id), le dernier champ est la liste des utilisateurs (nom complet) qui appartiennent à ce groupe sans que ce soit leur groupe principal, l'information du groupe principal étant dans le fichier password.
Ajoutez manuellement, avec vi, dans le groupe essai votre compte personnel.
Après avoir créé un compte, faîtes Ctrl-Alt-F7. Loger vous avec le compte juste créé avec un environnement graphique pris au hasard (débrouillez-vous pour ne pas avoir le même que vos voisins).
Pour enlever un groupe, utiliser « groupdel ».
Pour mettre un utilisateur dans un groupe : « addgroup <utilisateur> <group> »
L’appartenance au groupe n’apparait pour la session complète que après s’être déloggué puis reloggué. On peut utiliser "newgrp" ou "sg" pour éviter de se déloguer et récupérer l’appartenance au bon groupe dans un sous-shell.
I
llustration
3 : menus mcc
Comme nous sommes sous Mageia autant utiliser les outils Mageia qui sont forts agréables et en français !
Nous avons le programme userdrake auquel nous pouvons accéder soit par mcc, soit directement.
Je profite de ceci pour
vous faire lancer ces programmes à partir d’une fenêtre shell
ouverte dans votre environnement graphique, souvent son icône, c’est
un écran d’ordinateur avec parfois une coquille (shell) devant
![]() .
.
Dans cette fenêtre taper la commande « su ». « su » est la commande qui permet de donner la main dans la fenêtre shell à un autre utilisateur qu’on met en paramètre, s’il n’y a pas de paramètre, ce sera le super-utilisateur (administrateur ou root). Le prompt vous demande alors un mot de passe, donnez le mot de passe root et vous avez un shell en administrateur. « su - » fait la même chose, mais en plus on récupère les paramètres du nouvel utilisateur. Ceci est à éviter si on fait cette manipulation pour récupérer un environnement planté.
À partir de ce shell, vous pouvez faire exécuter des applications graphiques sous root. Tapez par exemple « kwrite », vous ouvrez alors un éditeur de texte graphique, mais vous n’avez plus la main dans le shell. Pour retrouver la main simplement, vous devez arrêter kwrite, soit à partir de l'interface graphique, soit en faisant Ctrl-C sur le shell ( voir plus loin au IV) C) 2) a) ). Pour garder la main, il fallait faire « kwrite & » afin de lancer kwrite en mode arrière plan.
Vous allez donc taper
« mcc
& ». Parcourez les menus (image à gauche) et
choisissez UserDrake (icône à droite)
![]()
Dans cette interface vous devez voir que vous appartenez aussi au groupe essai. Vous pouvez créer, supprimer et éditer des comptes. Cette dernière option est bien intéressante, car elle permet entre autre de modifier les groupes d’appartenance des utilisateurs. Vous pouvez aussi choisir dans option « voir les groupes » et faire des modifications sur les groupes.
Les droits sur un fichier/répertoire sont (dans l’ordre) lecture (r)-écriture(w)-exécution(x). Ses droits, sont attribués dans l’ordre à l’utilisateur propriétaire du fichier, au groupe propriétaire du fichier et à tous. Ceci fait 9 cases à remplir, si on permet tout : « rwxrwxrwx ». Si on permet tous à l'utilisateur, la lecture et l’exécution au groupe et l’exécution à tous, ceci donne : « rwxr-x--x », le '-' (moins) signifie que le droit n’est pas accordé ! On fait correspondre des valeurs à ces droits : le r vaut 4=22, le w vaut 2=21 et le x vaut 1=20. Ceci donne comme valeur pour le premier 777 (écriture en Octal – base 8), le second 751. 640 correspond à « rw-r----- ».
Les droits dépendants étant lié au propriétaire et au groupe propriétaire, il faut donc parfois modifier ces paramètres. Pour modifier le groupe, on fait « chgrp groupe f1 » où f1 est un fichier ou un répertoire. Pour modifier le propriétaire, il faut faire « chown user f1 ». Si on veut modifier les deux, il faut faire « chown user:groupe f1 » ou « chown user.groupe f1 ». Ces manipulations se font sans problème si on est root. En revanche, quand on est simple utilisateur, il faut que le fichier nous appartienne, on ne peut pas changer le propriétaire et on ne peut donner un nouveau groupe que si on fait partie de ce nouveau groupe.
Ces droits se changent avec la fonction « chmod » : « chmod valeur_du_mode fichier ». Pour donner les droits rw-rw-r-- au fichier bashrc du répertoire /home/root, il faut faire « chmod 664 /home/root/bashrc ». Ceci permettra au propriétaire et à son groupe (root) de le lire et de le modifier et aux autres de le lire.
Il y a aussi la possibilité d’enlever ou de rajouter des droits à des fichiers avec « chmod [who]op[permission] ». who est une combinaison de u(user ou propriétaire), g (groupe) ou o (other ou autre). op est soit + pour ajouter le droit, - pour l’enlever et = pour ne donner que celui-là (les autres seront mis à 0=non). « chmod go-w fichier » supprime le droit d'écriture au groupe et aux autres. « chmod u+x fichier » rajoute au propriétaire le droit d’exécution (transforme le fichier en exécutable !). « chmod ug=r » donne un accès en écriture uniquement à son propriétaire et au groupe.
Attention : pour effacer un fichier, il suffit d’avoir le droit sur le répertoire et le droit de lecture sur le fichier…
La possibilité intéressante de chmod, mais qui peut ouvrir des failles est « chmod +s fichier » qui fait utiliser l’id du propriétaire ou du groupe propriétaire du fichier lors de l’exécution. La faille arrive quand le propriétaire du fichier est root car lors de l'exécution du fichier, on récupère les droits de root!
En plus de ces 9 données, Unix définit trois autres données de permission : SUID*, SGID* et t (voir chapitre suivant). Ces données étant toutes binaires : non ou oui, 0 ou 1, peuvent chacune être stockées sur un bit. Ceci fait donc 12 bits de permission. On les obtient en faisant « chmod 01XXX » pour le sticky-bit en octale, « chmod 02XXX » pour SGID et « chmod 04XXX » pour SUID. Le 0 indique au système qu’on est en octale.
* : trop compliqués pour en parler dans ce document !
Les droits sont les mêmes avec les répertoires mais les effets sont un peu différents.
Pour rentrer dans un répertoire, il faut avoir le droit d’exécution dessus. Pour lire les données d’un répertoire, il faut avoir le droit de lecture et pour avoir le droit d’écrire dessus, il faut avoir le droit d’écriture et de lecture. En combinant ces droits sur un répertoire, on peut avoir des configurations assez intéressantes et surprenantes. Par exemple, une personne qui n'a que le droit d’exécution peut aller dans le répertoire « cd répertoire » mais ne peut pas y faire grand-chose, même pas lire le contenu du répertoire « ls », elle peut visualiser un fichier « cat » si elle sait qu’il y est. Une personne qui n’a que le droit de lecture ne peut se rendre sur le répertoire « cd répertoire », mais peut lire le contenu « ls répertoire ». Une personne qui n’a que le droit d’écriture ne peut rien faire a priori. Afin que le droit d’écriture soit utilisable, il faut au moins avoir les droits de lecture. Une personne qui a le droit de lecture et d’écriture sur un répertoire peut y déposer ce qu’elle veut et lire les fichiers sur ce répertoire que si elle est informée de son existence.
Avec les répertoires, on dispose de « chmod +t repertoire » (cette option modifie aussi l’attribut pour les fichiers, mais de nos jours il n’est plus utilisé). Cette manipulation permet à tous ceux qui ont le droit d’écrire dans ce répertoire de ne pouvoir modifier que les fichiers qui leur appartiennent.
Je vous conseille de faire quelques tests afin de mieux saisir les possibilités du système !
Créer dans votre répertoire personnel un répertoire où les visiteurs auront juste le droit d’écrire (poser) des fichiers et un autre où ils auront juste le droit de lire les fichiers.
Créer un répertoire « partage » où tout membre du groupe partage aura tous les droits. En revanche, on ne pourra modifier un fichier que s’il nous appartient. Attention, ce répertoire ne pourra être directement sur « /home » car Mageia empêche ce genre de partage sur ce répertoire pour des questions de sécurité. Je propose par exemple « /home/tous/partage ».
http://lea-linux.org/documentations/index.php/Gestion_des_ACL
Un processus est un programme, une tache qui tourne sur votre ordinateur. Comme c’est un système multi-tache, il peut en avoir beaucoup en même temps. Chaque processus est identifié par un numéro unique qui s’appelle le numéro d’identification du processus PID (Process Identifier) et qui lui est attribué par le système à sa création.
Ce sont les commandes principales qui permettent de gérer les processus.
La commande « ps » permet de visualiser tous les processus lancer depuis une fenêtre :
# ps
PID TTY TIME CMD
6897 pts/5 00:00:00 bash
7584 pts/5 00:00:00 ps
Ceci est le minimum. le processus ps lui-même et la fenêtre. Heureusement, il y a d'autres options, faîtes « ps --help » ou « man ps ». Pour tout bien voir, vous pouvez essayer « ps uawx -H ». Cette commande met en évidence la notion de processus père et processus fils avec la hiérarchisation de l’affichage à droite (l’option -H). Un processus fils est un processus qui a été créé par un autre processus qui prend le nom de processus père.
Vous allez dire qu’il y en a beaucoup ! Vous vouliez juste savoir si vous aviez des bash qui tournent, faîtes : « ps uawx | grep bash ». Par cette manipulation, j’ai introduit deux nouvelles notions : un tube (pipe) avec « | » et la fonction « grep ». Un tube envoie la sortie de la commande d’avant vers la commande suivante qui cette fois est « grep ». « grep » recherche dans les fichiers d’entrée indiqués (ici la sortie du ps) les lignes correspondant à un certain motif (ici bash). Il ne s’affichera donc que les lignes qui ont bash dedans.
« top » en ligne de commande affiche en temps réel et en mode texte, les processus selon l’ordre décroissant de charge CPU. On sort de ce mode en tapant 'q' au clavier.
Les commandes « kill » et « killall » permettent de tuer les processus. Elles sont très utiles par exemple lors des phases de test d'un programme (avec une boucle infinie par exemple).
Une utilisation simple est « kill -9 PID_du_processus » pour tuer un processus et « killall nom_d_un_processus » pour tuer tous les processus de ce nom. Bien sur, vous ne pouvez tuer que les processus vous appartenant. Seul root peut tuer n’importe quel processus.
Il existe 5 modes d’exécutions : le mode interactif (foreground), le mode en arrière plan (background ou asynchrone), le mode différé, le mode batch et le mode cyclique.
C’est le mode habituel de la ligne de commande : on lance l’exécution du programme et on attend qu’il se finisse. Ceci est très intéressant si le programme interagit en nous posant des questions sur ligne de commande.
On peut stopper un programme en faisant Ctrl-c (le tuer) ou le suspendre en faisant Ctrl-z. « bg » poursuit son exécution en arrière plan (background). « fg » poursuit son exécution au premier plan (foreground). Si on lance plusieurs programmes, on peut utiliser 'fg' et 'bg' avec un paramètre qui est le numéro du "job" listé par la commande « jobs ».
C’est le mode qui rend aussitôt le contrôle à l’utilisateur. Cette fonctionnalité est intéressante pour des tâches ne nécessitant pas d’interaction entre l’utilisateur et la tâche, par exemple kwrite. La commande est lancée suivie du caractère & : « kwrite & ».
Pour surveiller l’exécution de ces commandes, on dispose de « ps » ou « jobs ».
Cependant, les tâches de fond sont arrêtées dès que l’utilisateur ferme le shell. Pour assurer la pérennité de la commande, il faut la faire succéder par nohup : « nohup kwrite & ». Ce comportement peut être donné à tous programmes tournant en arrière plan si on fait « disown PID_du_programme », le PID étant donné par la commande « ps ».
La commande « wait » est là pour synchroniser des processus asynchrones. Elle fait attendre (bloque la main) que les processus lancés en tâche de fond dans cette fenêtre soient arrêtés.
L'exécution cyclique d’une tâche est réalisée à l'aide de la commande « crontab ». C’est est une commande qui vous permet d’exécuter des commandes à des intervalles de temps réguliers, avec l’avantage supplémentaire que vous n’avez pas à être connectés au système et que la sortie de ces commandes vous est envoyée par courrier électronique. « crontab » agira différemment en fonction des options :
-l : affiche votre fichier crontab courant
-e : édite votre fichier crontab (utilisation comme vi)
-r : élimine votre fichier crontab
-u <utilisateur> : applique les options ci-dessus à l’utilisateur <utilisateur>. Seul root est autorisé à faire cela.
Chaque ligne du fichier crontab est constitué de 6 champs séparés par un espace ou une tabulation. La signification des champs est respectivement la minute (0-59), l’heure (0-23), le jour du mois (1-31), le mois de l’année (1-12), le jour de la semaine (0-6, dimanche=0) et la tâche à exécuter.
C’est le démon (voir V)D) ) cron qui scrute les fichiers dans lesquels sont définies les commandes à exécuter. Ces fichiers sont dans /var/spool/cron pour tous les utilisateurs même le super-utilisateur. Mais il existe le fichier /etc/crontab :
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# run-parts
01 * * * * root nice -n 19 run-parts /etc/cron.hourly # exécute toutes les heures + 1 min le
# contenu du réperoire /etc/cron.hourly
02 4 * * * root nice -n 19 run-parts /etc/cron.daily # tous les jours à 4h02 /etc/cron.daily
22 4 * * 0 root nice -n 19 run-parts /etc/cron.weekly # tous les dimanche à 4h22
42 4 1 * * root nice -n 19 run-parts /etc/cron.monthly # les premiers du mois à 4h42
*/10 * * * * script # script exécuté toutes les 10 min
root peut donc mettre un fichier dans un de ces répertoires pour exécuter périodiquement une tache. On peut même rajouter un ligne qui commence par 5 astérix afin d’exécuter une tache toutes les minutes. Voici la structure d’un de ces fichiers :
#!/bin/sh => pour dire que c’est du bash
nice -n 19 ntpdate -u ntp1.tuxfamily.net # exécute ntpdate (mise à l'heure du PC) sans urgence
# voir « man ntpdate » et « nice »
Les fichiers /etc/cron.allow et /etc/cron.deny sont utilisés pour limiter l'accès à cron. Le format de ces deux fichiers de contrôle d’accès requiert un nom d'utilisateur sur chaque ligne. Les espaces blancs ne sont pas acceptés. Le démon cron (crond) n'a pas à être redémarré si les fichiers de contrôle d’accès sont modifiés. Ces derniers sont lus chaque fois qu’un utilisateur essaie d’ajouter ou de supprimer une tâche cron.
Si le fichier cron.allow existe, seuls les utilisateurs qui y sont répertoriés peuvent utiliser cron et le fichier cron.deny n'est pas pris en compte. En revanche, si le fichier cron.allow n’existe pas, les utilisateurs répertoriés dans cron.deny ne sont pas autorisés à utiliser cron.
Il existe aussi anacron (utilisable que par root ?) qui est un planificateur de tâches similaire à cron, sauf qu'il ne requiert pas l'exécution du système en continu. Il peut être utilisé pour l'exécution quotidienne, hebdomadaire et mensuelle de tâches généralement exécutées par cron.
Les tâches Anacron sont répertoriées dans le fichier de configuration /etc/anacrontab. Chaque ligne de ce fichier correspond à une tâche. Elles se présentent sous le format suivant:
period delay job-identifier command |
period — fréquence (en jours) d’exécution de la commande
delay — temps d’attente en minutes
job-identifier — description de la tâche ; utilisé dans les messages Anacron et comme nom du fichier de référence temporelle de la tâche ; peut contenir tout caractère autre qu’un blanc (à l’exception des barres obliques).
command — commande à exécuter
Pour chaque tâche, Anacron détermine si la tâche a été exécutée au cours de la période spécifiée dans le champ period du fichier de configuration. Si ce n'est pas le cas, Anacron exécute la commande spécifiée dans le champ command après avoir respecté le délai d'attente spécifié dans le champ delay.
Pour le fichier /home/tous/partage, enlevez le plus souvent possible les droits d'exécutions pour le groupe et les autres utilisateurs sur chaque fichier, pas les répertoires (faire « chmod --help »).
Tandis que cron et anacron servent à programmer des tâches récurrentes, la commande at est utilisée pour programmer une tâche unique à un moment donné. La commande batch sert à programmer une tâche qui doit être exécutée une seule fois lorsque la moyenne de chargement du système descend en dessous de 0,8=80% (lorsque le système passe au moins 20% de temps à attendre qu'on lui dise de faire quelque chose).
Pour exécuter une seule fois une tâche spécifique lorsque la moyenne de chargement est inférieure à 0.8, utilisez la commande batch.
Une fois la commande batch saisie, l'invite at> s’affiche. Entrez la commande à exécuter, appuyez sur la touche et tapez Ctrl-D. Vous pouvez spécifier plusieurs commandes en entrant chacune d'elles suivie de . Après avoir tapé toutes les commandes, appuyez sur la touche afin d'afficher une ligne vide, puis tapez Ctrl-D. Un script shell peut également être saisi en appuyant sur la touche après chaque ligne du script et en tapant Ctrl-D sur une ligne vide pour quitter. Si un script est saisi, le shell utilisé est celui défini dans l'environnement SHELL (configuration de la ligne de commande, on peut connaître la notre en faisant : « echo $SHELL » ) de l'utilisateur, le shell de connexion de l'utilisateur ou /bin/sh (celui qui est trouvé en premier). L'ensemble de commandes ou de scripts est exécuté dès que la moyenne de chargement se situe en dessous de 0.8.
Si l'ensemble de commandes ou de scripts essaie d'afficher des informations dans la sortie standard, ces informations sont envoyées par courrier électronique à l'utilisateur.
Utilisez la commande atq pour afficher les tâches en attente. L'utilisation de la commande batch peut être restreinte. Les fichiers /etc/at.allow et /etc/at.deny (comme pour /etc/cron.allow et /etc/cron.deny) peuvent servir à limiter l'accès aux commandes at et batch. Le format de ces deux fichiers de contrôle d'accès requiert un nom d'utilisateur sur chaque ligne. Les espaces blancs n'y sont pas acceptés. Le démon at (atd) n'a pas à être redémarré si les fichiers de contrôle d'accès sont modifiés. Ces fichiers sont lus chaque fois qu'un utilisateur essaie d'exécuter les commandes at ou batch.
L'utilisateur root peut toujours exécuter les commandes at et batch indépendamment des fichiers de contrôle d'accès.
http://lea-linux.org/admin/daemons.php3
Un démon (daemon) est un processus système qui appartient soit à root, soit à un compte d’administration (daemon, mysql, apache par exemple). Les démons activent des services.
Les démons assurent des tâches d’ordre général (gestion des serveurs installés par exemple), ils sont parfois disponibles à tous les utilisateurs du système. Ils ne sont stoppés que pour arrêter un service, qu’à l’arrêt du système d’exploitation ou prendre en compte de nouveaux paramètres. Dans ce dernier cas, il faut aussitôt les remettre en marche. Cette dernière méthode permet de modifier les paramètres sans avoir à arrêter le système et le redémarrer juste après (rebooter le système).
Il faut utiliser la
commande suivante : systemctl
{start|stop|restart|reload|status} nom du
service
On arrête un démon
avec « nom_de_démon
stop » et on le relance avec « nom_de_demon
start », on l'arrête et on le relance
directement avec « nom_de_demon
restart ». Souvent, il faut rajouter le chemin
devant le nom du démon : /etc/init.d/
ou rajouter la commande service
devant. En fait on peut faire : « service
nom_service {start|stop|restart|reload|status} »
ou « /etc/init.d/nom_service
{start|stop|restart|reload|status} ».
La liste des démons qui tournent se trouve dans /etc/rcX.d/ avec X le 'run levelv' : 5 en interface graphique et 3 en ligne de commande. Il y a aussi .etc/xinetd.d/ où chaque démon correspond à un fichier configurable. Pour voir une liste il faut faire « ls /etc/rc5.d/ » par exemple. Avant de lancer un démon, il faut vérifier qu’il ne tourne pas déjà ! Ou tout simplement le tuer, s'il était déjà inactif, on aura un message d'erreur sans gravité, juste pour nous prévenir qu’il était déjà inactif. Ce message peut être parfois important car parfois, suite à une erreur dans les fichiers de configuration, il arrive qu'un démon lancé avec succès s'arrête immédiatement.
Pour ajouter un démon
à la liste des démons à lancer au démarrage, il faut faire :
« chkconfig
--add le_service ». Le démon devra
avant obligatoirement se trouver dans /etc/rc.d/init.d ou
/etc/init.d. « chkconfig »
est un programme pour gérer les démons, regardez « man
chkconfig ». Une option intéressante
est « chkconfig
--list » qui liste les états des
démons dans tous les 'run level'.
« update-rc.d »
est le penchant debian de chkconfig.
Avec le Centre de contrôle Mandriva (mcc), on comprend mieux ce qui se passe car il y a en plus des explications. Dans mcc, choisissez le menu système puis, Drakxservices. Là, vous pouvez arrêter, démarrer les démons ainsi que choisir ceux qui seront lancés au démarrage. En plus vous avez un bouton information par démon.
On peut trouver l’emplacement exact d’un programme avec « which le_programme ».
RPM signifie Red hat Paquage Manager. C’est le système de gestion de logiciel inventé par Red Hat qu'utilise Mageia.
http://c.laloy.free.fr/howtos/linux/index_rpm.html
Deb est le nom des paquets utilisés par debian et les distributions dérivées.
Toujours avec mcc, cette fois sur le menu « gestionnaire de logiciels ». Vous pouvez soit enlever des logiciels, soit en mettre, soit en rajouter des sources de logiciels ou juste faire la mise à jour de vos logiciels.
Installons le serveur Samba que nous avons volontairement oublié lors de l'installation. On clique sur « RpmDrake : installation de paquetages logiciels » et on tape samba dans la case de recherche. On dispose alors d'un choix impressionnant de logiciels contenant le mot samba! On va cocher samba serveur. Cette action ouvrira une fenêtre pour nous signaler qu'on doit installer un(des) autre(s) rpm pour que le serveur puisse fonctionner : on accepte cette obligation. On clique sur installer et tout doit bien se passer ! Après, on ferme RpmDrake. La procédure est semblable pour enlever des rpm. Ceci se fait automatiquement car le système à une base de données qui contient tous les programmes (rpm) disponibles sur les médias d'installation.
On peut rajouter des sources (de nouveaux médias avec d’autres programmes). Pour faire ceci, allons voir le site : http://easyurpmi.zarb.org/?language=fr. Rajoutons des sources disponibles, comme les sources pfl, (on pourra en ligne de commande regarder le répertoire /var/lib/urpmi/ et le répertoire /etc/urpmi). Dans mcc, toujours menu « gestionnaire de logiciels », on clique « Gestionnaire des dépôts de logiciels : choisir d’où sont téléchargés les logiciels ». Là, on peut travailler sur les sources avec les boutons de gauche. Regardons le bouton « Ajouter... ». Ca se complique! Que dit le site que nous regardons? Il donne simplement une ligne de commande ! Profitons en, passons à la ligne de commande !
Le logiciel synaptic.
Pour travailler sur les rpm, il faut avoir un shell avec les droits administrateur.
On rentre les lignes de commande proposées par http://easyurpmi.zarb.org/?language=fr. Un long téléchargement commence : les informations sur les données disponibles. On ouvre donc un autre shell en cliquant sur la page blanche dessinée en bas à gauche de la fenêtre de shell. On se loge sous root dessus et on continue de travailler. À la fin du téléchargement, vous pouvez toujours retourner sous RPMDrak et voir les logiciels disponibles automatiquement : tapez par exemple DVD dans la recherche...
En ligne de commande on installe LinNeighborhood : « urpmi --auto-select LinNeighborhood ». L'option « --auto-select » a permis la sélection de tous les rpm dont dépend LinNeighborhood. Il existe d'autres programmes pour gérer les rpm : faîtes « rpm + tab » ainsi que « urpm +tab » et regardez. Pour plus d'information, faîtes « man le_programme_qui_vous_intéresse ». Par exemple avec « rpm -q proftpd », vous pouvez savoir si proftpd a été installé avec un rpm et quelle est sa version.
Après cette manipulation, on peut faire une mise à jour. On pourrait passer par le mode graphique, mais on va rester en ligne de commande. Nous allons commencer par créer un alias (raccourci) sous root : « alias maj='urpmi.update -a;urpmi –auto-select –auto --keep' ». Attention, parfois, il peut être utile de vérifier les mises à jour proposées, dans ce cas, le « --auto » est en trop. Nous avons défini un nouveau raccourci. Pourvoir tous ceux qui sont déjà définis, on peut faire simplement « alias ». On peut définir autant d’alias qu’on le souhaite, on peut le faire avec celui-là, car il sera utile par la suite pour gérer le PC et indispensable pour une gestion à distance. On rajoute donc la ligne « alias maj='urpmi.update -a;urpmi –auto-select –auto --keep' » (sans les guillemets) dans le fichier « .bashrc » de la racine du répertoire personnel (de root ici). Pour faire la mise à jour on attend que toutes les autres installations soient achevées et on tape « maj », notre alias (comparer cette mise à jour à une mise à jour d’un système concurrent payant :-) ).
Pour enlever un rpm, on utilise la commande « urpme ».
Voir aussi : http://www.urpmi.org/fr/index.php
Pour complètement nettoyer et refaire une installation à neuf comme s’il n’y avait rien eu avant :
apt-get clean
apt-get --purge remove ulogd
apt-get check
apt-get install ulogd
La gestion des rpm se fait avec une base de données qui contient à la fois les rpm disponibles (en fonction des sources choisies) et les rpm installés. Il se peut qu’il y ait un plantage lors de la manipulation de ces bases de données (alimentation, crash disques dur...). La base de données est donc détériorée.
La commande à utiliser est :
# rpm --rebuilddb
Parfois ceci ne suffit pas, l’expérience dit qu’on peut alors faire avant une des deux (voir les deux ?) instructions suivantes :
updatedb
rm -fr /var/lib/rpm/__*
voir : http://c.laloy.free.fr/howtos/linux/index_rpm.html
Parfois, il se peut (si on utilise la version de test de Mandriva, comme moi : la cooker), que urpmi soit mort... Heureusement, il existe aussi sous Mandriva smart (qui vient de connectiva) qu’il faudrait avoir installé avant que urpmi soit cassé pour l’utiliser après :
smart update
smart upgrade
On peut aussi avoir l'information sur l'ordre des rpm installés :
rpm -qa --qf '%{installtime} %{installtime:date} %{name}-%{version}-%{release}\n' | sort -n
Nous espérons que ce petit tableau vous permettra de passer facilement de Mageia à Debian ou inversement.
Sur Gentoo, le parametre nom du package peut être :
un nom simple (xfree)
un nom avec categorie (x11-base/xfree)
un fichier ebuild (/usr/portage/x11-base/xfree/xfree-4.3.0-r3.ebuild)
un package binaire precompile (/usr/portage/packages/x11-base/xfree-4.3.0-r3.tbz2)
un masque (<x11-base/xfree-4)
Description |
Debian |
Mandriva |
Gentoo |
|---|---|---|---|
Installer un package |
apt-get install nompackage |
urpmi nomdupackage |
emerge nomdupackage |
Installer un package manuellement, sans gérer les dépendances |
dpkg -i nompackage.deb |
rpm -ivh |
emerge --nodeps nomdupackage |
Rechercher des packages par mot-clés |
apt-cache search motclé1 [motclé2 ...] |
urpmq motclé1 [| grep motclé2...] |
emerge search expressionreguliere |
Afficher des informations détaillées sur un package (pas forcément installé) |
apt-cache show nompackage |
urpmq -i nomdupackage |
emerge search expressionreguliere |
Supprimer un package |
apt-get remove [--purge] nompackage |
urpme nomdupackage |
emerge unmerge nomdupackage |
Afficher la liste des packages installés |
dpkg -l [masque] |
rpm -qa |
equery list -i \* |
Afficher les fichiers contenus dans un package |
dpkg -L nompackage dpkg –contents nompackage |
rpm -ql nompackage |
equery files nomdupackage |
Rechercher de quel package provient un fichier |
dpkg -S fichier si installé |
rpm -qf fichier |
equery belongs fichier |
Mettre à jour la base de données des packages |
apt-get update |
urpmi.update -a |
emerge sync |
Pour mettre à jour les packages installés |
apt-get upgrade |
urpmi --auto-select |
|
Pour mettre à jour la distribution vers une plus récente, ou pour des modifications plus profondes (Par exemple, XFree sera remplacé par Xorg) |
apt-get dist-upgrade |
|
|
Mettre à jour tous les packages du système |
apt-get dist-upgrade |
urpmi --auto-select |
emerge -uD world |
fichier contenant la liste des sources pour mettre à jour la base de données des packages |
/etc/apt/sources.list |
/etc/urpmi/urpmi.cfg
à modifier avec |
/etc/make.conf |
marquer un package pour ne pas qu'il soit mis à jour |
echo nompackage hold | dpkg --set-selections |
echo nomdupaquet >> |
On l'ajoute a |
Interface GUI |
synaptic |
rpmdrake |
|
Sources : http://linux.ensimag.fr/urpmiapt.html
Mise à jour d’une debian automatiquement avec cron-apt ou apt-cron
Il est bien sur possible d’installer des programmes sans rpm. Certains sont livrés autoextractables avec un exécutable qui pose deux-trois questions avant de s'installer. Souvent, lors de l'extraction il y a des fichiers du style « README » à lire avant.
Parfois, on ne récupère que les sources (c’est de plus en plus rare), il faut alors compiler soi-même le programme. Dans ce cas, il faut avoir installé les bons logiciels (un compilateur C/C++ la plupart du temps) et les bonnes librairies.
Quelle que soit la manipulation que nous souhaitons faire ici, il est INDISPENSABLE d’avoir les droits administrateurs pour les faire.
Il y a bien sur dans mcc ou d’autres logiciels parfois très bien faits la possibilité d’avoir des GUI (interface graphique utilisateur) pour configurer les serveurs, mais je pense qu’il est plus puissant de le faire à la main. Bien qu’au début ce soit un peu rébarbatif, finalement, on trouve rapidement que c'est plus rapide et plus puissant à la main. Un autre intérêt est la possibilité de faire les modifications à distance sans GUI. Nous allons voir par la suite plusieurs exemples.
Dès qu’on modifie les fichiers de configuration à la main, il ne faut pas oublier d’arrêter et relancer le démon associé pour que la nouvelle configuration soit effective « systemctl restart nom_du_demon » . Avec Linux, il n’y a pas besoin d’arrêter la machine et de redémarrer la machine !
Les serveurs de réseau et les services sont des programmes qui permettent à un utilisateur distant de devenir utilisateur de votre machine. Les programmes serveurs sont à l’écoute des ports réseau. Les ports réseau permettent de demander un service particulier à un hôte particulier et de faire la différence entre une connexion telnet entrante et une connexion ftp entrante. L’utilisateur distant établit une connexion réseau avec votre machine puis le programme serveur, ou démon de réseau, à l’écoute du port, accepte la connexion et s'exécute.
Pratiquement chaque serveur à un port, qui lui est attribué. Lors d’une connexion à un ordinateur hôte, il est nécessaire de spécifier l'adresse de cet hôte mais aussi son port. Le numéro de port va spécifier quel service de cet hôte vous voulez utiliser. Par exemple, le port pour une communication Telnet est 23, celle pour une communication HTTP est 80… Mais rassurez-vous, le choix du port est aujourd’hui dans la plupart des cas automatique.
Afin de savoir quel service est associé à quel port pour votre ordinateur, regarder le fichier /etc/services .
La notion d'heure pour des équipements informatiques (serveurs, stations de travail, PCs, MACs...) est importante, ne serait-ce que pour le datage des fichiers. Bien qu’utilisant des oscillateurs à quartz il faut les remettre à l’heure régulièrement sinon ils dérivent comme toute montre ordinaire. Ce problème s'accentue dans le cas d'équipements en réseau qui se retrouvent rapidement avoir tous, des heures différentes bien que partageant de plus en plus souvent les mêmes systèmes de fichiers…
Pour ceci, il existe le protocole NTP (Network Time Protocole) qui permet à un ordinateur de synchroniser son horloge sur un ordinateur de précision plus élevé. Vous pouvez trouver la liste des serveurs français sur : http://www.cru.fr/NTP/serveurs_francais.html . Attention, vous ne pouvez vous synchroniser que sur des serveurs secondaires (strate 2) car les serveurs primaires (strate 1) sont destinés à synchroniser essentiellement les serveurs de strate 2 publics, à la rigueur des serveurs de sites importants (plusieurs centaines de clients locaux) mais pas des "petits" serveurs voire des clients terminaux…
Vous devez installer le rpm ntp : « urpmi ntp » ou « apt-get install ntpdate » puis faire une mise à l'heure : « ntpdate pool.ntp.org ». Cette méthode, bien qu’efficace, n’est pas satisfaisante, car elle doit être effectuée à la main. Nous pouvons mettre cette commande dans un des répertoires /etc/cron.* en fonction de la période de rafraîchissement que nous voulons avoir.
Voir au XVII) la configuration d'un serveur ntp et plus d’informations sur le sujet.
http://alexandre.alapetite.net/iup-gmi/ntp/
http://petitjournal.org/index.php?page=5035 et http://www.linux-france.org/article/cesar/index.php?page=5035
Pour sortir des plantages (souvent dus au serveur X ou aux applications graphiques) nous disposons de plusieurs possibilités :
Revenir dans une fenêtre texte avec Ctrl-Alt-FX (X entre 1 et 6)
si le plantage du serveur X plante même le clavier : un ssh à partir d'un PC voisin
Il reste aussi une solution … pour éviter le RESET sauvage, les MagicSysReq
(option CONFIG_MAGIC_SYSRQ=y dans la config du noyau)
ALT+Touche Système (Impr. Écran) + R ()
ALT+Touche Système (Impr. Écran) + S (synchro des disques)
ALT+Touche Système (Impr. Écran) + E
ALT+Touche Système (Impr. Écran) + I
ALT+Touche Système (Impr. Écran) + U (démontage)
ALT+Touche Système (Impr. Écran) + B (reboot)
Pour résumer, en cas de plantage grave de votre machine, il suffit de faire [Alt][Syst][s] pour refermer les fichiers ouverts (on entend le disque dur travailler un court instant), suivi d'un [Alt][Syst][u] pour démonter les partitions, puis [Alt][Syst][b] pour redémarrer...
(description plus complète sur /usr/src/linux/Documentation/sysrq.txt si les sources du noyau sont installées).
Une des raisons de plantages réguliers avec erreur sur les partitions des disques durs peut être une barrette de RAM défectueuse. Pour tester cela, vous pouvez installer memtest86 : « urpmi memtest86 » qui s’exécute lors du boot (choix proposé par LILO ou Grub). Il est aussi possible que le disque dur soit mort, avant de le jeter essayez tout de même un formatage bas niveau du disque dur avec lformat par exemple ou un utilitaire du genre ultimat boot cd : http://www.ultimatebootcd.com/ .
http://www.cryptos.ch/spip.php?article38
ifup eth1 : lancer l'interface eth1
ifdown eth1 : arrêter l'interface eth1
Il va falloir attribuer une "adresse" unique à une carte réseau afin de permettre aux ordinateurs de communiquer. Cette adresse correspond à une norme (IPv4) définie dans les protocoles de communication TCP/IP. Elle est constituée de 4 séries d’au maximum 3 chiffres séparés par un simple point et allant de 0 à 255, comme ceci :
xxx.xxx.xxx.xxx
En fait on n’utilise pas 255 qui sert de masque et 0 non plus d’ailleurs, donc on va de 1 à 254.
Dans un réseau, un ordinateur est donc désigné par l’adresse attribuée à sa carte ethernet.
Certaines adresses sont réservées à certains usages. Par exemple "127.0.0.1" : il s’agit de l’adresse de "bouclage" ou "rebouclage" et représente l’ordinateur lui-même. Les adresses sont réparties en "classes". Une classe d’adresses est réservée aux réseaux locaux c’est-à-dire des adresses ne devant pas être diffusées sur Internet.
Les classes peuvent être 10.0.0.0 à 10.255.255.255 (10/8 prefix), 172.16.0.0 à 172.31.255.255 (172.16/12 prefix) et 192.168.0.0 à 192.168.255.255 (192.168/16 prefix). C’est 192.168.0.0 dont on se servira. Elle est répertoriée comme "classe C". On n’utilise pas une adresse qui se termine par 0 pour adresser une machine, car cette adresse désigne le réseau lui-même. Ainsi dans le réseau 192.168.0.0 la première adresse utilisable est 192.168.0.1 et la dernière 192.168.0.254
Attention d’autres adresses ou classes sont réservées :
Les détails par ici, par là et par là aussi
Revenons à notre petit réseau.
La première interface réseau de l’ordinateur sera appelée sous Linux "eth0", la deuxième "eth1" etc. Nous allons donc attribuer une adresse locale (par exemple 192.168.0.1) à eth0, notre carte ethernet.
Ouvrir un terminal, passer sous root :
$
su
Passwd:xxxxxxxx
# ifconfig eth0 192.168.0.1 netmask
255.255.255.0
C’est fait, si on tape (sous root) "ifconfig" on peut voir ses différentes interfaces réseaux et leurs configurations. Pour qu’elles soient conservées au redémarrage de la machine il faudra que cela soit inscrit définitivement dans un fichier de configuration : voir le paragraphe "5. Les fichiers"
On peut faire la même chose sous Mandriva en passant par le Centre de Contrôle —> Réseau et Internet —> Reconfigurer une interface réseau. Dans "périphérique sélectionné" choisir eth0, dans l’onglet "TCP/IP", "protocole" choisir statique, remplir le champ adresse avec 192.168.0.1 (dans notre exemple mais on peut en prendre une autre), dans "masque de sous-réseau" on doit avoir 255.255.255.0 et dans "passerelle" rien, pour l’instant nous n’avons pas partagé notre connexion internet. On peut aller dans l’onglet "options" pour choisir les options qui nous conviennent ; dans l’onglet information on peut lire les renseignements sur sa carte et plus particulièrement son adresse matérielle ou adresse MAC qui est unique pour chaque carte (ifconfig donne ce renseignement sous "HWaddr") .Ok. Le fichier de configuration est alors écrit.
On peut vérifier que ce paramétrage sera bien pris en compte (et conservé lors du redémarrage) dans le fichier /etc/sysconfig/network-scripts/ifcfg-eth0 (pour la carte eth0, ifcfg-eth1 pour la carte eth1 etc...). Il doit ressembler à cela (on peut évidemment le remplir à la main si on n’utilise pas le centre de contrôle de Mandriva, les lignes marquées d ’un # sont des commentaires) :
networkDEVICE=eth0
BOOTPROTO=static
#protocole
statique par opposition à DHCP qui négocie seul l'attribution des
adresses
IPADDR=192.168.0.1
#adresse ip
choisie
NETMASK=255.255.255.0
# c'est le masque de
sous-réseau, il comporte les 254 adresses de cette
classe.
NETWORK=192.168.0.0
# c'est le réseau lui-même
d'ou le 0 à la fin.
BROADCAST=192.168.0.255
#diffusion en
français. Indique en liaison avec le masque de sous-réseau que la
plage de diffusion se fait pour les machines 192.168.0.1 à
192.168.0.254
ONBOOT=yes
# on lance l'interface au
démarrage
HWADDR=xx:xx:xx:xx:xx:xx
# adresse
MAC
METRIC=10
# etc... selon les options choisies
http://linux.developpez.com/faq/?page=configdebian#debnetconf
http://www.debian.org/doc/manuals/reference/ch-gateway.fr.html
Pour toute machine située dans un réseau local ou derrière un routeur, la configuration passe principalement par le fichier /etc/network/interfaces dont voici un exemple :
auto eth0
iface eth0 inet dhcp
pre-up ifconfig eth0 hw ether 00:60:08:11:51:D7
up vi start
auto eth1
iface eth1 inet static
address 192.168.2.1
netmask 255.255.255.0
broadcast 192.168.2.255
Chaque interface réseau doit être activée par la ligne « auto ethX ». Ce fichier est pour une passerelle, internet étant sur eth0 et le réseau interne sur eth1. Les 2 exemples présentés montrent une configuration en IP statique pour eth1, les paramètres parlent d’eux-mêmes, et eth0 est quant à elle configurée en DHCP pour acquérir ses paramètres automatiquement. L’interface locale quant à elle a la configuration particulière "loopback". La ligne "up" suivie du nom d’un script iptables permet de démarrer automatiquement le firewall dès que l’interface réseau est configurée, ce qui permet d’avoir une protection immédiate et de ne pas laisser le réseau une seule fraction de seconde sans défense. C’est le meilleur endroit pour placer votre script iptables. Plutôt que d’éditer le fichier à la main, vous pouvez lancer l’assistant de configuration en mode console par la commande dpkg-reconfigure etherconf.
Il y a aussi avec les commandes ethtools ( apt-get install ethtool ) mii-tool, net-tools ( apt-get install nettools ) et mii-diag ( apt-get install mii-diag ).
Si on reçoit internet par une interface configurée en static, alors il est important de mettre en paramètre une autre ligne qui défini le routeur pour aller vers le net (ici 192.168.1.1) :
gateway 192.168.1.1
Une fois le fichier interfaces modifié, vous devez réinitialiser le réseau par la commande /etc/init.d/networking restart pour que la nouvelle configuration soit prise en compte.
Pour une configuration en IP statique, n’oubliez pas d’indiquer les serveurs de résolution de nom dans le fichier /etc/resolv.conf (cf. Q/R sur la configuration générale du réseau).
Dans le cas d’une connexion PPPoE (par exemple si votre carte réseau est directement connectée à un modem ADSL), utilisez le script pppoeconf qui écrira les bonnes options dans les fichiers de configuration adéquats.
Pour changer le nom de la machine jusqu’au prochain allumage :
hostname ton_nouveau_nom
Seulement ça n’est pas tout, si on veut conserver notre nom d’hôte dans notre prompt et ne pas se retrouver avec un "localhost" au prochain redémarrage il faut affecter à la machine la variable HOSTNAME.
Attention : en fin de manipulation, pensez dans ce cas à bien informer /etc/hosts :
127.0.0.1 localhost ton_nouveau_nom
on va donc le faire (sous root avec l’éditeur de votre choix) dans le fichier /etc/sysconfig/network comme ceci (# indique des commentaires)
HOSTNAME=ton_nouveau_nom
#voici la ligne à ajouter
NETWORKING=yes #ça y était déjà
On enregistre (attention il est prudent avant de modifier un fichier d’en faire une copie avec une extension *.bak ou *.old : en cas d’erreur il sera facile de revenir en arrière).
Dans les nouvelles versions de Mandriva (2007 et plus récent), on peut modifier le fichier /etc/rc.d/rc.sysinit :
#HOSTNAME=`/bin/hostname`
HOSTNAME= ton_nouveau_nom
On commente la première ligne pour la remplacer par la seconde. Cependant, une modification dans /etc/sysconfig/network est prioritaire.
On relance les services réseaux (toujours sous root bien sûr) :
# service network restart
Vous pouvez constater qu’en ouvrant une console l’invite a changé et contient désormais votre nom de machine. Si vous redémarrez vous conservez ce nom. La commande "hostname" permet aussi d’afficher le nom d’hôte défini dans la variable HOSTNAME.
Ceci dit, beaucoup de programmes fonctionnant avec le nom de l'ordinateur, il est préférable de rebooter après pour être sûr que tout soit bien configuré.
À tester :
Bon je fais un copier-coller de la console de ma machine, sans relance de session, sous root pour avoir tout (c'est rigolo) : *********************************** [root@gaia andre]# /bin/hostname gaia.terre [root@gaia andre]# /bin/hostname essai.bete [root@gaia andre]# /bin/hostname essai.bete [root@gaia andre]# cat /etc/HOSTNAME gaia.terre **************************** mais c'est pas tout : ***************************** [root@gaia andre]# env | grep -i hostname HOSTNAME=gaia.terre [root@gaia andre]# hostname essai.bete ********************** retour au point de départ : ********************** [root@gaia andre]# /bin/hostname gaia.terre [root@gaia andre]# hostname gaia.terre [root@gaia andre]# cat /etc/HOSTNAME gaia.terre *****************
Pour debian, voir : /etc/hostname qui ne contient qu'un mot, le mon du PC !
En pratique et pour la suite il serait utile de configurer aussi un nom de machine ou nom d’hôte pour les PC du réseau. Celui-ci se trouve dans le fichier /etc/hosts et se présente en 3 zones ainsi :
127.0.0.1 'nom' 'alias'
"nom" correspond à "nom_de_machine.nom_de_réseau.nom_de_domaine" ; "alias" est généralement le nom seul de la machine. Le nom de réseau peut être ce qu’on veut dans la mesure où son utilisation n’est que locale.
On peut modifier ceci
directement sous root en éditant le fichier /etc/hosts (chaque zone
est séparée par un espace) ou avec le centre de contrôle —>
Réseau et Internet —> gérer les définitions d’hôtes.
On
sélectionne l’adresse IP puis on modifie le nom d’hôte et les
alias (interface avec plusieurs champs pour faciliter les choses),
par exemple
127.0.0.1
localhost.localdomain localhost
# cas d'une machine non
connectée en réseau
Il peut y avoir plusieurs hôtes : 127.0.0.1 (la boucle locale) sera appelée localhost.localdomain avec comme alias localhost ; 192.168.0.1 (l’adresse de notre interface réseau - eth0- sera appelée par le nom de notre machine dans notre réseau et domaine. Une seule interface par ligne. Par exemple :
127.0.0.1
localhost.localdomain localhost
#notre carte réseau(eth0) qui
sera aussi le nom de notre serveur sur le réseau.
192.168.0.1
serveur.chezmoi.fr serveur
#etc... pour les autres machines du
réseau en utilisant l'adresse IP attribuée à leur carte réseau et
leur nom d'hôte complet.
On fait la même chose pour les différentes machines de notre réseau en évitant bien sûr de leur affecter la même adresse et le même nom de machine (à part localhost qui correspond à la boucle locale : une machine est toujours 127.0.0.1 localhost pour elle-même). Il serait en revanche logique dans notre cas de leur affecter les mêmes réseau et domaine. Par exemple pour la première machine :
#La
boucle locale
127.0.0.1 localhost.localdomain localhost
#Carte
réseau et donc nom de cette machine sur notre réseau
privé
192.168.0.10 client1.chezmoi.fr client1
#Le
serveur
192.168.0.1 serveur.chezmoi.fr serveur
# etc...
pour toutes les machines du réseau.
Ça n’est bien sûr pas indispensable mais ça va être pratique pour nommer les machines "humainement" dans un réseau, parce que franchement 192.168.0.1, 192.168.0.10 etc... on peut constater que l’esprit humain n’est pas très fort à mémoriser ce genre de truc. C’est à cela que sert le fichier /etc/hosts, ce fichier devra être dupliqué sur tous les ordinateurs du réseau. C’est ici qu’on listera les autres machines faisant partie de notre réseau donc autorisées. Une ligne par machine en commençant par l’adresse et ceci sur chaque machine du réseau. Nous (les humains) pourrons ainsi, grâce à cette correspondance, désigner les machines par leurs noms et pas uniquement par leurs adresses IP.
On peut également voir des fichiers hosts.deny et hosts.allow qui permettent d’affiner respectivement les interdictions et autorisations de connexions, nous aurons l’occasion d’en reparler par la suite.
Une dernière chose : si nous considérons que notre machine 192.168.0.1 est celle qui va contenir les fichiers à partager et que nous utilisons donc comme serveur, les autres étant clientes, il est préférable d’affecter à cette tâche la machine la plus puissante.
Pour vérifier si le réseau est fonctionnel on utilise la commande ping dans un terminal pour voir si les machines répondent :
$ ping 192.168.0.1
Et ainsi de suite pour les autres machines. Pour arrêter le processus [Ctrl-c].
Voilà une fois cela fait on devrait être prêt pour choisir un protocole de communication et le mettre en place.
Il est aussi possible de définir un serveur DNS pour le réseau local. Cette manipulation, bien que plus lourde à mettre en oeuvre, simplifiera la maintenance du réseau.
$ nmap -sP 192.168.0.*
Cette commande vous informera de tous les PC présents sur votre réseau,
http://newbie.opentech.be/forum/viewtopic.php?t=44
Pour certaines raisons tout à fait louables, il peut parfois être nécessaire de devoir changer la mac adresse de sa carte réseau. Par exemple quand momentanément, on change un serveur sous Ip dynamique.
Avec debian, voila comment changer cela au démarrage et donc faire "comme si" le changement était définitif en utilisant la directive pre-up de /etc/network/interfaces :
#
le fichier /etc/network/interfaces
auto eth0
iface eth0
inet static
pre-up ifconfig eth0 hw ether 0A:0B:AA:89:68:34
address 192.168.0.10
netmask 255.255.255.0
gateway
192.168.0.1
ftp est un protocole de transfert de fichiers (File Transfert Protocole) qui permet d'échanger des fichiers entre ordinateurs.
Le serveur ftp se configure avec le fichier /etc/proftpd.conf car nous avons choisi le serveur ftp proftpd. Il existe aussi wu-ftp qui avait plus de failles de sécurités. Le rpm étant déjà installé (en cas de besoin : « urpmi proftpd », on n'a plus qu'à configurer le système. puis relancer le démon : « systemctl restart proftpd »( ou utilisation : /etc/init.d/proftpd {start|stop|status|restart|reload|resume|suspend} avec les vieilles versions).
Parfois, les personnes auxquelles on donne un accès ftp n'ont peut-être pas besoin d'accéder à d'autres services sur le PC. Par exemple, elles n'ont peut-être pas besoin de se loger, d'avoir accès à la ligne de commande. Par sécurité, on peut donc leur enlever ce droit. Ceci se fait en choisissant un shell spécial : /bin/false. Et pour que cette option puisse se paramètrer en ligne de commande (sans rentrer manuellement dans le fichier /etc/password), il faut rajouter la ligne /bin/false dans /etc/shell si elle n'y est pas.
Pour plus de renseignements sur , voir /etc/proftpd.conf :http://linux.tnc.edu.tw/techdoc/proftpd-userguide/userguide.html ou http://matthieu.bouthors.org/wiki/doku.php?id=linux:proftpd
Voici un exemple commenté de fichier :
# Cette ligne, comme toutes celles qui commencent par un dièse (#), est un commentaire
# Les commentaires seront placés devant les paramètres
# Le nom du serveur. C'est le nom qui s'affiche lors de la connexion d'un client.
ServerName "Troumad"
# Le démon ftpd sera toujours actif et c'est lui qui répondra aux sollicitations des clients FTP.
# Un autre réglage pourrait être xinetd pour que ce soit xinet qui,
#à la demande du client ne réveille le démon.
ServerType standalone
# c'est pour des hôtes virtuels je/nous n'en sommes pas là.
DefaultServer on
# C'est pour autoriser les clients à reprendre un téléchargement vers le serveur.
AllowStoreRestart on
# on pourrait changer le port, mais bon..., c'est le port 21 qui normalement sert au ftp
Port 21
# Umask 022 est un bon standard : On enlève les droits d'écriture au groupe et aux autres
Umask 022
# Nombre à limiter pour la sécurité
MaxInstances 30
# L'utilisateur normal est nobody, son group est nogroup. nobody est fait pour ça.
User nobody
Group nogroup
<Limit LOGIN> # Qui peut faire du ftp?
DenyAll # personne, obligatoire pour ici, pour d'autres services ce n'est pas le cas
AllowGroup ftp # sauf les membres du groupe ftp
</Limit> # c'est juste une protection...
# les clients authentifiés ont le droit de mettre à jour leurs fichiers
<Directory /*>
AllowOverwrite on
</Directory>
#Pour permettre aux "anomymes" de se connecter décommenter les lignes suivantes
#<Anonymous ~ftp> # configuration de base, permettant le téléchargement à partir du rép. /var/ftp
# User ftp
# Group ftp
# UserAlias anonymous ftp
# MaxClients 10 # 10 connexions maxi en anonymous
# RequireValidShell off
# AnonRequirePassword off # pas de mots de passe valide
# <Limit WRITE>
# DenyAll # sans droits d'écriture.
# </Limit>
# <Directory depot/*> # répertoire de dépot
# <Limit READ>
# DenyAll # on ne peut pas lire
# </Limit>
# <Limit STOR>
# AllowAll # mais écrire
# </Limit>
# </Directory>
#</Anonymous>
# Needed for NIS.
PersistentPasswd off
# Message de bien-venue lors de l'identification (%u donne le nom de l'utilisateur)
AccessGrantMsg "Bienvenue %u chez Troumad"
DeferWelcome off
# Message qui s'affiche en ligne de commande au début de la communication
ServerIdent on "Serveur FTP Troumad prêt"
AllowForeignAddress on
# Chemin par défaut pour tous (personne de désigné) sauf moi (il y a un '!' devant mon nom)
# on peut mettre aussi bien des groupes que des utilisateurs.
# Tous, sauf moi, auront donc un chemin par défaut le répertoire public_html dans le répertoire
# personnel, et ne pourront voir ce qu'il y a plus vers la racine.
DefaultRoot ~/public_html !troumad
DefaultRoot / troumad
Ne pas oublier de relancer le démon après chaque modification du fichier de configuration afin qu'elles soient prises en compte.
http://www.modssl.org/docs/2.8/ssl_faq.html#ToC27
http://lea-linux.org/reseau/proftpd.html
en premier
lieu il te faut créer un CA:
1) mkdir /var/myca
cd /var/myca
2) créer un nouveau CA:
/usr/share/ssl/misc/CA.sh -newca
cela va créer
demoCA/cacert.pem et demoCA/private/cakey.pem (certificat CA and clef
privée)
3) Faire le CSR du serveur:
openssl req
-newkey rsa:1024 -nodes -keyout newreq.pem -out newreq.pem
4)
signer avec le certificat CA:
/usr/share/ssl/misc/CA.sh
-sign
5) Puis deplacer les certificats dans les
repertoire voulus:
cp demoCA/cacert.pem
/usr/var/proftp-data/cacert.pem
% mv newcert.pem
/usr/var/proftp-data/servercrt.pem
% mv newreq.pem
/usr/var/proftp-data/serverkey.pem
% chmod 400
/usr/var/proftp-data/serverkey.pem
Répéter les étapes
3), 4) et 5) pour le client et le tour est joué
Il existe une interface graphique pour proftpd : gproftpd. Elle s'installe avec « urpmi gproftpd » et se lance par« gproftpd ». Son utilisation semble simple quand on sait ce qu'on souhaite.
Tout d'abord, qu'est-ce que ssh. Principalement ce sont deux exécutables, un serveur (sshd) et un client (ssh), qui permettent d'ouvrir une console distante (à la manière de telnet), de manière sécurisée. D’autre part Il permet également la copie de fichier d'une machine à une autre (sans partage de disque!) à l'aide de scp, le tunelling sécurisé de port TCP, et peux même compresser les données ainsi transmises (utile sur des lignes à faible débit) ou rediriger les requêtes X, permettant par là même affichage d'une application sur une machine distante.
SSH signifie Secure SHell. C'est un protocole qui permet de faire des connexions sécurisées (i.e. cryptées) entre un serveur et un client SSH. Nous allons utiliser le programme OpenSSH, qui est la version libre du client et du serveur SSH.
Un serveur ssh est très important car il permet de prendre le contrôle de la machine à distance : d'avoir la main en ligne de commande. Il y a aussi le protocole telnet qui marche très bien mais pour des raisons de sécurité, il est devenu obsolète. ssh est choisi car les transferts de données sont codés : les mots de passe ainsi que les informations ne circulent pas en clair sur le réseau.
Comme on l'a vu ci-dessus, ssh permet de se connecter à une machine distante. Cela nécessite donc une identification et une authentification (un compte valide doit donc exister sur la machine distante).
Pour l'installer, il faut faire « urpmi openssh-server » ou « urpmi ssh-server ».
Le fichier de configuration du serveur est /etc/ssh/sshd_config , celui du client est /etc/ssh/ssh_config. Le démon est systemctl restart sshd (Utilisation : /etc/init.d/sshd {start|stop|restart|reload|condrestart|status} avec les vieilles versions) . Voici un exemple commenté :
#Port 22 # port par défaut
Protocol 2,1 # choix entre les protocoles 1 et 2
PermitRootLogin no # surtout interdire à root de pouvoir faire directement un accès en ssh
# On peut tout de même prendre le contrôle administrateur en faisant su
# ceci est plus sécurisant car le « su » laisse plus de trace dans les log
X11Forwarding yes # on peut renvoyer l'affichage
UsePrivilegeSeparation yes
#Compression yes # en plus d'être codé, le ssh est comprimé.
# ssh offre en plus la possibilité de faire du sftp, un protocole semblable à ftp,
# mais cette fois, c'est codé et compressé
Subsystem sftp /usr/lib/ssh/sftp-server
# Une protection pour ne permettre l'accès qu'à certaines personnes en ssh.
#DenyGroups * # interdire tous les groupes cités
#AllowGroups * # permettre à tous les groupes cités, ceci interdit l’accès aux autres
#DenyUsers * # interdire tous les utilisateurs cités, les autres sont autorisés
AllowUsers troumad cjm # cette ligne ne permet qu'aux deux comptes cités de pouvoir se loger
# et du même coup elle interdit aux autres l’accès au serveur ssh
# donc le DenyUsers devient inutile (comme avec les groupes)
Banner /etc/ssh/banniere # le lien vers la bannière pour prévenir d'éventuels pirates
Ne pas oublier de relancer le démon après chaque modification du fichier de configuration afin qu'elles soient prises en compte.
Pour utiliser ssh, il faut en ligne de commande faire « ssh login@serveur ». Après avoir tapé le mot de passe on a une ligne de commande sur le serveur.
Le fichier /etc/ssh/banniere peut être par exemple :
########################################### # # # ATTENTION ZONE PRIVÉE INTERDITE D’ACCÈS # # AUX PERSONNES NON AUTORISÉES # # # ###########################################
Ce message s'affichera avant même de rentrer le mot de passe, pour pouvoir porter plainte contre d'éventuels pirates, la présence de ce message est obligatoire. Il est aussi possible de mettre un message du même genre dans /etc/motd, mais ce message s'affichera après la connexion et quelque soit le mode de connexion.
Pour l'identification, l'identité du compte (nom d'utilisateur) à utiliser sur la machine distante est envoyé au serveur distant (nom d'utilisateur). Par défaut, l'identité de la machine cliente est utilisé, sinon pour en stipuler un, il y a deux manière de l'écrire (qui sont équivalentes), soit par l'option -l, soit dans l'URL (adresse) du serveur avec un @ (à la manière des courriels). Les deux exemples ci-dessous sont donc identiques :
ssh -l jean monserveur.com
Pour l'authentification , il y a (au moins) deux méthodes.
La première, classique, et que certains d'entre vous utilisent déjà, consiste à donner le mot de passe. Le serveur sshd va utiliser ce mot de passe (qui transite de manière cryptée, bien évidemment) pour s'identifier sur le système distant. Cela signifie donc que vous pouvez avoir des identités et des mots de passes différents sur les deux systèmes. L'avantage, c'est que mis à part le post-it collé sur votre écran , personne ne devrait arriver à découvrir le mot de passe, même en cas de compromission du poste client (le poste serveur ou distant, c'est une autre affaire). Le désavantage, c'est que cela demande de se souvenir d'un nième mot de passe et bien évidemment une interaction (quid des scripts etc... ?). Pour palier à ce problème, il y a une autre méthode d'identification.
Nb : comme je travaille sur plusieurs PC, afin d'identifier facilement sur lequel je suis, j'ai modifié le fichier « /etc/bashrc » afin qu'il mette en couleur le nom du PC : http://troumad.free.fr/Linux/prompt.zip . Ce fichier est automatiquement pris en compte par votre fichier .bashrc grâce aux lignes suivantes :
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
Si dans une fenêtre texte logée par ssh sur un autre PC, on lance une application graphique, cette dernière va s'afficher sur notre écran et sera exécuté sur l'autre PC. Ceci peut être pratique pour exécuter « mcc » afin de réparer graphiquement un PC dont l'interface graphique est inactive (window manager planté, serveur sans écran... ). Le réseau interne doit être protégé si on travaille sous telnet car tout passe en clair. De façon générale, il est conseillé, même pour un réseau interne de travailler sous ssh.
Pour y arriver on doit configurer le serveur en activant cette ligne dans /etc/ssh/sshd_config :
X11Forwarding yes # on peut renvoyer l'affichage
Le client, lui doit avoir la ligne suivante dans /etc/ssh/ssh_config :
ForwardX11 yes
Ceci peut se faire même en dehors d'un réseau local, mais la vitesse de connexion limite les transferts de manière radicale !
http://www.linux-france.org/prj/edu/archinet/systeme/x2500.html
La méthode par clef publique (la serrure), et clef privée (la clef). Dans ce mode, la clef publique est réellement à l'image d'une serrure, il faut la copier (ou l'installer) sur le serveur distant. La clef privée sera ensuite utilisée (comme une clef sur une serrure) pour s'identifier auprès de ce serveur. Il est donc important de protéger sa clef privée. Pour générer une paire de clef privée/publique, il faut utiliser l'utilitaire ssh-keygen. La commande suivante devrait créer une paire de clef publique/privée rsa de 1024 bits (par défaut) :
ssh-keygen -t rsa
Dès ce moment, deux fichiers sont créés dans le répertoire (caché) $HOME/.ssh :
id_rsa, qui contient la clef privée
id_rsa.pub qui contient la clef publique
Il est donc IMPORTANT que ce répertoire (.ssh) soit accessible en lecture/écriture UNIQUEMENT par l'utilisateur de ce répertoire, et interdit aux groupes (group) et aux autres (others)! Sans quoi il est facile de voler la clef privée.
Bon, petite précision ici. Lors de la génération de la clef, ssh va vous demander une "passphrase". Cette passphrase vas être utilisée pour CRYPTER la clef privée Ainsi, même en cas de compromission du client, ou de vol de la clef publique, cette dernière n'est pas utilisable sans la passphrase. Si on n'entre pas de passphrase, alors la clef privée n'est pas cryptée et est donc lisible par tout un chacun, si ce chacun à accès, d’une manière ou d’une autre, au répertoire $HOME/.ssh. En revanche une fois cryptée, cette clef est difficilement utilisable sans la passphrase. Contre partie du cryptage, ssh va avoir besoin de la passphrase pour décripter la clef privée. Nous avons donc perdu l’avantage de la non utilisation du mot de passe pour l’identification ? Non, ssh-agent est votre ami (man ssh-agent pour plus d'info), il va garder la passphrase en mémoire et l'utiliser pour expédier la clef publique au serveur. Voir chapitre suivant : G) Se logguer par SSH sans taper de mot de passe
Normalement chaque utilisateur souhaitant employer SSH avec l'authentification RSA ou DSA devra créer une fois pour toute la clef d'authentification dans $HOME/.ssh/identity, $HOME/.ssh/id_dsa ou $HOME/.ssh/id_rsa :
rsa1 créé par ssh-keygen -t rsa crée le fichier : identity
rsa2 créé par ssh-keygen -t rsa crée le fichier : id_rsa
dsa créé par ssh-keygen -t dsa crée le fichier : id_dsa
Je conseille de créer les 3, avec la même passphrase, de donner la priorité la plus faible à la rsa1, mais d'en avoir une quand même : il y a encore des machines un peu vieilles qui ne supportent que ça.
Pour modifier votre "passphrase" sur une clé privée DSA, utilisez la commande :
ssh-keygen -p -f ~/.ssh/id_dsa
En résumé, l'ordinateur sur lequel on est physiquement a une clef privée ~/.ssh/id_rsa et celui sur lequel on se connecte par ssh a la clef publique~/.ssh/id_rsa.pub qu'on renomme ~/.ssh/authorized_keys .
authorized_keys. Ce fichier peux contenir plusieurs clefs, donc si c’est ce que vous désirez, il vous suffit alors d’y ajouter une ligne avec le contenu du fichier id_rsa.pub au moyen de n’importe quel éditeur de texte. Je donne en exemple l'utilisation de scp, pour la copie du fichier id_rsa.pub
Pour récupérer une clef privée sur le serveur et la mettre sur un client :
scp jean@nomserveur:/home/jean/.ssh/id_rsa /home/jean/.ssh/
Il faut aussi renommer id_rsa : mv ~/.ssh/id_rsa ~/.ssh/identity
La commande scp copie un fichier vers ou à partir d'une machine distante d'une façon sécurisé.
# scp user@example.com:/COPYRIGHT COPYRIGHT
user@example.com's password: *******
COPYRIGHT 100% |*****************************| 4735
00:00
#
Les arguments passés à scp sont similaires à ceux de cp, avec le ou les fichiers en premier argument, et la destination en second. Puisque que le fichier est copié via le réseau, par l'intermédiaire de SSH, un ou plusieurs des arguments prennent la forme utilisateur@machine_distante:<chemin_du_fichier>.
L'exemple donné est fait avec échange de clef (chapitre précédent) activé pas ssh_agent (vois chapitre suivant).
Cette section s'adresse à ceux qui utilisent un couple de clés publiques / privées, et qui ont crypté leur clef privée avec une pass phrase (c'est la configuration la plus sûre). Par conséquent, le client SSH demande la pass phrase à chaque utilisation des clés pour s'authentifier.
Pour éviter d'avoir à taper systématiquement sa pass phrase, il faut utiliser ssh-agent : ce programme tourne en tâche de fond et garde la clef en mémoire. La commande ssh-add permet de donner sa clé à ssh-agent. Ensuite, quand vous utilisez le client SSH, il contacte ssh-agent pour qu'il lui donne la clé.
http://www.linux-france.org/prj/lfoyer/doc/html/ssh.fr-7.html ou http://cert.in2p3.fr/openssh.html
Dans une console, ouvrez un screen avec ssh-agent en tâche de fond :
% ssh-agent screen
Puis donnez votre clé à l'agent :
% ssh-add
Il vous demande alors votre pass phrase. Maintenant que votre clef a été transmise à l'agent, vous pouvez vous connecter sans entrer de mot de passe à toutes les machines pour lesquelles vous avez mis votre clé publique dans le fichier ~/.ssh/authorized_keys.
Attention : cette manipulation n'affectera que cette console, pas les autres !
Il faut aussi configurer correctement le serveur ssh. Dans le fichier /etc/ssh/sshd_config, il faut que les lignes suivantes soit déactivées :
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile %h/.ssh/authorized_keys
Il est possible de mémoriser la clef publique pour toute la session :
Dans ~/.xsession lancer le window manager avec ssh-agent (ceci est mis automatiquement par Mandriva !) :
ssh-agent twm
Il est possible que ssh-agent soit lancé automatiquement et que vous ayez une fenêtre qui s'ouvre au début de votre session graphique pour demander votre « passphrase ». Comme ça, tout votre environnement de travail connaît votre clef. Ceci rend inutile la suite des manipulations de ce chapitre en simplifiant bien la vie.
Au début de chaque session entrer « ssh-add » qui enregistre la 'pass phrase' et donne l'accès à la clef privée pour toute la session.
Il
est également possible d'utiliser le package ssh-askpass
(disponible
dans un package séparé par urpmi
ssh-askpass)
qui offre une invite X11 pour demander la 'pass phrase'. Pour cela,
dans ~/.xsession
lancer
le windows manager avec ssh-agent (startx
ou bien ~/.xinitrc
ou bien ~/.xsession
*) :
exec ssh-agent sh ~/xsession-twm // le window manager qui sera lancé par le script
// xsession-twm sera un fils de ssh-agent
Dans ~/xsession-twm :
ssh-add < /dev/null // ssh-add dont l'entrée est redirigée sur /dev/null
// utilise ssh-askpass pour demander la pass phrase pour fournir la clef à ssh-agent
twm // lance le window manager
* : Ces fichiers sont optionnels, ils servent à outrepasser la configuration par défaut (dans /etc/X11/xinit/xinitrc /etc/X11/Xsession) pour un utilisateur particulier.
Il suffit de mettre les lignes suivante dans ~/.bash_profile :
if [ -r $HOME/.ssh/identity -o -r $HOME/.ssh/id_dsa -o -r $HOME/.ssh/id_rsa ]; then
if [ ! -d $HOME/.keychain ]; then
keychain
fi
fi
Après, il faut installer keychain : « urpmi keychain »
Cette liste est très loin d’être exhaustive. Un man ssh ou la lecture de la documentation vous donnerons bien d’autres commutateurs communs à ssh et scp.
-C permet de compresser les données, niveau par défaut moyen (utile pour bande passante faible)
-o CompressionLevel=X en conjonction avec -C permet d'adapter la compression à utiliser (0=faible ou nul, 9=forte, par défaut, ce niveau est à 5)
-X permet de rediriger les requêtes X d’une application s’exécutant sur la machine distante vers la machine cliente (connectée)
-L permet de rediriger
un port, en connexion locale (127.0.0.1) vers un autre port d’une
machine se trouvant dans le même sous-réseau de la machine distante
(voir chapitre suivant).
Tunel ssh se dit aussi « Tunneling ».
Le client doit être configuré pour accepter le tuneling. Ceci se configure dans /etc/ssh/ssh_config en activant la ligne suivante :
ForwardAgent yes
http://slwww.epfl.ch/SIC/SL/Securite/outils/ssh-install.html#port-forwarding
Un autre intérêt du ssh est de pouvoir faire du tunneling ou port forwarding. Ceci consiste à rediriger un appel à travers le canal ssh. Pour ceci, à partir de HOST1, 'instruction est : « ssh -L p1:HOST3:p2 mon_login@HOST2 ». Cette manipulation permet en appelant le port p1' du PC client (HOST1) d'avoir le port p2 de HOST3 ce qui est intéressant si le port p2 de ce PC est protégé par un fire-wall.
Ceci peut aussi être fait à partir de HOST2 : ssh -R p1:HOST3:p2 root@HOST1.
Bien sûr, il faut avoir un contrôle administrateur sur le PC HOST1, donc la manipulation à partir de HOST2 est à éviter puisqu'elle requiert de permettre le SSH en tant que root.
Admettons le cas de figure suivant :
J'ai une machine serveur (192.168.0.1) sur un réseau local, tournant PostGreSQL sur le port 5432 (par défaut pour PostGreSQL). Une passerelle branchée sur l'Internet à l'adresse externe 64.32.74.12 (l'adresse est inventée! je ne sais pas à qui elle appartient) fait tourner sshd (le serveur) sur le port 22 (standard). Avec un client ssh il est dès lors possible de communiquer avec une application cliente PostGreSQL sur le serveur distant d'adresse interne, de manière sécurisée (éventuellement de compresser les données) au travers d'internet. Voici comment procéder :
ssh -L 5432:192.168.0.1:5432 un_compte_ssh_sur_passerelle@64.32.74.12
Maintenant en connectant l'application cliente de PostGreSQL sur localhost (ou 127.0.0.1), elle sera en communication, transparente pour elle, avec le serveur 192.168.0.1 se trouvant sur l'Internet à 64.32.74.12. En fait ssh va écouter le port 5432 localement (sur l'adresse localhost ou 127.0.0.1), tout ce qui y parvient est alors crypté et expédié en direction du port 22 vers 64.32.74.12. Sur cette machine, ces messages sont décryptés et expédié en direction du port 5432 vers 192.168.0.1. Les réponses suivent le chemin inverse.
Un autre exemple, soit une machine NT à l'adresse 192.168.0.1, alors
ssh -L 135:192.168.0.1:135 nom@64.32.74.12
ssh -L 137:192.168.0.1:137 nom@64.32.74.12
ssh -L 138:192.168.0.1:138 nom@64.32.74.12
ssh -L 139:192.168.0.1:139 nom@64.32.74.12
Un coup de voisinage réseau de la machine distante, devrait faire apparaître localhost (127.0.0.1) dans la fenêtre, représentant en fait le serveur NT distant.
kdessh permet de faire une demande graphique du mot de passe à l'utilisateur. Cela permet de créer une icône pour un utilisateur, et le mot de passe lui est demandé graphiquement, plutôt que par l’ouverture d’un terminal (ssh étant un outils en ligne de commande). Les commutateurs sont différents et moins nombreux, veuillez vous référer à la documentation (man kdessh)
Konqueror permet d'avoir une interface de fichier graphique pour la manipulation des fichiers (renommage, copie, suppression, déplacement etc..), sur une machine distante, en utilisant ssh. Pour ce faire, taper dans la ligne d'URL (en lieu et place de file:/qqchose ou http://quqchose) fish://nom_utilisateur_ssh@nom_serveur_ou_adresse_IP:/repertoire. Konqueror s'utilise alors de manière tout à fait standard, avec manipulation des droits, drag'n drop etc...). Interface vraiment bien pratique.
sftp est du ftp sous ssh (définition rapide). Pour le permettre, il faut configurer le serveur, fichier /etc/ssh/sshd_config :
Subsystem sftp /usr/lib/ssh/sftp-server
Pour avoir un accès sftp à un PC, il faut avoir accès à un shell ce qui n'est pas le cas du ftp. C'est à mon avis le gros problème de sécurité du sftp. Si on laisse l'accès en sftp à une personne, on lui laisse aussi l'accès en ssh. Le transfert des données est donc sécurisé, mais la personne en face, on ne la connaît peut-être pas!
J'ai trouvé une astuce consistant à empêcher la ligne de commande à une personne dès qu'elle veut afficher son prompt, en faisant du ssh par exemple. Voici le .bashrc de cette personne (il n'empêche pas d'ouvrir un WM, mais dans ce WM, il ne peut ouvrir de shell) :
if [ "$PS1" ]; then
exit
fi
Il existe un shell sécurisé ne permettant pas de faire du ssh : « scponly » qu'il faut installer et donne par défaut à l'utilisateur dans /etc/passwd en mettant comme shell : /usr/bin/scponly
J'ai aussi entendu parlé d'un dummy_ssh_shell, qui serait un shell ne donnant accès qu'au sftp, mais je ne l'ai jamais trouvé!
Ou en lui créant un shell chrooté avec http://www.fuschlberger.net/programs/ssh-scp-chroot-jail/make_chroot_jail.sh et les infos disponibles ici: http://www.fuschlberger.net/programs/ssh-scp-chroot-jail/ Il ne pourra pas remonter plus haut que son chroot-jail, en général, son home-directory sur le serveur...
Par l'exemple :
$ xhost + access control disabled, clients can connect from any host $ ssh -l operateur undertaker "nohup X : 2 & " operateur@undertaker's password: $ ssh -X operateur@undertaker xcalc operateur@undertaker's password: Warning: untrusted X11 forwarding setup failed: xauth key data not generated Warning: No xauth data; using fake authentication data for X11 forwarding. $ xhost - access control enabled, only authorized clients can connect
tu modifies le fichier /etc/password qui contient la ligne :
toto::::/bin/bash
en
toto::::/bin/su
Comme cela, il faut connaître les deux mots de passes (toto et root) pour se connecter.
Sous debian : « apt-get install samba samba-common »
Samba est une suite de logiciels libres qui fournit les mêmes services de gestions de dossier et d’impression que les clients de SMB/CIFS (clients microsoft). Ceci veut dire que samba permet de partager des ressources sur un réseau comme s’il était une machine sous windows.
Le démon est le smb. Cette fois, contrairement à ftp, ssh, il faut créer un compte samba par utilisateur. On utilise en ligne de commande « smbpasswd -a username password » (je déconseille de mettre ici le mot de passe, autant ne pas le mettre, il sera demandé ensuite sans être affiché clairement et n’apparaîtra pas dans l’historique des commandes). Pour d’autres options, voir « man smbpassword » ou « smbpassword --help ».
La configuration est dans le fichier /etc/samba/smb.conf. Les fichiers par défaut sont excellents, mais beaucoup trop long. Une explication satisfaisante se trouve en faisant « man smb.conf » ou sur la page http://www.linuxfocus.org/Francais/March2002/article177.shtml. Un livre complet en ligne sur samba : http://www.oreilly.com/catalog/samba/chapter/book/index.html (je ne peux tout dire ici !).
Voici un exemple :
[global]
workgroup = Maison
# netbios name = troumad # inutile, c'est déjà le nom du pc!
server string = Samba Server %v
interfaces = 192.168.1.1 # c'est la carte réseau qui a cette adresse uniquement qui va servir
hosts allow = 192.168.1. # uniquement pour les ordinateurs d'adresse Ip 192.168.1.XXX
# on peut exclure des machines de l'accès au réseau avec EXCEPT
#d'autres possibilités existent : voir le manuel man smb
#bind interfaces only = Yes
encrypt passwords = Yes
log file = /var/log/samba/log.%m
max log size = 50
socket options = TCP_NODELAY SO_RCVBUF=8192 SO_SNDBUF=8192
dns proxy = no
# guest account = no
printcap name = cups
printing = cups
#local master = yes
preferred master = yes
domain master = yes
domain logons = yes
#logon script = logon.bat # à ne décommenter que si un script est vraiment là!
# Activer un serveur Wins pour la résolution des noms NetBios
name resolve order = wins lmhosts bcast
#wins support = no
# si oui, ne pas déclarer l'adresse IP d'une autre machine comme étant serveur Wins
# wins server = xxx.xxx.xxx.xxx# accès multi utilisateur
# share modes = yes
# choisir le mode de sécurité : user ou share
security = user
os level = 60 # assez haut pour être supérieur aux autres
#map to guest = bad user
#smb passwd file = /etc/samba/smbpasswd
client code page = 850 # pour nos petits caractères français
character set = ISO8859-1
#printer admin = @adm
#load printers = yes
[homes]
# cache les fichiers cachés au sens Linux, commençant par un point
hide dot files = yes
comment = Repertoire personnel # comentaire
read only = No
browseable = No
create mode = 0700
[partage] # Ce répertoire aura donc pour nom de partage Partage
comment =Partage
# Le répertoire à partager est /maison/ftp_fdd
path = /maison/ftp_fdd
# il pourra être accessible par tous les utilisateurs
# liste des utilisateurs autorisés (avec ou sans virgule)
#valid users =
# tout le monde si cette ligne n'est pas mise
# A moins de déclarer des utilisateurs interdits d'accès
#invalid users =
# on pourra y écrire (bien sûr par ceux qui peuvent y accéder..)
writeable = yes
# les permissions par défaut des fichiers créés (le mot mode peut être remplacé par mask
create mode = 0740
#
create mask=770 : droits par défaut d'un fichier créé sur le
partage
# directory mask =770 : pareil pour les répertoires (x
est obligatoire pour le propriétaire)
[printers]
comment = All Printers
path = /var/spool/samba
create mask = 0700
printable = Yes
print command = lpr-cups -P %p -o raw %s -r
# using client side printer drivers.
browseable = No
[print$]
path = /var/lib/samba/printers
write list = @adm root
[pdf-generator] # pour avoir une imprimante pdf gratuite...
path = /var/tmp
guest ok = No
printable = Yes
comment = PDF Generator (only valid users)
#print command = /usr/share/samba/scripts/print-pdf file path win_path recipient IP doc_name &
print command = /usr/share/samba/scripts/print-pdf %s ~%u //%L/%u %m %I "%J" &
Pour des partages, il est possible de se référer à des groupes NIS ( voir XVIII) serveur NIS ) où à des groupes UNIX définis sur le serveur samba. Pour cela, il faut mettre @ (NIS ou à défaut UNIX), & (NIS uniquement) ou + (UNIX uniquement) devant le nom du groupe. Voir « man smb.conf » pour plus de précisions.
Après avoir redémarré le démon smb : « systemctl restart samba » ou « /etc/init.d/smb restart » avec une ancienne version, regardez votre configuration avec : « testparm ».
Il est entièrement
possible à un PC sous LINUX de récupérer un partage windows comme
tout autre PC windows. Ceci est fait par le client Samba. Vous avez
un exemple au X.B)1)
Pour pouvoir faire des montages, en ligne de commande :
mount -t cifs //192.168.2.1/scann /mnt/w
mount -t cifs //192.168.2.1/scann /mnt/w -o user=troumad
Dans le premier cas c’est un partage public, dans le second, c’est un partage privé. Il est possible d’y rajouter en plus de l’utilisateur le mot de passe visible dans la commande, mais, je le déconseille. Il sera demandé après dans le prompt et ne s’affichera pas sur l’écran.
De plus, pour interagir avec un domaine, un système WinNT/2000/XP doit en être membre. Cette appartenance se réalise par l’intermédiaire d’un compte de machine, similaire à un compte utilisateur.
Il faut donc créer un compte, pour chaque machine cliente. Exemple pour la machine cliente sous WinXP ayant pour nom netbios posteclient :
useradd posteclient$ -d /dev/null -g machines -c Machine -s /bin/false
Le groupe machines doit avoir été préalablement créé (le nom de ce groupe a peu d’importance…)
Le $ qui suit le nom netbios est très important : il symbolise un compte machine.
Ce qui aura pour effet de créer une ligne dans les fichiers /etc/passwd :
posteclient$:x:510:150::/dev/null:/bin/false
/etc/shadow : posteclient$:!!:12352:0:99999:7:::
Heureusement, on peut réaliser cette dernière opération automatiquement à partir du paramètre ;
add user script = /usr/sbin/useradd %m$ -g machines -c Machine -d /dev/null -s /bin/false
%m étant une variable récupérant le nom netbios de la machine qui se connecte... dans smbpasswd
Attention, dernière chose, il y a une manipulation au niveau de la base de registre à faire sous Windows XP afin que ce dernier puisse se connecter à un contrôleur de domaine :
Démarrer/Exécuter/regedit
Mettre la clé suivante à 1 :
HKEY_LOCAL_MACHINE/SYSTEM/CurrentControlSet/Services/Netlogon/Parameters/requiresignorseal
http://tice.edres74.ac-grenoble.fr/rubrique.php3?id_rubrique=135
http://wiki.mandriva.com/fr/Linux-Apache-MySQL-PHP
Un serveur http est un serveur de pages WEB (html, htm...). On peut aussi mettre un serveur php et un autre MySQL très facilement afin de bénéficier du couple apache (php)/MySQL (base de donnée). Avec Mageia, le rpm à installer est apache : « urpmi apache » ou « urpmi apache2 » si ce dernier existe. Sous debian, il faut faire « apt-get install apache2 »
Le démon du serveur apache sous mageia est httpd : Usage: systemctl restart httpd (/etc/init.d/httpd {start|stop|restart|reload|graceful|condreload|closelogs|update|condrestart|status|extendedstatus|configtest|configtest_vhosts|semcleanrestart|debug|show_defines} avec les vieilles versions). Sous Debian, le nom est apache.
Normalement, sans modification de votre part, lors du lancement du serveur apache, vous aurez un site internet sur votre PC. L’emplacement des données du site est souvent /var/www/html sous Mageia ( /var/www/apache2-default sous de vieilles debian).
Sur une Mageia, les fichiers de configurations se trouvent sur « /etc/httpd/conf/ » et avec debian à « /etc/apache2 ». Ces fichiers parlent toujours de répertoires par rapport à la racine de l’ordinateur.
Si à l’écran paraît ce message "Could not reliably determine the server's fully qualified domain name,using 127.0.0.1 for ServerName", il suffit de taper en root (en remplaçant bien sûr le mot exemple par ce que vous voulez) :
[root@ordi ~]# echo "ServerName www.exemple.tld">>/etc/httpd/conf/httpd.conf
Si vous avez un répertoire sans fichiers d’entrée du type « index.php » ( indiqués par le champ « IfModule mod_dir.c » du fichier /etc/httpd/conf/commonhttpd.conf sur Mandrake ou/etc/apache2/sites-available/000-default.conf sur debian ) , il est alors possible qu’un appel à ce répertoire liste tous les fichiers contenus dans ce répertoire. Ceci peut être gênant. Vous pouvez alors intervenir sur ce comportement en modifiant le fichier de configuration précédemment cité soit la configuration de la racine de votre site, le champ « <Directory /chemin du site> », soit la racine de l’ordinateur « <Directory /> » le paramètre option sur lequel il faut intervenir : « Options -Indexes autres_options » où le « - » déclare que l’option est désactivée et « Indexes » permet l'affichage (listing) du contenu du répertoire s’il n’existe pas de fichier d’entrée. Avec debian, on trouve cette option dans le fichier suivant : /etc/apache2/apache2.conf .
Je conseille aussi de redéfinir vos pages d’erreur afin d’en faire de personnelles pour que votre système soit le moins facilement identifiable. Un message du genre : Apache/2.2.3 (Debian) DAV/2 PHP/5.2.0-8+etch7 Server at 192.168.2.1 Port 80 , indiquera immédiatement à un hacker potentiel que votre système est une Debian Etch avec la version du php et du serveur DAV. Il ne lui restera plus qu’à faire une recherche sur d’éventuelles failles de sécurité si votre système n’est pas à jour. Cette modification se fait dans le fichier /etc/apache2/apache2.conf sous Debian et /etc/httpd/conf/httpd.conf sous Mandriva aux lignes suivantes :
#ErrorDocument 500 "The server made a boo boo."
#ErrorDocument 404 /missing.html
#ErrorDocument 404 "/cgi-bin/missing_handler.pl"
#ErrorDocument 402 http://www.example.com/subscription_info.html
ErrorDocument 404 /index.php
ErrorDocument 403 /index.php
Cette modification peut aussi être protégée en annulant ou simplifiant le message avec les directives « ServerSignature Off » ou « serveurtoken prod ». Voir : http://httpd.apache.org/docs/2.0/mod/core.html#serversignature.
Vous pouvez aussi avoir un site par compte, pour cela, il suffit de mettre dans le répertoire personnel de chaque compte un répertoire ~/public_html. Le site général sera à http://adresse, celui de l’utilisateur 'lambda' sur http://adresse/~lambda. L’adresse peut être l'adresse reconnue par le serveur DNS (le nom de la machine), l'adresse Ip et même localhost en local.
À partir de la version 2006 :
Installation : urpmi apache-mod_userdir
Modifications dans le répertoire /etc/httpd/modules.d (comme les modules en général) le fichier 67_mod_userdir.conf.
Sous debian :
# cd /etc/apache2/mods-enabled
# ln -s ../mods-available/userdir.* .
# /etc/init.d/apache2 restart
Il est possible qu'un serveur apache réponde à plusieurs noms et donne une réponse différente en fonction du nom par lequel il est appelé : http://www.lycee.org ou http://www.geii.org. La redirection peut se faire assez facilement si vous possédez un nom de domaine (Voir le chapitre sur le DNS). Pour différencier les différents noms, le serveur httpd se configure assez simplement sous Mandriva alors que sous debian, cette manipulation semble plus compliquée car la configuration paraît plus poussée, j'en parlerai plus loin. Avec Mandriva, dans le fichier /etc/httpd/conf/httpd2.conf, il faut enlever les lignes NameVirtualHost, DocumentRoot et ServerName et mettre les lignes suivantes dans /etc/httpd/conf/vhosts/Vhosts.conf (attention la ligne Include conf/vhosts/Vhosts.conf de httpd2.conf doit être décommentée) :
NameVirtualHost * # * parce que j'ai une adresse ip qui n'est pas fixe
<VirtualHost *> # Premier définit : répond à l'appel par mon adresse ip : http://xxx.xxx.xxx.xxx
# ainsi qu'a tout autre appel sur le PC non défini par un virtual host
DocumentRoot /maison/bs/Troumad
ServerName www.lycee.org # répond aussi à http://www.lycee.org
</VirtualHost>
<VirtualHost *> # lors d'un appel par http://www.geii.org
DocumentRoot /maison/geii/public_html
ServerName www.geii.org
</VirtualHost>
NameVirtualHost 192.168.1.1
<VirtualHost 192.168.1.1> # un autre juste pour le réseau local!
DocumentRoot /maison/ftp_fdd/public_html
</VirtualHost>
NameVirtualHost 127.0.0.1
<VirtualHost 127.0.0.1> # pour le localhost : mon site principal, pour le travail
DocumentRoot /maison/bs/Troumad
ServerName localhost
</VirtualHost>
<Directory "/repertoire_du_site"> # voir le paragraphe « Protection intranet-extranet »
allow from all
order allow,deny
AuthType Basic
</Directory>
Avant de relancer le démon apache, on peut essayer la commande 'httpd2 -t' qui permet de vérifier la syntaxe des fichiers de configuration d'apache.
Sous debian, c'est le fichier /etc/apache2/sites-available/default qui contient une grosse section pour le répertoire /var/www/apache2-default l'endroit où est stoqué par défaut le site web.
Comme en plus, j’ai modifié l’emplacement habituel des répertoires, j’ai dû aussi intervenir dans le fichier /etc/httpd/conf/commonhttpd.conf.
Le 'localhost' a changé de place et n’est plus à /var/www/html (c’est un conseil pour des raisons de sécurité), je dois remplacer les occurrences de « DocumentRoot » qui étaient « /var/www/html » par « /maison/bs/Troumad » :
# This should be changed to whatever you set DocumentRoot to.
#
<Directory /maison/bs/Troumad>
Le répertoire personnel a aussi changé, je dois changer « /home/*/public_html » par « /maison/*/public_html ».
En revanche pour pouvoir utiliser le php avec ses droits d'écritures sur /maison/bs/Troumad, j'ai dû attribuer l’arborescence toute entière à apache : « chgrp -R apache /maison/bs/Troumad/* ». Cette manipulation, j’ai du la faire sous root.
Documentation sur le php : http://www.dwam.net/docs/php_fr/
Si vous avez un serveur http avec une charge inhabituelle (faible ou grosse), vous pouvez agir sur les paramètres suivants (ici pour un -trop- petit serveur) :
<IfModule prefork.c>
StartServers 2
MinSpareServers 1
MaxSpareServers 3
Les nombres sont initialement 5, 5 et 10. Pour une grosse charge, vous pouvez les augmenter. Attention, ces process utilisent beaucoup de mémoire !
Si vous avez un intranet et que vous souhaitez qu’il soit visible de l'extérieur uniquement par mot de passe, vous pouvez le configurer comme ça :
<Directory /maison/sites/linux>
Options -Indexes FollowSymLinks MultiViews
AllowOverride All
Order deny,allow
deny from all
allow from 192.168.1.1/255.255.255.0
#réseau interne en 192.168.1.X
AuthType Basic
AuthUserFile /etc/httpd/conf/htpasswd.users
# emplacement du fichier de mot de passe
AuthName "Demander l'autorisation"
require valid-user
satisfy any
</Directory>
<Directory /maison/sites>
Options -Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
Allow from all
</Directory>
Pour rentrer les mots de passe : « htpasswd /usr/local/apache/conf/htpasswd.users troumad ». Après vous devrez rentrer le mot de passe. Ceci est dû au paramètre « satisfy any ». Il faut mettre le paramèrte « -c » si on veut créer u nouveau fichier.
Après la première déclaration qui ne donne accès qu'aux utilisateurs authentifiés à tous ce qui se trouve dans /maison/sites/linux, vous pouvez toujours faire une section pour un site particulier pour y attribuer des droits spécifiques, même s'il se trouve dans /maison/troumad. Ici, j'ai donné le droit à l'utilisateur troumad d'accéder à tout ce qui est dans /maison/sites.
Le répertoire des logs de httpd est /var/log/httpd. Vous pouvez regarder les sorties existantes ou en créer d'autres comme je l'indique si dessous.
Dans le fichier de configuration commonhttpd.conf avant Mandriva 2006 et dans httpd.conf pour mandriva 2006, repérez les lignes avec « LogFormat » comme « LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined ». Le dernier mot « combined » est le nom de la forme de sortie, pour activer cette ligne, rajoutez après : « CustomLog logs/combined_log combined » et créez le fichier combined_log dans le répertoire delog de httpd. Faîtes ceci pour les différentes lignes avec LogFormat, repérez et sélectionnez les options qui vous conviennent pour faire votre fichier de log.
Pour pouvoir faire des pages en php, il faut installer mod_php : « urpmi apache2-mod_php » ou « urpmi apache-mod_php » . Sa configuration est dans le fichier : /etc/php.ini.
Pour debian : http://www.destination-linux.org/article30.html
Installons les paquets requis (attention, à la version de php, le 4 peut être remplacé par 3, 5 ...) :
apt-get install apache2 php mariadb-server
Remarque : mysql-server a été remplacé par mariadb-server car mysql est passé sous le giron d’oracle.
apt-get install libapache2-mod-php
Activons le support de PHP dans Apache 2 :
ln -s /etc/apache2/mods-available/php4.load /etc/apache2/mods-enabled/php4.load
ln -s /etc/apache2/mods-available/php4.conf /etc/apache2/mods-enabled/php4.conf
La version de php a sûrement changée depuis !
Relancez apache :
/etc/init.d/apache2 restart
La configuration de php se fait par le fichier /etc/php4/apache2/php.ini.
Voici un petit fichier d’une ligne en php vous fournira toutes les informations utiles sur votre serveur :
<? echo phpinfo(); ?>
Vous verrez qu’il y a plein de modules qu’on peut rajouter à php comme la gestion d’images avec php-gd ou la gestion d’une base de données MySQL ce que nous verrons après le serveur httpd.
Pour voir l’affichage des erreurs php (programmation ou autre), il faut modifier le php.ini et mettre "display_errors" à On.
Remarque : php peut aussi s’exécuter en ligne de commande http://www.manuelphp.com/php/features.commandline.php
Il est aussi possible de configurer votre serveur afin qu’il affiche ou non les erreurs durant l’exécution des codes php avec le fichier php.ini avec les lignes suivantes :
error_reporting = E_STRICT | E_ALL
display_errors = on
La première configurant les erreurs à afficher et la seconde active l’affichage des erreurs.
WebDAV (Web-based Distributed Authoring and Versioning) est un ensemble d’extensions HTTP permettant aux utilisateurs d’éditer et de gérer des fichiers sur des serveurs Web distants. WebDAV (généralement appelé DAV) prend en charge l'utilisation et la manipulation de documents par plusieurs utilisateurs via le Web. Pour plus d’informations sur DAV, reportez-vous au site Web WebDAV Resources à l'adresse http://www.webdav.org/.
Le module mod_dav offre des capacités DAV pour un serveur Web Apache. Pour plus d’informations sur le module mod_dav et les options de configuration, reportez-vous au site Web mod_dav à l'adresse http://www.webdav.org/mod_dav/.
Pour l’installer : « urpmi apache-mod_dav ». ou « [root@serveur][/etc/apache2/mods-enabled]# ln -s /etc/apache2/mods-available/dav* . ».
Le fichier DAVLockDB, la base de données de verrouillage pour WebDAV, est stockée sous Mandriva sur /var/lib/dav/lockdb. La configuration de WebDAV se fait dans le fichier « /etc/httpd/modules.d/45_mod_dav.conf » ( « /etc/httpd/conf.d/45_mod_dav.conf » sur des anciennes versions ) sur Mandriva ou « /etc/apache2/dav_fs.conf » sous debian.
<IfModule mod_dav_fs.c> # ligne inutile pour debian
DavLockDB /var/lib/dav/lockdb
<Directory "/maison/dav">
DAV On
</Directory>
Vous devez aussi rajouter les options de contrôle d’accès, mais pour ma part, elles sont définies pour tous les sites hébergés par mon PC dans /etc/httpd/conf/commonhttpd.conf :
<Directory /maison/*>
AllowOverride All
Order deny,allow
deny from all
allow from 192.168.1.1/255.255.0.0
# Je laisse l'accès à mon réseau interne considéré comme sur
allow from 127.0.0.1
AuthType Basic
AuthUserFile /etc/httpd/conf/htpasswd.users
# sous debian, cette ligne demande l'activation de authn_file.load
AuthName "Demander l'autorisation"
require valid-user
satisfy any
</Directory>
J'ai créé un virtual host juste pour le serveur WebDAV dans /etc/httpd/conf/vhosts.d/00_default_vhosts.conf ( /etc/httpd/conf/vhosts/Vhosts.conf pour des versions plus vieilles) :
NameVirtualHost *
<VirtualHost *>
DocumentRoot /maison/dav
ServerName dav.lycee.org
</VirtualHost>
Sous Mandriva, il faut commencer par installer le rpm davfs2.
Il est possible de créer un serveur sécurisé par SSL (Secure Socket Layer). Un tel serveur possédera un url commençant par https:// (s pour « sécurisé » !). SSL est un procédé de sécurisation des transactions effectuée par Internet. Il a été mis au point par Netscape, Mastercard, Bank of america, MCI et Silicon Graphics. Tout comme SSH, il repose sur un procédé de cryptage par clé publique. Son utilisation est totalement transparente pour l’utilisateur. Ce dernier ne s’en rendra compte que lorsque le navigateur l’avertira qu’il pénètre dans une zone sécurisée et lui demandera de valider le certificat du site visité (image ci-contre.
De même, le navigateur
indiquera par un cadenas
![]() qu’il est connecté à un site sécurisé par SSL.
qu’il est connecté à un site sécurisé par SSL.
La sécurisation se fait par échange de clés entre le client et le serveur. Le client se connecte au serveur sécurisé qui lui renvoie un certificat contenant sa clef publique. Le client, après validation du certificat, crée une clef secrète aléatoire. Cette clef est chiffrée à l’aide de la clef publique du serveur et lui a envoyée. Le serveur est le seul à pouvoir la décrypter grâce à sa clef privée. Cette clef, commune au client et au serveur, peut alors servir pour le reste des transactions.
Si, lors de l’installation de Mandriva, vous sélectionnez l’installation d’Apache, OpenSSL, mod_ssl et PHP, un serveur sécurisé sera automatiquement installé et accessible via l'url: https://localhost. Le fichier de configuration se trouvera dans le répertoire /etc/httpd/conf.d/41_mod_ssl.default-vhost.conf.
Sinon, vous allez devoir installer le module apache mod_ssl « urpmi mod_ssl » et openssl « urpmi openssl ». Ensuite, vous devez modifier le fichier de configuration d'Apache /usr/local/httpd/conf/http2.conf comme suit :
Listen 443
<IfDefine HAVE_SSL> permet de charger le module mod_ssl si ce n'est déjà fait.
<IfModule !mod_ssl.c>
LoadModule ssl_module extramodules/mod_ssl.so
</IfModule>
</IfDefine>
<IfModule mod_ssl.c> si le module a été chargé, exécuter ce qui suis.. (facultatif)
<VirtualHost *:443>
port 443 = port sécurisé
DocumentRoot "/maison/Troumad/sitesecurise"
ServerName www.lycee.org:443
ServerAdmin root@localhost
ErrorLog logs/ssl_error_log où trouver le fichier de log
SSLEngine on activation de SSL
SSLCipherSuite ALL:!ADH:!EXPORT56:RC4+RSA:+HIGH:+MEDIUM:+LOW:+SSLv2:+EXP:+eNULL
liste des différents modes de cryptages autorisés
SSLCertificateFile /etc/ssl/apache/server.crt où trouver le fichier contenant le certificat du serveur
SSLCertificateKeyFile /etc/ssl/apache/server.key où trouver le fichier contenant la clé publique du serveur
</VirtualHost>
</IfModule>
Si vous désirez faire cohabiter un serveur crypté avec un serveur non crypté, il peut se révéler utile d’ajouter la ligne SSLEngine off dans le virtualhost du serveur non crypté.
Il n'est pas possible d’installer plusieurs serveurs sécurisés HTTPS sur une seule adresse IP. Il existe cependant une solution: Apache-SSL (http://www.apache-ssl.org) qui se présente comme un patch pour Apache.
https://www.vincentliefooghe.net/content/activer-un-acc%C3%A8s-https-sur-apache
Il faut avoir un nom de domaine pleinement qualifié (nous utiliserons troumad.org dans la suite).
On commence par activer le lien entre le module SSL/TLS et apache2 :
a2enmod ssl
/etc/apache2/ports.conf devrait être configuré pour écouter le port 443 utilisé par le protocole https.
La commande suivante va demander la saisie de plusieurs paramètres. Le plus important est le name (Common Name). Il faut mettre à ce niveau le nom complet du host. Par exemple pour un serveur accédé par l'URL troumad,org
# openssl req -new -x509 -days 365 -nodes -out /etc/ssl/certs/troumad.crt -keyout /etc/ssl/private/troumad.key
Generating a RSA private key
..........................................................+++++
..........................................................+++++
writing new private key to '/etc/ssl/private/troumad.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:FR
State or Province Name (full name) [Some-State]:Rhône
Locality Name (eg, city) []:Genas
Organization Name (eg, company) [Internet Widgits Pty Ltd]:troumad
Organizational Unit Name (eg, section) []:Troumad
Common Name (e.g. server FQDN or YOUR name) []:troumad.org
Email Address []:troumad@troumad.org
Remarque : il s’agit ici de certificat auto-signé. Généralement cela signifie que les navigateurs internet vont émettre une alerte de sécurité. En effet, afin de garantir l’authenticité du certificat, ce dernier est signé numériquement soit par une autorité de certification reconnue (une AC – autorité de certification – ayant un prix assez élevé) soit par le détenteur du certificat lui-même. Dans ce dernier cas, on parlera de certificat auto-signé.
Après avoir créé une clef par nom de serveur, on les protège toutes en écriture :
chmod 440 /etc/ssl/private/*
À la suite de cela, on crée un virtual host sécurisé.
Sous debian, on crée ce lien « default-ssl.conf -> ../sites-available/default-ssl.conf » dans « /etc/apache2/sites-enabled/ » en modifiant à sa guise le document d’origine).
Voici un exemple :
# vhost https
<VirtualHost *:443>
DocumentRoot /var/www/webmail
ServerName webmail.mondomaine.com
ServerSignature Off
ErrorLog ${APACHE_LOG_DIR}/error_webmail.log
LogLevel info
CustomLog ${APACHE_LOG_DIR}/access_webmail.log combined
SSLEngine on
SSLCertificateFile /etc/ssl/certs/mailserver.crt
SSLCertificateKeyFile /etc/ssl/private/mailserver.key
</VirtualHost>
Une fois ceci fait, on relance le service apache :
systemctl reload apache2
ou, plus fort :
systemctl restart apache2
On peut vérifier le résultat avec
systemctl status apache2
Remarque : sous Mageia, ce n’est pas le service apache2, mais le service httpd.
Il est parfois utile d’avoir le serveur apache lancé même si on n'a pas internet. Par exemple pour travailler un site sur son portable en voyage. Malheureusement, la configuration par défaut de Mandriva ne la permet pas !
Il faut modifier les lignes « listen » afin de ne garder que le port. Par exemple, dans /etc/httpd/conf/httpd.conf :
Listen 80
/etc/httpd/modules.d/40_mod_ssl.conf :
Listen 443
Un des intérêts du php est de pouvoir interagir avec plusieurs bases de données dont entre autre mysql (libre et multisystème) et access (propriétaire et ne tourne que sous windows). Nous allons parler de MySQL.
Pour installer MySQL « urpmi mariadb » (mariadb est un fork libre de MySQL) sous Mandriva/Mageia ou « apt-get install mysql-server » sous debian et pour le lien entre php et MySQL : « urpmi php-mysql » ou « .apt-get install phpX-mysql » (X étant la version de php). Après il faut relancer le démon apache pour qu'il prenne en compte MySQL et lancer le démon mysql, on peut même demander à MySQL de se lancer automatiquement à chaque démarage : « /etc/init.d/httpd restart;/etc/init.d/mysql start;chkconfig mysql » (pensez avec les nouvelles versions à utiliser systemctl pour lancer les démons à la place des fichiers de init.d .
Documentations sur MySQL :
http://dev.nexen.net/docs/mysql/annotee/manuel_tocd.php
http://www.linux-pour-lesnuls.com/adminmysql.php
http://www.ac-creteil.fr/reseaux/systemes/linux/lamp/tp-mysql.htm
...
une base MySQL est un document de travail important, il faut donc savoir où elle est stockée. Normalement, c'est dans /var/lib/mysql, sinon un « locate » sur des fichiers type func.MYD, host.MYD, tables_priv.MYD, user.MYD, columns_priv.MYI, db.MYI, func.MYI permettront de trouver les tables à coup sur. Attention, lorsqu'on copie les bases d'un serveur vers un autre, ne pas oublier aussi de les attribuer à l'utilisateur mysql.
Les fichiers de configuration sont : /etc/my.cnf et /etc/sysconfig/mysqld.
Pour
voir les variables d'environnement : « SHOW
VARIABLES; »
comme
instruction quand on est dans la base de données.
Attention,
lors d’une copie de ses répertoires :
-
il faut modifier l’utilisateur et le groupe propriétaire des
fichiers pour que le service MySQL puisse y accéder avec cette
nouvelle configuration.
-
sous debian il y a un utilisateur particulier qui est renseigné dans
/etc/mysql/debian.cnf.
Plus
de sécuritéil
vaut mieux pour la sécurité :
accès
général :
mysql>
GRANT ALL PRIVILEGES ON *.*
TO
'nouvel_adm'@'%'
IDENTIFIED
BY 'mot_de_passe' WITH GRANT OPTION;
Nota : ne pas modifier le paramètre '%'.
accès
sur une base :
mysql>
GRANT SELECT, UPDATE, INSERT, DELETE ON base_de_données.*
TO
'nouvel_utilisateur'@'localhost'
IDENTIFIED
BY 'mot_de_passe';
Nota : ne pas modifier le
paramètre 'localhost'.
mysql>
FLUSH PRIVILEGES;
mysql>
QUIT;
(source
http://wiki.mandriva.com/fr/Linux-Apache-MySQL-PHP)
Maintenant,
il
y a la commande mysql_secure_installation pour sécuriser le système
à partir de la ligne de commande. Les questions qui suivent vont
sécuriser l'installation de votre base de données. Vous pouvez y
répondre de la façon suivante :
"Enter current password for root (enter for none):" À la première installation, il n’y a pas de mot de passe, taper directement ‘Entrée’.
"change the root password ?" taper y et tapez un mot de passe .
"remove anonymous users" taper y
"disallow root login remotly?" taper n
"remove test database and access to it " taper y
"reload privilege tables now" taper y
Voilà ! Vous avez renseigné les paramètres nécessaires.
Parfois, la connexion sous root est impossible, c’est une histoire de protection : https://www.geek17.com/fr/content/debian-9-stretch-installer-et-configurer-mariadb-65 . Il faut supprimer le plugin unix_socket de root.
#
mysql -u root -p
Enter
password:
ERROR
1698 (28000): Access denied for user 'root'@'localhost'
sudo
mysql -u root -p
MariaDB
[(none)]> USE mysql;
Reading
table information for completion of table and column names
You
can turn off this feature to get a quicker startup with -A
Database
changed
MariaDB
[mysql]> SELECT plugin FROM user WHERE user='root';
+-------------+
|
plugin |
+-------------+
|
unix_socket |
+-------------+
1
row in set (0.00 sec)
MariaDB
[mysql]> UPDATE user SET plugin='' WHERE User='root';
Query
OK, 1 row affected (0.00 sec)
Rows
matched: 1 Changed: 1 Warnings: 0
MariaDB
[mysql]> FLUSH PRIVILEGES;
Query
OK, 0 rows affected (0.00 sec)
Voici un exemple de création de base de données MySQL en ligne de commande,; son but est d'avoir localement la même configuration que celle que vous offre free.
On commence par entrer dans la base MySQL avec la commande « mysql » (voir « man mysql » pour plus d'informations).
SET PASSWORD = PASSWORD( '**********' );
Ajout du mot de passe root sur localhost (IMPORTANT)
SHOW DATABASES;
On regarde toutes les bases existantes.
DROP DATABASE `test`;
Effacer la table test.
use mysql;
On va dans la base de gestion de mysql.
SHOW TABLES;
Vision des tables existantes dans la la base sélectionnées (ici mysql)
INSERT
INTO `user` ( `Host` , `User` , `Password` , `Select_priv` ,
`Insert_priv` , `Update_priv` , `Delete_priv` , `Create_priv` ,
`Drop_priv` , `Reload_priv` , `Shutdown_priv` , `Process_priv` ,
`File_priv` , `Grant_priv` , `References_priv` , `Index_priv` ,
`Alter_priv` , `Show_db_priv` , `Super_priv` ,
`Create_tmp_table_priv` , `Lock_tables_priv` , `Execute_priv` ,
`Repl_slave_priv` , `Repl_client_priv` , `Create_view_priv` ,
`Show_view_priv` , `Create_routine_priv` , `Alter_routine_priv` ,
`Create_user_priv` , `ssl_type` , `ssl_cipher` , `x509_issuer` ,
`x509_subject` , `max_questions` , `max_updates` , `max_connections`
, `max_user_connections` )
VALUES ('localhost', 'troumad',
PASSWORD( 'MOT_DE_PASSE' ) , 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N',
'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N',
'N', 'N', 'N', 'N', '', '', '', '', '0', '0', '0', '0')
Création de l'utilisateur 'nom_de_compte' avec le mot de passe 'mot_de_passe'
CREATE DATABASE `mon_de_compte`;
Pour créer une base avec le même nom que l'utilisateur
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP ON mon_de_compte.* TO mon_de_compte;
Pour donner tous les droits à l'utilisateur sur sa base : information mise dans la table mysql.db
le premier est le nom de la base de données.
Pour
demander au serveur de recharger les tables de droits
use mon_de_compte;
CREATE
TABLE `test` (
` id` MEDIUMINT(8) UNSIGNED NOT NULL
AUTO_INCREMENT,
`date` DATE,
`heure` TIME,
`systeme`
VARCHAR(255),
`adresse` VARCHAR(15),
`vient_de`
VARCHAR(255),
`visiteur` MEDIUMINT(8) UNSIGNED DEFAULT '0' NOT
NULL,
`fait_sa_visite` SMALLINT(5) UNSIGNED,
INDEX (`
id`)
);
Pour faire un compteur de visite (Un exemple, mais, c'est à l'utilisateur de faire ce qu'il souhaite !) .
DROP TABLE `test`;
Pour effacer la table test (c'était un exemple inutile).
Exit;
Arrêter MySQL.
On peut sauver (respectivement remplir) une base de donnée de la manière suivante :
mysql -h localhost -u root -pmot_de_passe troumad > sauvegarde
mysql -h localhost -u root -pmot_de_passe troumad < sauvegarde
MySQL peut être géré par une interface graphique phpMyAdmin dont le site officiel est : http://phpwizard.net/projects/phpMyAdmin/. L'intérêt de cette interface est qu'elle nous informe des requettes MySQL qu'elle fait. Sous Mandriva, nous pouvons l'installer en faisant tout simplement : « urpmi phpmyadmin ». Le logiciel, s'installe sur /var/www/html/admin/phpMyAdmin, donc accessible en configuration initiale de http par « http://localhost/phpmyadmin ». Je conseille cependant le mettre ou vous voulez dans votre arborescence et le mettre une entrée dessus dans votre fichier « /etc/httpd/conf/httpd2.conf » :
<VirtualHost 127.0.0.1> # Une adresse vers mon php...
DocumentRoot /maison/bs/mes_sites/phpMyAdmin
ServerName phpMyAdmin.monphp.org
</VirtualHost>
Il faut informer dans le fichier le champ $cfg['blowfish_secret'] en y mettant la chaîne de caractères de son choix 'maximum 46 caractères.
Maintenant, l'utilisateur troumad peut lire et modifier la base de données troumad, le service fourni par ovh par exemple. Pour l'accès par phpMyAdmin à cette base de données soit effectif, il faut configurer le fichier config.inc.php :
$cfg['Servers'][$i]['auth_type'] = 'cookie'; // Authentication method (config, http or cookie based)?
Sous debian : PhpMyAdmin est fourni avec un script d'assistance à la configuration. Ce script peut être accédé à l'adresse « http://localhost/phpmyadmin/scripts/setup.php ». L’utilisation de ce script impose une authentification.
Regardez dans les fichiers de configuration du serveur apache les restrictions données pour l’accès à phpMyAdmin. Ces restrictions sont normales car une base de données est un ensemble de données très sensibles et phpMyAdmin est une interface simple pour la maîtriser.
Une fois MySQL et le php installés, vous pouvez installer « sans frais » un wiki ou un forum, regardez par exemple http://www.phpbb-fr.com/ ou http://www.wikini.net/ .
Dans les anciennes versions, il faut éditer le fichier « /etc/sysconfig/mysqld » et commenter la ligne
# MYSQL_OPTIONS="--skip-networking".
Maintenant, tout est dans /etc/my.cnf .
Et dans /etc/my.cnf , section [mysqld], la ligne suivante restreint le port d'écoute (en cas de présence de plusieurs Ip) :
bind-address=ip_du_serveur
En revanche ceci ouvre tous les ports (par défaut chez moi ):
bind-address=0.0.0.0
Ensuite, il faut donner les droits d'accès à partir de l'extérieur à un utilisateur :
use mysql;
GRANT ALL ON *.* to 'userdbt'@'192.168.0.1' IDENTIFIED BY 'tititoto';
Modification de la table mysql.user .
L'utilisateur userdbt au mot de passe tititoto peut accéder à toutes les bases à partir du PC 192.168.0.1
Vous pouvez restreindre les bases de données (recommandé), en remplaçant le *.* par la_base_permise.*
Vous pouvez permettre l'accès de tous les ordinateurs en remplaçant le '192.168.0.1' par '%'.
Après, le changement des fichiers de configuration, il faut relancer le service MySQL :
/etc/init.d/mysqld restart ou systemctl restart mysql
Finalement, il faut ouvrir le port 3306 du mur de feu pour les interfaces qui pourront accéder à la base de données.
On peut tester le partage en ligne de commande par :
mysql -h Ip_du_serveur -u nom_de_l'utilisateur -p
C'est un module pour consulter à partir de programmes extérieurs, différents modèles de bases de données mêmes distants dont MySQL. Il existe une version windows qui permet l'accès aux bases de données qui sont sur des serveurs Linux ou autre à partir d'ordinateurs sous windows. Parmi les programmes extérieurs qui utilisent ODBC, il y a OpenOffice.org (voir http://fr.openoffice.org/Documentation/How-to/indexht.html section base de données).
Pour installer ODBC, « urpmi myodbc » sous Mandriva ou « sudo apt-get install libmyodbc unixodbc-bin » sous ubuntu, mais parfois, il est intéressant d'aller chercher le dernier driver sur le site officiel (comme aujourd'hui, car il marche mieux) : http://www.unixodbc.org/.
Les fichiers de configuration sont odbcinst.ini qui définit les drivers pour les différentes bases de données et odbc.ini qui définit les différents accès aux bases de données (sous ubuntu, une version de ce fichier est à /usr/share/libmyodbc/odbcinst.ini, il suffit alors de faire : sudo cp /usr/share/libmyodbc/odbcinst.ini /etc/ )
[root@portable][/etc]# cat /etc/odbc.ini
[local]
Description = Base locale
Driver = MySQL
Server = localhost
Database = troumad
Port = 3306
Socket =
Option =
Stmt =
[troumad]
Description = Base troumad
Driver = MySQL
Server = 192.168.2.1
Database = troumad
Port = 3306
Socket =
Option =
Stmt =
[root@portable][/etc]# cat /etc/odbcinst.ini
[MySQL]
Description = ODBC Driver for MySQL
Driver = /usr/lib/libmyodbc3.so.1
Setup = /usr/lib/libodbcmyS.so.1
FileUsage = 1
CPTimeout =
CPReuse =
Pour tester une connexion ODBC :
isql nom_de_base(trouvé dans odbc.ini) mon_utilisateur mot_de_passe
nfs est un système permettant d’effectuer un partage de certains dossiers par un réseau. C’est un protocole Unix qui n’est pas reconnu naturellement par les PC sous Windows, c’est pour cela que Samba a été développé.
Les qualités de nfs génèrent ses propres défauts : sa simplicité. Ses défauts deviennent gênant actuellement avec la démocratisation du Wi-Fi et autres moyens d’entrer dans un réseau. En effet, il suffit de pouvoir se connecter sur un réseau, de choisir une bonne adresse Ip pour accéder à un partage nfs sur un PC sur lequel on a tous les droits pour pouvoir tout lire/écrire/modifier à partir du moment qu’on a le bon uid. La seule protection de nfs étant basée sur les uid et gid, on peut donc créer les utilisateurs ayant l'uid approprié et appartenant au bon groupe pour pouvoir accéder où on veut.
Je décris donc à la fin de ce chapitre des méthodes plus sécurisées de partages. Elles me semblent d’autant plus intéressantes qu’elles offrent beaucoup plus de possibilités. Au sein d’un réseau Linux il est possible aussi d’utiliser Samba pour le partage de fichiers.
Maintenant, avec les noyaux 2.6, il existe NFSv4. J'en parle à la fin de nfs.
Voir aussi : http://docs.hp.com/en/B1031-90043/ch02s05.html
Le serveur est celui qui propose un partage.
Si on n’a pas installé le rpm, il faut commencer par l'installer : c’est nfs-utils [et rpcbind (ce dernier demande un reboot de la machine)] pour Mageia et pour Debian, on a un choix de deux paquets différents :
aptitude search nfs.*server
i nfs-kernel-server - support for NFS kernel server
v nfs-server -
p nfs-user-server - User space NFS server
nfs-kernel-server c’est le serveur en espace noyau. Il est plus rapide mais peut présenter des risques car en espace noyau (sur raspbian, c’est le seul disponible).
nfs-user-server c’est le serveur en espace utilisateur. Il est plus lent mais plus sûr car en espace utilisateur.
Chacun de ces deux paquets fournit le paquet virtuel nfs-server.
Pour paramétrer un serveur NFS, c’est très simple. Vous devez éditer le fichier /etc/exports qui liste les dossiers partagés. Imaginons que vous voulez partager des documents textes qui se trouvent dans /usr/local/texte, insérez alors ceci :
/usr/local/texte *.toto.fr(rw,no_root_squash,insecure)
Cette ligne partage le répertoire /usr/local/texte pour tout le réseau toto.fr en lecture/écriture (rw), avec la possibilité donnée à root d’avoir des droits et aussi en mode insecure. Il est évident que vous ne devez pas donner ces permissions sur un serveur accessible à internet mais cela peut être bon pour l’intranet à petite échelle. Pour appliquer les changements, si NFS tourne déjà (vérifiable par « ps -aux |grep nfsd »), faîtes simplement : « exportfs -a ». Vous pouvez vérifier tous les montages par : « exportfs ». Si le démon NFS qui gère ce partage n’est pas démarré, lancez alors : « /etc/rc.d/init.d/nfs-server start » ou « systemctl start nfs-kernel-server.service »
Sur l’exemple suivant, on partage le répertoire /home à deux ordinateurs en lecture et écriture (voir « man exports » et le répertoire /opt à ces deux mêmes PC. Le partage de /opt n’est pas le même : root conserve ces droits root sur /opt s’il est sur le PC 192.168.1.1 et personne ne peut écrire sur /opt à partir du PC 192.168.1.100, on ne peut que lire.
Voici l’exemple de /etc/exports :
/home 192.168.1.1(rw) 192.168.1.100(rw)
/opt 192.168.1.1(rw,no_root_squash) 192.168.1.100(r)
Attention, les id des groupes et des utilisateurs propriétaires restent les mêmes dans un partage. On voit alors l'intérêt d’un serveur NIS qui met les utilisateurs et les groupes (entre autre) en commun pour tout un réseau.
C’est pour cela, que au début, j’ai donné des id différents en fonction des ordinateurs de la salle.
Remarque 1 : Pour être
utilisé dans des sites où les UIDs varient suivant les machines,
nfsd fournit une méthode de conversion dynamique des UIDs du serveur
en UIDs du client et inversement.
Ceci est mis en service avec
l’option map_daemon et utilise le protocole RPC UGID. Il faut que
le démon de conversion ugidd(8) soit actif sur le client
Remarque 2 : Sous Raspbian (debian pour raspberry), rpcbind ne démarre pas par défaut. C’est sûrement pour limiter l’utilisation de mémoire du petit système. Cependant, elle n’est pas vraiment importante et est indispensable pour le montage NFS. On peut le lancer manuellement :
# systemctl start rpcbind.service
Pour le faire démarrer automatiquement à chaque boot, il faut faire :
# update-rc.d rpcbind enable
On doit aussi faire :
#systemctl restart nfs-kernel-server.service
Pour permettre pour configurer un fire-wall qui commande le NFS, est-il utile de pouvoir fixer les ports employés par ces services, car plusieurs sont choisis par défaut aléatoirement. Heureusement c’est possible, bien que les méthodes pour imposer ces nombres soient différentes pour chacun des démons. Le tableau suivant présente les démons de NFS et donne l’information appropriée pour chacun d'eux.
Démon |
RPM |
Port standard |
Port suggéré |
Que changer |
|---|---|---|---|---|
portmap |
portmap |
111 |
111 |
Rien |
rpc.statd |
nfs-utils |
Aléatoire |
4000 |
Éditer /etc/init.d/nfslock ou /etc/sysconfig/nfs-commun |
rpc.nfsd |
nfs-utils |
2049 |
2049 |
Rien |
rpc.lockd |
nfs-utils & kernel |
Aléatoire |
4001 |
Éditer /etc/modprobe.conf ou /etc/modules.conf |
rpc.mountd |
nfs-utils |
Aléatoire |
4002 |
Créer ou éditer /etc/sysconfig/nfs(-server) |
rpc.rquotad |
quota |
Aléatoire |
4003 |
Installer "quota" version 3.08 ou plus et éditer /etc/rpc et /etc/services |
Pour /etc/sysconfig/nfs-commun :
STATD_OPTIONS="--port 4000"
Si ce fichier n’existe pas (ancienne version) , c'est /etc/init.d/nfslock où il faut vérifier les lignes suivantes :
start)
# Start daemons.
gprintf "Starting NFS lockd: "
daemon rpc.lockd
echo
gprintf "Starting NFS statd: "
daemon rpc.statd -p 4000
echo
touch /var/lock/subsys/nfslock
;;
Pour /etc/modprobe.conf rajouter la ligne :
options lockd nlm_udpport=4001 nlm_tcpport=4001
ou pour les versions plus anciennes /etc/modules.conf, ajouter la ligne :
options lockd nlm_udpport=4001 nlm_tcpport=4001
Pour /etc/sysconfig/nfs-server , compléter la ligne :
RPCMOUNTD_OPTIONS="--port 4002"
Si ce fichier n'existe pas (ancienne version avant mdv 2008.0), c'est le fichier /etc/sysconfig/nfs ou il faut décommenter et informer la ligne :
MOUNTD_PORT=4002
Pour /etc/rpc : « urpmi quota » et vérifier que la ligne suivante est présente :
rquotad 100011 rquotaprog quota rquota
Pour /etc/services, informer le port 4003 :
rquotad 4003/tcp # nfs
rquotad 4003/udp
Après ceci relancer les démons portmap et/ou nfs : « /etc/init.d/nfs restart ». Avec les nouvelles versions, il faut recharger le module et relancer le service nfs-server. Comme le module est en service, vous ne pouvez pas le décharger puis recharger. Vous devez donc redémarrer de l’ordinateur, ce qui est rarissime sous Linux.
Pour vérifier si les ports sont bien les bons, on peut faire : « rpcinfo -p ».
Les fichiers /etc/hosts.allow et /etc/hosts.deny sont des fichiers pour autoriser ou refuser l’accès à certains "services réseaux" (comme nfs ou portmap) pour des machines spécifiques. La partie suivante est copiée sur : http://lea-linux.org/cached/index/Reseau-partfic-nfs.html
On va interdire toutes les machines qui ne sont pas autorisées explicitement dans le /etc/hosts.deny.
Un bon vieux "ALL: ALL" interdira l’accès à tous les services à partir de toutes les machines. On peut cependant être plus précis en écrivant :
portmap:ALL
lockd:ALL
mountd:ALL
rquotad:ALL
statd:ALL
Dans le même esprit que pour le /etc/hosts.allow, ce fichier a l’architecture suivante :
[service]: [IP de la machine client]
[service]: [Nom de la machine client]
Donc pour autoriser 192.168.1.34 à se connecter à un partage NFS, on écrira :
portmap:192.168.1.34
lockd:192.168.1.34
mountd:192.168.1.34
rquotad:192.168.1.34
statd:192.168.1.34
/home 192.168.1.1(rw,insecure)
L’option insecure permet à NFS d’écouter les requêtes sur des ports au-dessus de 1024. Ici le routeur transmet les requêtes du client sur un port supérieur à 1024, ce que refuse le serveur NFS, l’option insecure lève cette restriction.
Pour sécuriser un peu l’affaire, il faut déjà filtrer le port 111 en udp et tcp au niveau du routeur en n’autorisant juste l’accès aux stations clientes autorisées.
Le client est celui qui accède au partage. Ceci dit un PC peut être simultanément client et serveur.
Une astuce de son côté pour installer un partage malgré un fire-wall consiste à couper le fire-wall le temps de la mise en route du partage et de le remettre ensuite. Sinon, il faut regarder le point précédent sur le serveur.
Sous Mandriva, tout est là par défaut. Parfois, il faut aussi faire « urpmi rpcbind »
Sous ubuntu : « sudo apt-get install nfs-common »
Ce fichier contient les informations de montage des partitions. Pour savoir ce qui est monté, vous pouvez tapez « df ». Cette instruction indiquera en plus les tailles de chaque partition montée et la place utilisée. Pour monter (accéder) en temporaire, des partages nfs, ou samba, on peut le faire avec la commande mount et plein de paramètres. Le nombre de paramètres est réduit si le partage est déjà défini dans /etc/fstab : il suffit juste de faire « mount /point_de_montage ». Le point de montage est le répertoire dans l'arborescence où on trouvera notre partage. Ce partage sera vu comme un répertoire, donc complètement transparent pour l’utilisateur.
Voici un exemple de fstab sous un noyau 2.4 (et 2.6 pour une Mandriva qui maintient la compatibilité) :
/dev/hda1 / ext3 noatime 1 1
none /dev/pts devpts mode=0620 0 0
/dev/hda5 /home ext3 noatime 1 2
none /mnt/cdrom supermount dev=/dev/hdd,fs=auto,ro,--,iocharset=iso8859-15,codepage=850,umask=0 0 0
none /mnt/floppy supermount dev=/dev/fd0,fs=auto,--,iocharset=iso8859-15,
sync,codepage=850,umask=0 0 0
/dev/hdb1 /mnt/windows vfat iocharset=iso8859-15,codepage=850,umask=0 0 0
none /proc proc defaults 0 0
//serveur/share /mnt/point_de_montage cifs uid=toto,username=toto,password=xxx 0 0
/dev/hdb5 swap swap defaults 0 0
192.168.1.1:/opt /opt nfs retry=1000,defaults 0 0
//serveur/homes /maison/bs cifs noauto,user,uid=troumad,username=bernard 0 0 # cifs remplace sur les nouvelles versions smbfs
À partir du noyau 2.6, on a effectué un grand ménage dans le répertoire /dev en créant des sous-répertoires, mais on a souvent a mis des liens symboliques afin de conserver la compatibilité. Ceci donne donc avec le nouveau noyau :
proc /proc proc defaults 0 0
/dev/discs/disc0/part1 /mnt/hda1 ext3 defaults 0 0
/dev/discs/disc0/part6 / ext3 defaults,errors=remount-ro 0 1
/dev/discs/disc0/part5 /home ext3 defaults 0 2
/dev/discs/disc0/part8 /mnt/mdk10.1 ext3 defaults 0 2
/dev/discs/disc0/part9 /mnt/mdk10.0 ext3 defaults 0 2
/dev/cdroms/cdrom0 /media/cdrom0 iso9660 ro,user,noauto 0 0
/dev/discs/disc0/part7 none swap sw 0 0
/dev/hdd /media/cdrom0 iso9660 ro,user,noauto 0 0
/dev/fd0 /media/floppy0 auto rw,user,noauto 0 0
Quand on monte une unité logique sur le système, on indique un répertoire qui doit déjà exister. S’il y a déjà des choses dans ce répertoire elles deviendront inaccessibles. C’est pour cela que la racine est montée avec le reste.
Les lignes 1 et 3 sont des partitions internes sur le premier disque dur (hda). La première sera montée à la racine :/, et la seconde est l’ensemble des répertoires personnels (/home).
Les lignes 4 et 5 prennent en compte des montages de périphériques amovibles qui sont habituellement montés en /mnt. Ici, vous pouvez les mettre ailleurs, ceci gênera bien les habitués du système.
L’antépénultième ligne est le fichier swap : partition où le système stocke les données qui devraient être dans la RAM et qui ne servent momentanément plus.
L’avant-dernière est un montage de fichier partagé avec nfs. C’est le répertoire /opt du PC dont l'adresse IP et 192.168.1.1 qu’on met nous aussi en /opt.
Vous pouvez noter les deux montages samba (dernière ligne et ligne 8) : le premier peut se faire automatiquement, car il y a le mot de passe écrit. Mais pas le second ! Voici les spécificités du second :
il n’est pas monté automatiquement, car il demande l’entrée du mot de passe, mais il peut être monté par tous si en plus /maison/bs appartient à troumad.
il correspond au montage du partage [homes] de l’utilisateur bernard
il appartiendra à l’utilisateur troumad
La première chose à faire est de renseigner le partage dans le fichier /etc/fstab. Ensuite, on monte tout simplement le partage : « mount /répertoire_de_montage » sans avoir à donner d'autres paramètres à mount.
Pour démonter une unité logique, ce qu’on ne peut le faire que si personne ne s'en sert, il faut faire « umount /répertoire_de_montage ». Si une personne s'en sert, on aura la réponse suivante : « umount : /home : périphérique occupé ». Pour savoir par qui ou par qui est occupé le partage en question, faire : « /sbin/fuser -vm /repertoire_partagé » ou « lsof » qui est pratique pour ça, car il liste les fichiers ouverts et signale quel processus l'a ouvert. On aura comme information les utilisateurs qui sont dessus (à déloger) et les PID des programmes qui l'utilisent (à tuer en dernier recours). Le recours ultime pourra être : « umount -fl /repertoire_partagé » qui force le démontage ou pire encore pour couper et remettre les partages nfs et samba : « /etc/init.d/netfs restart »
Remarque : Si vous avez
$ mount /opt
mount: RPC: Program not registered
alors que tout semble être correct, relancez le démon nfs sur le serveur. Puis recommencez... ou tentez :
mount 192.168.1.1:/opt /opt
Il est conseillé de fermer le partage sur le client avant d’éteindre le serveur. En effet un partage encore actif sur une source qui n’existe plus pose des problèmes. Par exemple, elle bloque la commande « df » qui donne l’état des différents montages.
En cas d’oubli, il y a un script disponible sous debian : /etc/init.d/umountnfs.sh .
« umount -rfl » démonte un partage récalcitrant.
un ptit topo sur le wiki de Clubic : http://www.clubic.com/wiki/NFS.
des informations sur la mise en place du proto : http://developer.osdl.org/dev/nfsv4/wiki/index.php/Main_Page
les docs utiles sur NFSv4 : http://developer.osdl.org/dev/nfsv4/site/documentation/
http://wiki.linux-nfs.org/index.php/NFSv4_Introduction
et une traduction française :http://wiki.linux-nfs.org/index.php/Nfsv4_configuration_fr
http://www.cert.fr/francais/deri/siron/fabre/KERBEROS/MainKerb.html
On peut faire un : « grep 'nfs4' /proc/kallsyms »
Si des symboles sont retournés, le service NFSv4 est présent.
http://www.supinfo-projects.com/en/2004/environnement_kerberos_linux/
Ceci n'est nécessaire que si vous voulez utiliser Kerberos 5 (krb5) avec NFSv4. (Ce qui est une bonne idée.)
Kerberos est un protocole d'authentification réseau créé par l'MIT qui utilise la cryptographie des clés au lieu des mots de passe en texte clair. Kerberos renforce la sécurité du système et empêche que des personnes non autorisés interceptent les mots de passe des utilisateurs.
urpmi krb5-server
urpmi gnome-kerberos pour disposer d'un utilitaire graphique permettant d'administrer Kerberos.
fichiers de configuration /etc/krb5.conf et /etc/kerberos/krb5kdc/kdc.conf (var/kerberos/krb5kdc/kdc.conf sur d'autres : regardez, c'est indiqué dans /etc/krb5.conf)
Notes sur Kerberos
Les heures de vos machines doivent être correctes, et indiquer la même heure. Utiliser ntp pour être sûr que c'est le cas.
Le fichier /etc/hosts doit lister tous domaines complets avec tous les attributs, c'est-à-dire que le fichier doit avoir une IP, puis le nomachine.nom.de.domaine.fr. Le nom de la machine ne doit pas apparaître dans la ligne localhost
Ne pas mélanger les minuscules avec les majuscules dans les noms de machine (DNS) dans le KDC. mamachine@domaine.org est correct, mais MaMachine@domaine.org provoquera une erreur.
http://www.labo-linux.com/index.php?page=lumieres&id=278&p=#s
Le serveur doit juste avoir sshd d'actif. Pour installer sur le client sous Mandriva : « urpmi shfs-utils » et sous ubuntu « sudo apt-get install shfs-source shfs-utils gcc-3.4 linux-headers-`uname -r`
sudo module-assistant build shfs
sudo module-assistant install shfs » (puis « man shfsmount »). Pour mettre en oeuvre le partage :
shfsmount -o uid=XXX,gid=XXX utilisateur@serveur
Vous pouvez permettre à tous les utilisateurs d'utiliser shfsmount en plaçant le bit setuid sur le binaire (attention aux droits sur le répertoire de montage) :
# chmod u+s $(which shfsmount)
Il est possible de mettre l'info dans /etc/fstab :
user@serveur /répertoire_de_montage shfs noauto,user,retry=1000 0 0
On peut aussi rajouter « uid=XXX,gid=XXX » comme option, mais c'est incompatible avec user ! Je conseille cette option user car ça évite de passer par root pour rentrer le mot de passe (ou la passphrase). L'option -P, pour changer le port de connection, est utilisable en rajoutant « P1221, » devant « noauto,user,retry=1000 » pour dire que ssh est sur le port 1221 au lieu de 22 :
bernard@linux.iutb.fr:/home /home_iut shfs P1221,noauto,user,retry=1000 0 0
En utilisant les clefs publique/privée couplées avec ssh-agent/ssh-add, il est possible de se passer de mots de passe (voir le chapitre sur ssh). Cette utilisation est même conseillée pour maintenir les connexions actives.
Une surprise de taille, tous les fichiers sont sensés vous appartenir, mais ne vous inquiétez-pas, vous ne pourrez pas surpasser vos droits sur le serveur !
Un grand avantage de cette méthode est son portage sur un portable. En effet, nfs ne passe pas à travers un pare-feu bien fait alors que laisser passer du ssh est tout à fait admissible, donc un montage par shfs peu se faire n'importe où de la même façon.
http://lufs.sourceforge.net/lufs/
Montage d'un partage ftp :
lufsmount ftpfs://troumad:mot de passe@ftpperso.free.fr free
Mon essai est très peu probant : déconnections fréquentes et écriture impossible.
Montage d'un répertoire personnel distant par une connecxtion ssh :
lufsmount sshfs://geiibsiaud@134.214.12.34 bo4
Pour ce dernier montage, il est préférable de le faire avec clef publique/privé et ssh-agent/ssh-add afin de ne pas avoir à rentrer le mot de passe à chaque demande. Avec cette méthode, tous ce qui ne vous appartient pas est à demon, les droits sont conservés.
Pour le moment, je conseille donc shfs. Surtout à cause de la configuration dans /etc/fstab que je suis arrivé à faire correctement. Lufs à l'air non maintenu depuis fin 2003.
http://fuse.sourceforge.net/sshfs.html
chmod a+rw /dev/fuse
chmod u+s $(which sshfs) (pourquoi ?)
smart
Utilisation :
sshfs <user>@<serveur>:/<rep-distant> <point_montage>
Installation :
Sous Mandriva : « urpmi sshfs-fuse ».
Sous ubuntu, il suffit que l'utilisateur appartienne au groupe fuse pour qu'il puisse y accéder sans faire les changements de droits décrits si dessus.
Sous debian : « apt-get install sshfs », en plus : « chgrp fuse /dev/fuse »
Il faut parfois dire de lancer le module fuse au démarrage : dans /etc/modprobe.preload pour Mandriva ou /etc/modules pour Debian rajouter la ligne :
fuse
Le symptôme est le refus de monter le répertoire car /dev/fuse n’existe pas et ceci se répare avec :
sudo modprobe fuse
« umount s<point_montage> » simplement pour démonter, mais avec l'utilisateur qui a fait le montage.
Remarque : Voir les options allow_other et allow_root de sshfs pour être sur que l'utilisateur qui se connecte par samba puisse voir le répertoire.
Par défaut seul l'utilisateur qui monte le répertoire peut le voir (pour des raisons de sécurité). Mais tu peux changer ceci avec les options allow_other et allow_root comme mentionné précédemment.
# echo user_allow_other > /etc/fuse.conf
$ sshfs -o allow_other PC-distant:. ~/mnt/disk
Plus d'erreur et le répertoire est vu dans Windows via samba. Inutile de redémarrer le service fuse : le fichier /etc/fuse.conf est apparemment lu lorsque la commande sshfs est lancée.
Parfois l'utilisation de sshfs peut générer des figeages de certaines applications quand elles parcourent les répertoires. C'est que la connexion est coupée et le répertoire non démonté. La méthode la plus simple pour venir à bout de ce problème est de tuer les programmes ssh qui gèrent la connexion sshfs :
[troumad@localhost][~] $ ps uwx | grep ssh troumad 5312 0.0 0.0 12304 492 ? Ss Jan03 0:00 ssh-agent troumad 24727 0.0 0.0 28772 2600 pts/1 S 14:17 0:00 ssh -x -a -oClearAllForwardings=yes -oport=22 -2 geiibsiaud@134.214.12.234 -s sftp troumad 24735 0.0 0.0 176088 524 ? Ssl 14:17 0:00 sshfs geiibsiaud@134.214.12.234:/ /bureau -o port=22 troumad 24771 0.0 0.0 23708 852 pts/1 S+ 14:17 0:00 grep --color ssh kill -9 24727 24735
Et le problème est résolu.
http://www.citi.umich.edu/projects/nfsv4/ , http://www.citi.umich.edu/projects/nfsv4/linux/ , et http://www.nfsv4.org/
SFS est un système de fichiers réseau (basé sur nfs) sécurisé et global avec un système de contrôle complètement décentralisé. On doit créer un clef publique et une privée pour se connecter à un serveur sfs.
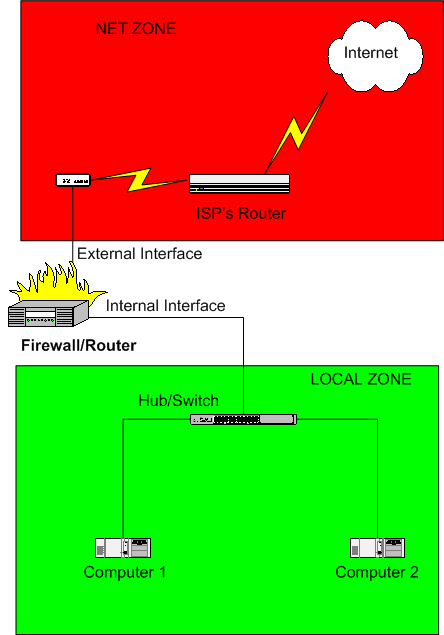
Dessin 2 : Firewall
ire-wallUn fire-wall est une protection de votre système contre les intrusions de l'extérieur. Il bloque certains ports et laisse les autres ouverts. Ils gèrent aussi les redirections de port et d'adresse, grâce à ça, il peut permettre le partage de connexions internet (votre PC, pourra alors servir de passerelle internet). Aujourd'hui (depuis la version 2.4 du noyau), sous Linux, le Fire-wall est géré par ip-table. Ip-table, lui peut-être géré par d'autres programmes comme shorewall.
Pour l'installer, passez par RpmDrake : installation de paquetages logiciels. Cherchez les programmes contenant Shorewall et installez-les. Vous pouvez aussi passer par la ligne de commande : « urpmi shorewall » . Shorewall utilise IPTABLES, il faut donc que vous l'ayez installé préalablement où son installation ce fera aussi automatiquement..
L'installation sous debian se fait avec « apt-get install shorewall » et contrairement à Mandriva, les fichiers de configurations ne sont pas présents dans le répertoire /etc/shorewall. Les fichiers de configuration peuvent être trouvés sur le système dans le répertoire /usr/share/doc/shorewall/default-config. Décompressez les (gunzip) et copiez simplement les dossiers dont vous avez besoin dans /etc/shorewall et modifiez les.
Guide complet : http://france.shorewall.net/shorewall_quickstart_guide.htm
Document inspiré de http://www.iglooduhack.com/linux_shorewall.php
Pour une utilisation domestique voir : http://docs.cafe-philo.net/procedures/shorewall.html
Shorewall voit le réseau où il tourne, comme un ensemble de zones.
Shorewall reconnaît aussi le système de firewall comme sa propre zone - par défaut, le firewall est connu comme fw.
Les règles à propos de quel trafic autoriser, et de quel trafic interdire sont exprimées en terme de zones.
Vous exprimez votre politique par défaut pour les connexions d'une zone vers une autre zone dans le fichier /etc/shorewall/policy.
Vous définissez les exceptions à ces politiques pas défaut dans le fichier /etc/shorewall/rules.
Pour chaque connexion demandant à entrer dans le firewall, la requête est en premier lieu comparée par rapport au fichier /etc/shorewall/rules. Si aucune règle dans ce fichier ne correspond à la demande de connexion alors la première politique dans le fichier /etc/shorewall/policy qui y correspond sera appliquée. Si cette politique est REJECT ou DROP la requête est dans un premier temps comparée par rapport aux règles contenues dans /etc/shorewall/common. Tous les fichiers de configuration pour Shorewall sont situés dans le répertoire /etc/shorewall.
Le fichier zones est utilisé pour définir les zones du réseau. Il y a une ligne par zone.
On va commencer par créer une zone qui sera le "réseau local" et une autre qui sera "Internet".
#ZONE DISPLAY COMMENTS
loc Local Reseau Local
net Net Internet
Colonne |
Description |
ZONE |
Le nom doit être composé de 5 caractères minuscules (chiffres et lettres) ou moins. Il doit commencer par une lettre. Le nom assigné au firewall et "multi" sont réservés pour Shorewall. Notez que la sortie produite par iptables est bien plus facile à lire si vous utilisez des noms de moins de 3 caractères. |
DISPLAY |
Le nom de la zone affichée pendant le démarrage de Shorewall |
COMMENTS |
Commentaires sur la zone. Shorewall ignore ces commentaires. |
Le fichier interfaces est utilisé pour indiquer au firewall quelle interface réseau de votre firewall est connectée à quelle zone. Il y a une entrée dans interfaces pour chacune de vos interfaces.
Si eth0 est la carte réseau qui interface le réseau local. (généralement c'est eth1 pour les connexions internet avec modem par éthernet, remplacer alors ppp0 (pour les modems usb) par eth1.)
#ZONE INTERFACE BROADCAST OPTIONS
loc eth0 detect
net ppp0 - noping
Colonne |
Description |
ZONE |
Une zone définie dans le fichier zones ou "-". Si vous spécifiez "-", vous devez utiliser le fichier hosts pour définir les zones accédées via cette interface. |
INTERFACE |
Le nom d'une interface (exemples: eth0, ppp0, ipsec+, etc.) |
BROADCAST |
L'adresse broadcast du sous-réseau attaché à l'interface. Il faut la laisser vide pour les interfaces P-T-P (ppp*, ippp*); si vous avez besoin de spécifier des options pour de telles interfaces, entrez "-" dans ce champ. Si vous spécifiez la valeur spéciale "detect", le firewall déterminera automatiquement l'adresse broadcast. Notez que pour utiliser ceci, vous devez avoir iproute installé et l'interface doit être montée avant le démarrage du firewall. |
OPTIONS |
Une liste d'options séparées par des virgules. Les options possibles sont : blacklist, dhcp, noping, routestopped, norfc1918, routefilter, multi, dropunclean. |
- « routestopped" : ce qui signifie que lorsque le firewall est arrêté, le traffic de et vers cet hôte sera accepté et le routage se fera entre cet hôte et les autres interfaces et hôtes qui ont l'attribut "routestopped". Cet attribut n'est plus valable dans les nouvelles versions. Il faut utiliser le fichier « routestopped ».
- "noping" : Signifie qu'il sera impossible de pinguer le firewall depuis Internet.
Le fichier masq est utilisé pour définir le masquage IP classique. A partir de la version 1.2.5 de Shorewall, il peut aussi servir à définir des NAT Source (SNAT). Il y a une entrée dans le fichier pour chaque sous-réseau que vous voulez masquer.
Les adresses réservées par la RFC 1918viii sont parfois désignées comme non-routables car les routeurs Internet (backbone) ne font pas circuler les paquets qui ont une adresse de destination appartenant à la RFC-1918. Lorsqu'un de vos systèmes en local, l'ordinateur 1 ( à l'adresse 192.168.1.2 du réseau local) demande une connexion à un serveur par Internet, le firewall doit appliquer un NAT (Network Address Translation). Le firewall réécrit l'adresse source dans le paquet, et la remplace par l'adresse de l'interface externe du firewall; en d'autres mots, le firewall fait croire que c'est lui même qui initie la connexion. Ceci est nécessaire afin que l'hôte de destination soit capable de renvoyer les paquets au firewall (souvenez vous que les paquets qui ont pour adresse de destination, une adresse réservée par la RFC 1918 ne pourront pas être routés à travers Internet, donc l'hôte Internet ne pourra adresser sa réponse à l'ordinateur 1). Lorsque le firewall reçoit le paquet de réponse, il remet l'adresse de destination à 192.168.1.2 et fait passer le paquet vers l'ordinateur 1.
Sur les systèmes Linux, ce procédé est souvent appelé de l'IP Masquerading mais vous verrez aussi le terme de Source Network Address Translation (SNAT) utilisé. Shorewall suit la convention utilisée avec Netfilter:
- Masquerade désigne le cas ou vous laissez votre firewall détecter automatiquement l'adresse de l'interface externe.
- SNAT désigne le cas où vous spécifiez explicitement l'adresse source des paquets sortant de votre réseau local.
Sous Shorewall, autant le Masquerading que le SNAT sont configurés avec des entrées dans le fichier /etc/shorewall/masq. Vous utiliserez normalement le Masquerading si votre adresse IP externe est dynamique, et SNAT si elle est statique.
Pour profiter de cet outil, vous devez avoir NAT activé. Les champs de ce fichier sont :
Si eth0 est la carte réseau qui interface le réseau local.
#INTERFACE SUBNET ADDRESS
ppp0 eth0
Colonne |
Description |
INTERFACE |
L'interface qui masquera le sous-réseau; c'est normalement votre interface internet. Ce nom peut optionnellement être qualifié en ajoutant ":" et un sous-réseau ou un hôte IP. Quand cette qualification est ajoutée, seulement les paquets adressés à cet hôte ou ce sous-réseau seront masqués. |
SUBNET |
Le sous-réseau que vous voulez voir masqué par l'interface. Il peut être exprimé somme une simple adresse IP, un sous-réseau ou un nom d'interface. Dans le dernier cas, l'interface doit être configurée et démarrée avant Shorewall, et Shorewall déterminera le sous-réseau en fonction des informations fournies par l'utilitaire 'ip'. |
ADDRESS |
L'adresse source à utiliser pour des paquets sortants. Cette colonne est optionnelle et si vide, l'adresse IP courante de l'interface de la première colonne est utilisée. |
Le fichier policy est utilisé pour décrire la politique du firewall concernant l'établissement des connexions. L'établissement des connexions est décrit en terme de clients qui initient des connexions et des serveurs qui reçoivent ces requêtes de connexion. Les politiques définissent quelles zones sont autorisées à établir des connexions avec quelles autres zones.
Le fichier policy est lu de haut en bas et Shorewall utilise la première politique applicable qu'il trouve. Faites attention à l'ordre de ces politiques.
Si eth0 est la carte réseau qui interface le réseau local.
#SOURCE DEST POLICY LOG LEVEL LIMIT:BURST
loc net ACCEPT
net fw ACCEPT
fw net ACCEPT info
net all DROP info
all all DROP info
??? - On accepte par défaut tout ce qui va du réseau local vers le firewall.
La première a qqc à voir avec le firewall? Je pensais que c'était entre le réseau local et le net!
- On accepte par défaut tout ce qui vient d'Internet vers le firewall
- On accepte par défaut tout ce qui va du firewall vers Internet en loguant
Ca veut dire quoi « en loguant »?
De cette manière vous aller avoir la politique suivante. Tout ce qui vient du réseau local et qui veut sortir vers Internet le pourra y compris des choses comme Chevaux de Troie (Trojan), Spyware.... En revanche tout ce qui essayera d'établir une connexion depuis Internet vers le réseau local ne le pourra pas.
C'est la première politique de sécurité, la moins contraignante mais pas la plus performante.
Une fois que vous aurez défini toutes les règles de droits de sortie au niveau du fichier rules vous pourrez alors passez cette règle à DROP ainsi tout ce qui essayera de sortir par un autre port que ceux que vous avez défini ne le pourra pas. Sachez que si vous utilisez par exemple un nouveau logiciel quelconque qui travaille sur un port donné et qui a besoins de sortir sur Internet, il faudra tout d'abord ouvrir le(s) port(s) du logiciel.
Ex: Si vous voulez recevoir vos mail et que vous n'avez pas ouvert le port 110 (port pop), alors le firewall supprimera tous les paquets qu'il recoit en loguant tout ceci dans /var/log/messages
- On supprime par défaut tout ce qui vient d'Internet vers partout (dans notre réseau local) en loguant
- On supprime par défaut tout ce qui vient de partout vers partout en loguant
Colonne |
Description |
SOURCE |
Le nom d'une zone cliente (une zone définie dans le fichier zone, le nom de la zone du firewall "fw", ou "all") |
DEST |
Le nom d'une zone de destination (une zone définie dans le fichier zone, le nom de la zone du firewall "fw", ou "all") |
POLICY |
La politique par défaut pour les requêtes de connexions de la zone CLIENT à la zone SERVEUR. - ACCEPT : la connexion est autorisée - DROP : la requête de connexion est ignorée (comme le PC n'existait pas) - REJECT : la requête de connexion est rejetée avec un paquet RST (TCP) ou ICMP - destination inaccessible - retourné au client - CONTINUE : la connexion n'est ni acceptée, ni ignorée, ni rejetée. CONTINUE peut être utilisé quand une ou les deux zones nommées dans la ligne sont des sous- zones ou croisent une autre zone. |
LOG LEVEL |
Optionnel. Si omis, aucun message n'est généré quand la politique est appliquée. Sinon, cette colonne devrait contenir un chiffre ou nom indiquant un niveau de log syslog. |
Le fichier rules définit les exceptions aux politiques définies dans le fichier policy. Il y a une ligne dans le fichier rules pour chaque règle. Les champs du fichier rules sont :
#ACTION SOURCE DEST PROTO DEST PORT SOURCE PORT(S) ORIGINAL DEST
# Internet Vers le Firewall
ACCEPT net:IP_INTERNET/27 fw tcp -
ACCEPT net:IP_INTERNET/27 fw udp -
# Atteindre le Firewall par le reseau local
# SSH (Telnet Securisé...) et Telnet non securisé
ACCEPT loc fw tcp 22,23
# Firewall Vers Internet
# DNS , HTTP, POP, SMTP, NNTP, SSL (=HTTPS)
ACCEPT fw net tcp 53,80,110,25,119,443
ACCEPT fw net udp 53
# accepter les ping de l'extérieur : important pour les serveurs DNS
# pour être reconnu par les routeurs
ACCEPT net fw icmp
# accepter les ping vers l'extérieur
ACCEPT fw net icmp
# accepter les ping du réseau local
ACCEPT masq fw icmp
# accepter les ping vers le réseau local
ACCEPT fw masq icmp
# permettre à notre PC d'accéder à un serveur X distant identifié par son IP ou sa MAC adresse.
ACCEPT net:ip_serveur fw udp 6000:6015 -
ACCEPT net:ip_serveur fw tcp 6000:6015 -
ACCEPT net:~MAC-ADDR-SEPARER-PAR-DES-SYMBOLES-MOINS fw udp 6000:6015 -
ACCEPT net:~MAC-ADDR-SEPARER-PAR-DES-SYMBOLES-MOINS fw tcp 6000:6015 -
Colonne |
Description |
ACTION |
ACCEPT, DROP ou REJECT. Ces valeurs ont la même signification ici que dans le fichier policy. DNAT : Fait suivre les appels sur un port du routeur vers un autre PC du réseau local À partir de la version 1.0.4, ceci peut éventuellemennt suivi par ":" et un niveau de log syslog (exemple: REJECT:info). Ceci fait que le paquet est loggué au niveau spécifié avant d'être accepté, ignoré ou rejeté. CONTINUE, DNAT, REDIRECT et LOG |
SOURCE |
Décrit le client. Ce client doit commencer par le nom d'une zone, mais peut être qualifié en ajoutant ":" et un qualificatif. Les qualificatifs sont soit : le nom d'une interface (exemple: loc:eth4), soit une adresse IP (exemple: net:155.186.235.151), soit une adresse MAC dans le format utilisé par Shorewall, soit enfin un sous-réseau (exemple: net:155.186.235.0/24). |
DEST |
Décrit le serveur. Ce champ peut prendre n' importe quelle forme décrite pour le CLIENT, plus deux formes supplémentaires : une adresse IP suivie par ":" et le numéro de port sur lequel écoute le serveur (exemple: loc:192.168.1.3:80), et deux ":" suivis par un numéro de port (exemple: fw::8080 - cette forme n'est autorisée que pour la zone du firewall "fw" et se réfère à un serveur fonctionnant sur le firewall lui-même et écoutant sur le port spécifié). |
PROTO |
Doit être le nom d'un protocole défini dans /etc/protocols , un nombre, "all" ou "related". Spécifie le protocole de la requête de connexion. "related" doit être spécifié seulement si vous avez défini ALLOWRELATED="no" dans le fichier shorewall.conf et que vous voulez écraser ce paramêtre pour les connexions des clients aux serveurs définis dans cette règle. Quand "related" est spécifié, le reste des colonnes devrait être laissé vide. |
DEST PORT |
Le port ou la plage de ports connectés. Ne peut être spécifié que si le protocol est tcp, udp ou icmp. Pour icmp, ce champ est interprété comme un type icmp. Si vous ne voulez pas spécifier de port(s) mais que vous avez besoin d'inclure des informations dans un des champs à droite, entrez "-" dans cette colonne. À partir de la version 1.1.12, vous pouvez donner une liste de ports et / ou une plage de ports séparées par des virgules. Une plage de ports a la forme : |
SOURCE PORT |
Peut être utilisé pour restreindre la règle à un port ou une plage de ports clients particuliers. Si vous ne voulez pas restreindre les ports clients mais voulez spécifier une ADRESSE dans la colonne suivante, entrez "-" dans cette colonne. A partir de la version 1.1.12, vous pouvez donner une liste de ports et / ou une plage de ports séparées par des virgules. |
ORIGINAL DEST |
Si le champ ACTION est DNAT ou REDIRECT et la colonne ORIGINAL DEST est laissée vide, n'importe quelle demande de raccordement arrivant au firewall de la SOURCE qui convient à la règle sera expédiée ou réorientée. Ceci fonctionne très bien pour des demandes de raccordement arrivant de l'Internet où le firewall a seulement une adresse IP externe simple. Quand le firewall a des adresses externes d'IP multiples ou quand la SOURCE est autre que l'Internet, il y aura habituellement un désir pour que la règle s'applique seulement à ces demandes de raccordement dirigées vers des adresses particulières d'IP (voir l'exemple 2 ci-dessous pour une autre utilisation). Ces adresses d'IP sont indiquées dans la colonne ORIGINAL DEST comme une liste virgule-séparée. |
On peut faire tourner un ou plusieurs serveurs sur nos ordinateurs locaux. Parce que ces ordinateurs ont une adresse RFC-1918, il n' est pas possible pour les clients sur Internet de se connecter directement à eux. Il est nécessaire à ces clients d'adresser leurs demandes de connexion au firewall qui ré écrit l'adresse de destination de votre serveur, et fait passer le paquet à celui-ci. Lorsque votre serveur répond, le firewall applique automatiquement un SNAT pour ré écrire l'adresse source dans la réponse.
Ce procédé est appelé Port Forwarding ou Destination Network Address Translation(DNAT). Vous configurez le port forwarding en utilisant les règles DNAT dans le fichier /etc/shorewall/rules.
La forme générale d'une simple règle de port forwarding dans /etc/shorewall/rules est:
Action |
Source |
Destination |
Protocole |
Port |
Source port |
Original address |
DNAT |
net |
loc:<server local ip address> [:<server port>] |
<protocol> |
<port> |
|
|
Voici deux exemples, ce sont deux lignes d'un fichier rules. Le premier exemple montre la redirection du port 80 du firewall vers le port 80 (même port) du PC d'adresse 192.168.1.2 et la seconde la redirection du port 5000 vers le port 80 du PC 192.168.1.3. Cette dernière méthode permet de détourner les FAI qui bloquent les requêtes entrantes de connexion sur le port 80. pour accéder au port 80 (serveur http) du PC 192.1.68.1.3, il faudra appeler le port 5000 du firewall.
DNAT net loc:192.168.1.2 tcp 80
DNAT net loc:192.168.1.3:80 tcp 5000
Pour obliger les requettes venant du sous réseau allant vers internet à passer par squid (voir XIII) Proxi)qui est sur le port 3128 :
REDIRECT masq 3128 tcp www
Les tunnels sont utilisés pour la configuration des VPN (Réseaux Privés Virtuels).
# TYPE ZONE GATEWAY GATEWAY ZONE
Colonne |
Description |
TYPE |
Le type de tunnel à configurer. Le type par défaut, "ipsec ". |
ZONE |
La zone sur laquelle le tunnel sera configuré. |
GATEWAY |
La passerelle du tunnel. |
GATEWAY ZONE |
La zone de la passerelle du tunnel. |
Pour la plupart des applications, spécifier les zones entièrement en termes d'interfaces réseaux est suffisant. Cependant, parfois on a besoin de définir une zone comme un ensemble d'hôtes. C'est le but du fichier hosts.
Attention ! 90% des utilisateurs de Shorewall n'ont pas besoin d'utiliser ce fichier, et 80% de ceux qui essaient d'ajouter des entrées dans ce fichier le font mal. A moins que vous ne soyez ABSOLUMENT SUR d'avoir besoin d'ajouter des entrées à ce fichier, ne le faites pas.
#ZONE HOST(S) OPTIONS
loc eth0:192.168.1.0/24 routestopped
Voici l'expliquation de cette syntaxe : 192.168.1.0/24
192.168.1.0 : désigne l'adresse de départ du réseau
/24 : désigne le masque de sous réseau et est équivalent à 255.255.255.0 (192.168.1.0/255.255.255.0). /n avec n entre 1 et 31 indique un nombre dont l'écriture en binaire à 32 chiffres avec les n premiers à 1 et le reste à 0. Ceci donne par exemple pour des cas bien précis :
Forme Courte |
Forme Complète |
Maximum de Machine |
Commentaire |
/8 |
/255.0.0.0 |
16777215 |
Réseau de classe A |
/16 |
/255.255.0.0 |
65535 |
Réseau de classe B |
/24 |
/255.255.255.0 |
255 |
Réseau de classe C |
Colonne |
Description |
ZONE |
La zone spécifiée doit être définie dans le fichier zone. |
HOST |
Le nom d'une interface suivi par « : » puis suivi soit par : - l'adresse IP : eth0:192.168.1.3 - le sous réseau : eth0:192.168.1.0/24 |
OPTIONS |
Soit "routestopped", soit vide. Quand le firewall est arrêté, le traffic de et vers cet hôte sera accepté et le routage se fera entre cet hôte et les autres interfaces et hôtes qui ont l'attribut "routestopped". Si vous ne définissez pas d'hôtes pour une zone, les hôtes de la zone prendront par défaut la valeur i0:0.0.0.0/0, i1:0.0.0.0/0, ... où i0, i1, ... sont les interfaces de cette zone. |
C'est très simple, il ne vous reste plus qu'à redémarrer shorewall en tapant : /etc/init.d/shorewall restart. Et là, attention, une erreur peut, par protection bloquer tous les ports!
Voir aussi : http://linux.developpez.com/guide/x7875.html#AEN8027
#
iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Sinon on a quelque chose du genre :
#
iptables -L
iptables v1.2.3: can't initialize iptables table
`filter': ...
Perhaps iptables or your kernel needs to be
upgraded.
Iptables est une instruction disponible à partir d'un terminal, on peut manuellement rentrer les commandes une par une pour mettre en place un firewall, mais il est plutôt recommandé d'en faire un fichier qu'on exécute au chaque démarrage ou changement de configuration (voir paragraphe suivant). En revanche, il est possible de tester une à une les commandes/modifications qu'on compte mettre dans ce fichier de configuration sur un terminal.
Un « man iptables » vous informera sur les possibilités de cette fonction. Le fichier de configuration suivant commenté devrait déjà vous en montrer un certain nombre.
Vous devez mettre un fichier avec les droits -rwxr--r-- contenant les lignes suivantes dans /etc/init.d. Ce fichier, je vais l'appeler « firewall » , en voici un exemple commenté, il est long, mais il faut le mettre complètement pour pouvoir le recopier :
#!/bin/sh
# ATTENTION la ligne du dessus
# n'est pas un commentaire
# variable (ipt) pour l'appel à l'exécutable de iptables
# => tester le même script avec plusieurs version de iptables
ipt=/sbin/iptables
# Pour simplifier une modification éventuelle des cartes réseaux
LOCAL="eth0" # connexion vers le réseau local pour une passerelle
NET="eth1" # connexion vers internet
RESEAU='192.168.0.0/16' # réseau local pour une passerelle
PPP="ppp0"
case "$1" in
start)
echo "Mise en place du mur de feu"
# /etc/network/if-pre-up.d/$ipt-start
# Script qui démarre les règles de filtrage "$ipt"
# MISE à ZERO des règles de filtrage
$ipt -F
$ipt -t nat -F
$ipt -t nat -X
# Je veux que les connexions entrantes soient bloquées par défaut
$ipt -P INPUT DROP
# Je veux accepter les connexions qui entrent par
# une interface et sortent par l'autre (ex. de eth1 vers ppp0)
# appelé aussi Forwarding
$ipt -P FORWARD ACCEPT
# Je veux que les connexions sortantes soient acceptées par défaut
$ipt -P OUTPUT ACCEPT
# Pas de filtrage sur l'interface de "loopback"
# Je déconseille de retirer cette règle car
# ça peut poser pas mal de problème et faire perdre
# la main sur la machine
$ipt -A OUTPUT -o lo -j ACCEPT
$ipt -A INPUT -i lo -j ACCEPT
# Je veux permettre tous les paquets sortants provenant de mon ordinateur
# redondant avec $ipt -P OUTPUT ACCEPT
# $ipt -A OUTPUT -m state --state NEW,ESTABLISHED,RELATED -j ACCEPT
# Si je veux avoir une politique plus contraignante, je peux filtrer
# les demandes locales vers l'extérieur. Voici un listing récupéré sur
# http://lea-linux.org/reseau/murdefeu.html
# en tcp :
# domain (obligatoire),
# ftp,
# ftp-data,
# sftp
# www,
# https,
# pop-3,
# imap2,
# imap3,
# smtp,
# ircd,
# cvspserver,
# rsync,
# 7070 (realaudio),
# 11371 (keyserver),
# ssh,
# 1441 (flux ogg de radio france)
# en udp :
# domain (obligatoire),
# 123 pour ntp
# iptables -A OUTPUT -o $NET -p udp --dport 123 -j ACCEPT
# 6970 et 7170 (realaudio)
# Décommentez la ligne suivante pour
# accepter le protocole ICMP (ex.ping)
$ipt -A INPUT -p icmp -j ACCEPT
#protection contre le ping de la mort
# iptables -A FORWARD -p icmp --icmp-type echo-request -m limit --limit 1/s -j ACCEPT
# Décommentez la ligne suivante pour
# accepter le protocole IGMP (multicast)
# $ipt -A INPUT -p igmp -j ACCEPT
# J'accepte les packets entrants relatifs à des connexions déjà établies
$ipt -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
# Décommentez la ligne suivante pour que le serveur FTP éventuel
# soit joignable de l'extérieur
# $ipt -A INPUT -p tcp --dport 21 -j ACCEPT
# La règle pour le port 20 est inutile quand on utilise le suivi de connexion.
# Le port 20 est utilisé uniquement comme port source par un serveur FTP en
# mode actif pour établir une connexion ftp-data _sortante_ vers le client.
# $ipt -A INPUT -p tcp --dport 20 -j ACCEPT
# Décommentez la ligne suivante pour que le serveur SSH éventuel
# soit joignable de l'extérieur
$ipt -A INPUT -p tcp --dport 22 -j ACCEPT
# Décommentez la ligne suivante pour que le serveur de mail éventuel
# soit joignable de l'extérieur
# $ipt -A INPUT -p tcp --dport 25 -j ACCEPT
# Décommentez les deux lignes suivantes pour que le serveur de DNS éventuel
# soit joignable de l'extérieur
$ipt -A INPUT -p tcp --dport 53 -j ACCEPT
$ipt -A INPUT -p udp --dport 53 -j ACCEPT
# Décommentez la ligne suivante pour que le serveur Web éventuel
# soit joignable de l'extérieur (tcp uniquement)
$ipt -A INPUT -p tcp --dport 80 -j ACCEPT
# Décommentez la ligne suivante pour que Imap soit
# accéssible sur le réseau interne
# 110 c'est le port pour POP3, et le port IMAP est plutôt le 143 : à revoir
# $ipt -A INPUT -i $LOCAL -p tcp --dport 110 -j ACCEPT
# Décommentez la ligne suivante pour que le serveur sftp éventuel
# soit joignable de l'extérieur
# $ipt -A INPUT -p tcp --dport 115 -j ACCEPT
# Décommentez la ligne suivante pour que le serveur ntpd éventuel
# soit joignable de l'extérieur
# $ipt -A INPUT -p udp --dport 123 -j ACCEPT
# Ou uniquement de votre réseau interne
$ipt -A INPUT -i $LOCAL -p udp --dport 123 -j ACCEPT
# Décommentez la ligne suivante pour que le serveur CUPS éventuel
# soit joignable de l'extérieur
# $ipt -A INPUT -p tcp --dport 631 -j ACCEPT
# CUPS uniquement pour le réseau interne
# $ipt -A INPUT -i $LOCAL -p tcp --dport 631 -j ACCEPT
# Décommentez les lignes suivantes pour que le serveur NFS éventuel
# configurer selon mon cours http://troumad.org/Linux/Linux.odt
# soit joignable du réseau interne
# /!\ dans les nouvelles versions multiport a été remplacé par multiport
#$ipt -A INPUT -i $LOCAL -p tcp -m multiport --dport 111,2049,4000:4003 -j ACCEPT
#$ipt -A INPUT -i $LOCAL -p udp -m multiport --dport 111,2049,4000:4003 -j ACCEPT
# Ceci remplace les lignes suivantes :
# $ipt -A INPUT -i $LOCAL -p tcp --dport 111 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p tcp --dport 2049 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p tcp --dport 4000 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p tcp --dport 4001 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p tcp --dport 4002 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p tcp --dport 4003 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p udp --dport 111 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p udp --dport 2049 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p udp --dport 4000 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p udp --dport 4001 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p udp --dport 4002 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p udp --dport 4003 -j ACCEPT
# Décommentez les lignes suivantes pour que le serveur Samba soit actif
# uniquement vers le réseau local
#$ipt -A INPUT -i $LOCAL -p tcp -m multiport --dport 137,139,445 -j ACCEPT
#$ipt -A INPUT -i $LOCAL -p udp -m multiport --dport 137,139,445 -j ACCEPT
# Décommentez les lignes suivantes pour que le serveur Généweb
# éventuel soit accessible
# $ipt -A INPUT -p tcp --dport 2317 -j ACCEPT
# Pour que l'administration du serveur Geneweb soit accessible de l'extérieur
# $ipt -A INPUT -p tcp --dport 2316 -j ACCEPT
# Pour laisser l'accès à MySQL
# $ipt -A INPUT -p tcp --dport 3306 -j ACCEPT
# $ipt -A INPUT -i $LOCAL -p tcp -m multiport --dport 3306 -j ACCEPT
# Pour laiser l'accès à postgresql en local avec un filtre sur les Ip appelantes
# i$pt -A INPUT -i $LOCAL -s Ip/masque -m state --state NEW -p tcp --dport 5432 -j ACCEPT
# Pour laisser passer le protocole nut : vision de l'état de l'onduleur
$ipt -A INPUT -i $LOCAL -p tcp --dport 3493 -j ACCEPT
# Pour faire fonctionner correctement bittorent
$ipt -A INPUT -p tcp -m multiport --dport 6969,6881:6889 -j ACCEPT
# Même chose avec une version plus ancienne de Iptables
#$ipt -A INPUT -p udp --dport 6881 -j ACCEPT
#$ipt -A INPUT -i $LOCAL -p tcp -m multiport --dport 6969,6881:6889 -j ACCEPT
# Pour VPN : http://pptpclient.sourceforge.net/howto-mandrake-101.phtml
# $ipt -A INPUT -i $LOCAL -p gre
# ACCEPT net fw gre
# $ipt -A INPUT -i $LOCAL -p tcp --dport 1723
# ACCEPT net fw tcp 1723
# Pour les log
$ipt -A INPUT -j ULOG
# voir http://olivieraj.free.fr/fr/linux/information/firewall/fw-03-09.html
# + complément dans la partie sur les log de mon cours
# La règle par défaut pour la chaine INPUT devient DROP
# pour des raisons de sécurité
$ipt -A INPUT -j DROP
# FIN des règles de filtrage
# DEBUT des règles pour le partage de connexion (i.e. le NAT)
# Décommentez la ligne suivante pour que le système fasse office de
# "serveur NAT" et ainsi cacher les machines forwardées par le firewall
# $ipt -s $RESEAU -t nat -A POSTROUTING -o $NET -j MASQUERADE
$ipt -t nat -A POSTROUTING -o $NET -j MASQUERADE
# option -s pour limiter à un sous réseau
echo 1 > /proc/sys/net/ipv4/ip_forward
# transférer l'appel ssh vers le PC 192.168.1.15
$ipt -t nat -A PREROUTING -j DNAT -i $NET -p TCP --dport 22 --to-destination 192.168.1.10
# redirige un appel sur le port 2121 vers le port 21 (ftp) du PC 192.168.1.10
#$ipt -A INPUT -p tcp --dport 2121 -j ACCEPT
#$ipt -t nat -A PREROUTING -j DNAT -i $NET -p TCP --dport 2121 --to-destination 192.168.1.10:21
# $ipt -A FORWARD -i $NET -m state --state ESTABLISHED,RELATED -j ACCEPT à vérifier
# avec uniquement cette ligne : passer le dtp en mode passif
# module à charger pour faciliter les choses (ip_nat_ftp et ip_conntrack_ftp) :
# modprobe ip_conntrack_ftp ports=21,2211
# modprobe ip_nat_ftp ports=21,2211
# À tester... Proxi quid transparent
# On redirige les requêtes sur le port 80
# $ipt -t nat -A PREROUTING -j DNAT -i $LOCAL -s ! 192.168.2.0/27 -p TCP --dport 80 --to-destination 192.168.0.1:3128 # remplacer 3128 par 8080 pour dansguardian #Bloquer le https s'il ne passe pas par le proxi #$ipt -A FORWARD -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 443 -j REJECT
# redirige l'appel du port 22222 vers le port 22 du PC 192.168.2.1
# (c'est à dire celui-là, mais sur sa carte orienté vers le réseau privé
$ipt -A INPUT -p tcp --dport 22222 -j ACCEPT
$ipt -t nat -A PREROUTING -j DNAT -i $NET -p TCP --dport 22222 --to-destination 192.168.2.1:22
# Si la connexion que vous partagez est une connexion ADSL, vous
# serez probablement confronté au fameux problème du MTU. En résumé,
# le problème vient du fait que le MTU de la liaison entre votre
# fournisseur d'accès et le serveur NAT est un petit peu inférieur au
# MTU de la liaison Ethernet qui relie le serveur NAT aux machines qui
# sont derrière le NAT. Pour résoudre ce problème, décommentez la ligne
# suivante et remplaçez "eth0" par le nom de l'interface connectée à
# Internet.
# $ipt -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS -o eth0 --clamp-mss-to-pmtu
# se protéger d'une attaque Denial of Service, dont le but est de saturer la passerelle par
# de nombreuses connexions non abouties, et ainsi de la faire tomber sous la charge
echo 1 > /pros/sys/net/ipv4/tcp_syncookies
# FIN des règles pour le partage de connexion (i.e. le NAT)
# DEBUT des règles de port forwarding
# Décommentez la ligne suivante pour que les requêtes TCP reçues sur
# le port 80 de l'interface eth0 soient forwardées à la machine dont
# l'IP est 192.168.2.15 sur son port 80 (la réponse à la requête sera
# forwardée au client)
# $ipt -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination 192.168.2.15:80
# Pour obliger certains PC (tous sauf ceux de 192.168.2.1 à 1982.168.2.15)
# de passer par le contrôle parental géré par dansguardian
# Si dansguardian est défini comme proxi tout sera bon, sinon certains ports seront bloqués
$ipt -t nat -A PREROUTING -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 80 -j DNAT --to-destination 192.168.2.1:8080
#$ipt -t nat -A PREROUTING -i eth3 -s ! 192.168.2.15 -p tcp --dport 443 -j DNAT --to-destination 192.168.2.1:8080
#$ipt -t nat -A PREROUTING -i eth3 -s ! 192.168.2.15 -p tcp --dport 21 -j DNAT --to-destination 192.168.2.1:8080
#$ipt -t nat -A PREROUTING -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 443 -j DNAT --to-destination 192.168.2.1:8080
$ipt -A FORWARD -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 443 -j REJECT
$ipt -A FORWARD -i eth3 -s 192.168.2.250 -j REJECT
# bloquer msn
$ipt -A FORWARD -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 1863 -j REJECT
# FIN des règles de port forwarding
# FIN du script de démarrage
;;
ouvert)
echo "Arret du mur de feu"
# deux possibilités : firewall ouvert ou fermé
# Début régles ouvert"
# On vide (flush) toutes les regle existantes
#$ipt -F
#$ipt -X
# On remet la police par defaut
# $ipt -P INPUT ACCEPT
# $ipt -P FORWARD ACCEPT
# $ipt -P OUTPUT ACCEPT
## fin des options firewall ouvert
;;
stop)
echo "Isolement complet"
# début régles fermées
$ipt -F
$ipt -t nat -F
$ipt -t mangle -F
$ipt -X
$ipt -t nat -X
$ipt -t mangle -X
$ipt -P INPUT DROP
$ipt -P OUTPUT DROP
$ipt -P FORWARD DROP
$ipt -t nat -P PREROUTING ACCEPT
$ipt -t nat -P POSTROUTING ACCEPT
$ipt -t nat -P OUTPUT ACCEPT
$ipt -A OUTPUT -o lo -j ACCEPT
$ipt -A INPUT -i lo -j ACCEPT
$ipt -A INPUT -i $LOCAL -d $RESEAU -p tcp --dport 22 -j ACCEPT
$ipt -I OUTPUT -p tcp --sport 22 -j ACCEPT
# Un bon firewall arrêté est un firewall *fermé*,
# je suis laxiste, je laisse le loopback ouvert.
# En plus je permet toujours du ssh du lan : le serveur est sans clavier ni écran !
# fin règles fermées
;;
restart)
# Le stop est inutile car le start vide aussi les chaînes et redéfinit les politiques par défaut
# $0 stop
# /bin/sleep 1
# /usr/bin/sleep 1
;;
*)
echo "Usage: $0 {start|stop|ouvert|restart}"
exit 1
;;
esac
Un autre exemple : http://www.canonne.net/linux/iptables/firewall.sh.php?print=1
Pour automatiser la mise en marche et l'arrêt de ce programme il faut les flécher dans les /etc/rcX.d. Avec un peu de chance dans /etc/inittab, vous aurez un commentaire pour savoir à quoi correspond quel /etc/rcX.d, sinon, il faudra décortiquer ce qu'ls contiennent.
Sur Mandriva :
# Default runlevel. The runlevels used by Mandrivalinux are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:5:initdefault:
Sur Debian :
# The default runlevel.
id:2:initdefault:
# [...]
# /etc/init.d executes the S and K scripts upon change
# of runlevel.
#
# Runlevel 0 is halt.
# Runlevel 1 is single-user.
# Runlevels 2-5 are multi-user.
# Runlevel 6 is reboot.
Donc, je les mets en démarrage sur rc1.d, rc2.d, rc3.d, rc4.d et rc5.d, à l'arrêt sur rc0.d et rc6.d en lieu et place de shorewall ou d'un autre firewall qui serait déjà installé. Pour les 5 du démarrage :
cd /etc/rc5.d
ln -s ../init.d/firewall S10firewall
Pour les 2 autres :
cd /etc/rc0.d
ln -s ../init.d/firewall K90firewall
Pour couper l'accès internet au PC d'Ip 192.168.2.113 sur votre réseau :
iptables -A FORWARD -i eth3 -s 192.168.2.113 -j DROP
Il existe des sites à partir desquels on peut tester notre configuration :
En voici :
un : https://grc.com/x/ne.dll?bh0bkyd2
Puis une liste : http://www.linux-sec.net/Audit/nmap.test.gwif.html
http://check.sdv.fr/
Un autre test pour faire peur : http://leader.ru/secure/who.html
Un serveur DNS est un serveur qui sert à convertir des adresses noms (FQDNix) en adresses IP. Par exemple, quand vous tapez dans votre navigateur préféré l'adresse : http://lea-linux.org, celui-ci va tout d’abord faire une requête à un serveur DNS (généralement le serveur DNS que vous avez configuré pour votre connexion à l’Internet, donc les serveurs DNS de votre fournisseur d’accès) en lui demandant :
C’est quoi l’adresse IP de lea-linux.org ? Le serveur DNS lui donne l’adresse IP et le navigateur va alors se connecter à cette adresse IP (80.245.32.131) et afficher le site. Ceci est valable pour toute autre application qui manipule des noms DNS (ftp, telnet, mail, ....).
Sous LINUX, le serveur DNS le plus répandu s’appelle BIND ou bind9 « urpmi bind » ou « apt-get install bind9 ». Ses fichiers de configuration sont /etc/named.conf , /etc/named/named.conf ou /etc/bind/named.conf (contient les paramètres généraux dont les noms des serveurs sur lesquels il va chercher ses informations), /var/named/named.ca (indique les serveurs dns racines) et /var/named/named.local (résolution locale des adresses loopback). Parfois, vous allez en rajouter d’autres en fonction de vos besoins. Il est bien de les placer dans /var/named/.
Il faut savoir que si on achète son nom de domaine, nos coordonnées sont publiques donc accessible à tous : http://www.whois.sc/msn.net .
http://lea-linux.org/reseau/dns1.php3
http://www.freenix.org/unix/linux/HOWTO/DNS-HOWTO.html
Pour faire accepter votre serveur DNS il faut parfois (voir au cas par cas) pouvoir le pinguer … Pour ma configuration, j’ai dû rajouter dans /etc/shorewall/rules la ligne : ACCEPT net fw icmp . En revanche, il faut toujours laisser ouvert le port 53.
Voici un fichier named.conf : fichier d’amorçage du serveur primaire pour mon_lycee.fr
# Dans la partie options, il faut considérer les point suivants :
#
#- Les requêtes les plus nombreuses sont les requêtes locales :
# bien régler pour qu’on puisse accéder au serveur du réseau local uniquement : 192.168.XXX.XXX
# et permettre au serveur de pouvoir s’appeler pui-même
acl internals { 127.0.0.0/8; 192.168.0.0/16; };
#- Il faut éviter de transférer à l'extérieur les informations du réseau interne.
#
# De fait, il ne faut donc pas forwarder en premier. Le DNS local doit d'abord résoudre et
# s'il n'y arrive pas il forwarde. Sinon, on donne la structure de notre réseau à l'extérieur
# étant donné qu'on fait d'abord un forward. En plus les temps de réponse du DNS local sont
# toujours plus rapide que ceux des DNS externes.
#
# De plus, je conseille de conserver le contrôle sur le fichier de process (named.pid),
# les adresses sur lesquelles on écoute, le niveau d'autorité et la capacité de transfert.
#
# Le fichier de process c'est /var/run/named/named.pid (c’est la valeur par défaut, mais mieux
# vaut l'avoir explicitement), les adresses d’écoute c’est listen-on et listen-on-v6
# (none si on n'a pas d'IPv6), et par défaut mettre le serveur en mode de transfert non autorisé
# par allow-transfer { none; }; afin d'avoir le contrôle total sur quelle zone peut être
# transferée ou non
#
options {
pid-file "/var/run/named/named.pid
directory "/var/named" ; le répertoire où se trouvent les fichiers
# forward first ; redirige les requêtes puis tentera de répondre si pas de réponse
forwarders { ; serveurs vers lesquelles les requêtes sont envoyées
195.98.246.50 ; serveur DNS supérieur
};
#
listen-on {
<liste d'adresses>; # genre 192.168.1.41, il peut y en
avoir plusieurs si le serveur
# dispose de plusieurs interfaces. De plus si c'est le cas on peut accepter les requêtes
# de l'interne mais pas celle de l'externe. Car par défaut le serveur écoute sur toutes
# les interfaces.
# };
listen-on-v6 { none; };
allow-transfer { none; };
# par défaut, les autorisations de transfert étant faites zone par zone
auth-nxdomain yes; # sujet à discussion mais moi je le mets pour être tranquille
};
# la zone hint n'est pas le domaine interne, c'est le domaine racine (root), il est mis en cache
# localement afin d'éviter une trop grande surcharge des serveurs en question. Le fichier
# named.ca est à télécharger sur le site qui va bien (regarder dans named.ca en général le nom
# du site y est inscrit). C'est un fichier qui ne change pas très souvent mais qu'il est bon de
# mettre à jour à l'occasion (moi je le fais tous les 6 mois).
#
zone "." { ; domaine interne
type hint; cette entrée n'est qu'un endroit où débuter les recherches
file "named.ca"; nom du fichier avec les infos : ne pas le toucher
};
zone "0.0.127.in-addr.arpa" { ; zone pour le réseau loopback.
type master;
file "named.local";
};
zone "1.168.192.in-addr.arpa" in { ; le sous réseau local en 192.168.1.XXX
notify no; ne pas prévenir les autres serveurs DNS de modifications à ce niveau
type master; ce serveur est maître de ce sous réseau
file "db.192.168.1"; nom du fichier avec les infos
allow-transfer {
# liste des ips des serveurs secondaires; # uniquement si on transfert la zone inverse
#
sur un serveur secondaire local
};
};
# La zone directe:
# première remarque, on évite toujours de faire une zone privée identique à la zone publique
# L'externe dispose ainsi des informations sur la structure interne du réseau et c'est mauvais
# pour la sécurité.
# allow-transfert
#
1) si on ne met rien, aucun ne pourra être secondaire.
# 2) si
on en met un, il faudra aussi l'ajouter en champ NS et A dans la
définition de la zone du
# domaine concerné. Sinon, il aura beau avoir les droit de récupérer la zone, personne ne le
# connaîtra et ne l'utilisera.
zone "lycee.org" {
type master;
file "named.lycee";
allow-transfer { 213.245.103.18; };
}
# Donc si lycee.org est un domaine publique accessible de l'internet, on devrait utiliser un
# autre domaine (genre net.lycee.org) pour ton réseau interne et gérer ainsi les deux zones.
#
#La zone privée transférée uniquement sur les secondaires interne, la zone publique transférée
# sur les serveurs externes.
#
# De plus, pour ajouter de la sécurité, du fait des deux vues possible
# (une interne et une externe) on utilise la fonction view qui permet d'avoir:
views
"internal" {
match-clients {
192.168.1.0/24; uniquement les hôtes internes;
};
déclaration de la zone
hint;
déclaration de la zone
loopback
déclaration de la zone
reverse interne;
déclaration de
la zone privée net.lycee.org;
};
views "external"
{
match-clients {
any; # tout le monde
};
recursion no; # sur celui-là pas besoin d'autoriser les recursions
declaration de la zone publique lycee.org;
};
#
Petit ajout, comme le serveur est accessible de l'extérieur, il est
bon de cacher les
# information de version et d'hôte du serveur en ajoutant dans options:
version
none;
hostname none;
server-id none;
# plus dans la vue external ajouter une zone de type chaos :
zone
"bind" chaos {
type master;
file
"bind";
allow-query { localhost; };
};
avec le fichier bind suivant:
$TTL
1D
$ORIGIN bind.
@ 1D
CHAOS SOA localhost.
root.localhost. (
1
3H
1H
1W
1D )
CHAOS NS localhost.
et
le tour est joué, ça ajoute de la sécurité pour éviter que les
personnes externes ne puissent avoir accès aux informations de base
du serveur.
Sinon, d'une façon générale, dans tes
fichiers de zone, spécifie en début de fichier l'origine de la zone
traitée par la fonction:
$ORIGIN
lycee.org.
ou
$ORIGIN net.lycee.org.
ATTENTION :
ne pas oublier le point a la fin (ce point signifie la zone root
définie dans named.ca).
Par ailleurs, sur une zone
accessible de l'extérieur on évite les enregistrements HINFO, ils
donnent des infos utiles pour un hacker mais inutile pour un user
internet. Je sais ça fait un peu parano, mais les DNS sont les
premières cibles d’une tentative d’intrusion ou d’un DoS
Enfin, le fichier hosts n'est utilisé en premier qu’en
fonction de ce qui est mis à la ligne hosts du fichier
/etc/nsswitch.conf:
hosts:
files dns
ça
veut dire /etc/hosts en premier, dns en dernier. Le client dns
interroge les serveurs dns definis dans /etc/resolv.conf que s'il n'a
pas eu de réponse avec le fichier /etc/hosts
avec
hosts: dns files
c’est
l’inverse.
@ IN SOA mon_serveur.mon_lycee.fr. postmaster.mon_serveur.monlycee.fr.(
2003091700 ; numéro de série (date 2003-sept-17 et version 00)
28800 ; rafraîchissement toutes les 8 heures
14400 ; nouvel essai toutes les 4 heures
604800 ; expiration dans 7 jours
86400 ) ; temps de vie minimal 24 heures
NS mon_serveur.mon_lycee.fr.
1 PTR localhost.
@ IN SOA mon_serveur.mon_lycee.fr. postmaster.mon_serveur.monlycee.fr.(
2000101500 ; numéro de série
28800 ; rafraîchissement toutes les 8 heures
14400 ; nouvel essai toutes les 4 heures
604800 ; expiration dans 7 jours
86400 ) ; temps de vie minimal 24 heures
; serveur de nom
IN NS mon_serveur.mon_lycee.fr.
; adresses IP inverses
1 IN PTR mon_serveur.mon_lycee.fr. ; adresse 192.168.1.1
2 IN PTR mon_serveur_web.mon_lycee.fr.; adresse 192.168.1.2
3 IN PTR mon_serveur_smtp.mon_lycee.fr.; adresse 192.168.1.3
ce fichier me sert à rediriger le domaine lycee.org que je viens d'acheter.
Il faut distinguer deux choses : Les hôtes du domaine et le domaine lui-même. Le domaine c'est mon_domaine.fr (format domain.tld). L'hôte, en l’occurrence le serveur web c'est www, le DNS c'est ns1.
Les noms pleinement qualifiés de ces hôtes (nom FQDN Fully Qualified Domain Name) sont : www.mon_domaine.fr ns1.mon_domaine.fr .
Je redirige tout sur un seul ordinateur car je ne dispose que d'une seule adresse internet publique. Pour ceci, mon serveur DNS ne doit pas être protégé d'internet car il doit fournir les adresses internets de mes redirections à l'extérieur. L'intérêt est de mettre plusieurs adresses de site internet sur le PC. À chaque modification de ce fichier, on se doit de modifier le numéro de série pour que la modification soit prise en compte par les autres serveurs. Ce numéro se constitue régulièrement de la date (20031018) et du numéro de la modification de ce jour (ici version 2)
$TTL 86400
# SOA -> declaration de la zone
@ IN SOA ns1.lycee.org. root.lycee.org. (
2003101802 ; Serial
86400 ; Refresh
14400 ; Retry
3600000 ; Expire
86400 ) ; Minimum
#
NS -> déclaration du ou des serveurs de domaine
lycee.org.
IN NS ns1
; serveur primaire puis secondaire
lycee.org IN NS ns.serveurdns.org. # serveur d'Ip 213.245.103.18;
;notez le '.' à la fin de ns.serveurdns.org.
; ce '.' signifie que ns.serveurdns.org est le nom complet.
; l'absence de '.' à la fin de troumad signifie
;qu'on doit ajouter lycee.org à la fin du nom
# MX -> déclaration du serveur de mail
IN MX 10 troumad
IN HINFO PVI_4,5GHz LINUX
1 IN PTR localhost.
;les adresses
# A -> déclaration d'hôtes (les serveurs de domaine sont souvent les premiers)
ns1 IN A 214.225.113.1
troumad IN A 214.225.113.188
; les redirections
geii IN CNAME troumad
bernard IN CNAME troumad
marie-claire IN CNAME troumad
aline IN CNAME troumad
elian IN CNAME troumad
christian IN CNAME troumad
sylvie IN CNAME troumad
thomas IN CNAME troumad
lucas IN CNAME troumad
andre IN CNAME troumad
jeanine IN CNAME troumad
*
300 IN CNAME troumad
;renvoie
tous les noms inconnus sur troumad!
;Les noms ne peuvent pas contenir de _
Attention, ne pas définir aussi ces noms dans /etc/hosts sur les adresses du réseau local, sinon sur le PC, on aura d'abord la redirection local.
Par Pascal Leneant
On commence à l'installer : « urpmi mydns-admin ». (Pas présent sur Mageia 4 => pas testé).
Il faut éditer le php qui se trouve dans le répertoire des pages d'apache. Tu trouveras, en début de fichier des variables de connexion à la base de données MySQL. Dans ces variables (de mémoire), il faut indiquer la machine où se trouve la base de donnée MySQL dédiée à MyDNS, puis le nom de la base de données de MyDNS (par défaut mydns) et enfin l'utilisateur ayant les droits d'administration de la base ainsi que son mot de passe.
À partir de là, tu dois pouvoir accéder à la base de données de mydns.
Mais il faut que cette base existe. La base de données doit être créée manuellement. Lors de l'installation de mydns, dans le readme, tu as la procédure d'initialisation de la base de données. Il te faut la suivre et donner les droits d'admin à l'utilisateur de mydns et de mydns-admin. Pour mydns tout est expliqué. De mémoire ça doit se trouver dans le répertoire des documentations mandriva sur ta machine et dans le sous répertoire "mydns".
Vérifiez que vous n'avez pas fait d'erreur de syntaxe dans le fichier named.conf :
% named-checkconf
Si la commande n'affiche rien, c'est que le fichier est valide. Vous pouvez alors dire à Bind de relire son fichier de configuration :
# /etc/init.d/named reload
Votre serveur DNS fera alors régulièrement des transferts de zone depuis le serveur primaire (et notamment à chaque fois que le serveur primaire lui notifiera d'un changement dans la zone).
L'utilitaire dig permet de faire des requêtes DNS évoluées et fournit un maximum d'informations sur la requête. Il est très utile pour vérifier la bonne configuration d'un serveur DNS.
Exemples d'utilisation de dig :
Requête sur le champ "A" du nom www.lycee.org auprès du serveur DNS 198.41.0.4 (trouvé dans /etc/named/named.ca) :
% dig @198.41.0.4 www.lycee.org A
Requête sur la champ "MX" du nom lycee.org auprès du serveur DNS 198.41.0.4 :
% dig @198.41.0.4 lycee.org MX
Requête sur tous les champs du nom lycee.org auprès du serveur DNS 198.41.0.4 :
% dig @198.41.0.4 lycee.org ANY
Requête AXFR sur le domaine mondomaine.org auprès du serveur DNS 198.41.0.4 :
% dig @198.41.0.4 lycee.org AXFR
Requête inverse (i.e. reverse DNS) sur l'IP 12.42.111.422 auprès du serveur DNS 198.41.0.4 :
dig @198.41.0.4 -x 12.42.111.422
La sortie de la commande dig est très détaillée ; la réponse à la requête (la partie qui vous intéressera le plus !) se trouve en dessous de la ligne suivante :
;; ANSWER SECTION:
La liste des serveurs DNS auxquels s'adresse votre PC est dans le fichier /etc/resolv.conf :
$ cat /etc/resolv.conf
search linuxmafia.com mon_domaine.fr
nameserver 192.168.1.1
nameserver 212.186.224.9
nameserver 212.83.64.138
# ppp temp entry
[root@pc_bernard][/etc]$ man resolv.conf
Mais pour le réseau local, il y a le fichier /etc/hosts qui défini des raccourcis. Afin de donner un ordre de préséance entre ces fichiers, il y a /etc/hosts.conf :
Il faut regarder dans /etc/hosts.conf si on a bien l'ordre suivant afin de favoriser notre propre serveur :
order hosts,bind
multi on
La première ligne signifie « si quelqu'un cherche à accéder à une machine sans donner son nom complet, essayer d'ajouter au nom fourni le suffixe 'linuxmafia.com' par défaut, ou encore 'mon_domaine.fr' avant d'abandonner ». Les trois dernières lignes donnent les adresses IP des trois serveurs DNS auxquels le résolveur (client) transmettra les demandes. Une quatrième adresse ne sera pas prise en compte.
Un proxy permet d'accélérer vos connexions à l'internet en plaçant en cache les sites les plus visités. Ainsi dans des établissements scolaires cela permet d'améliorer les connexions.
Le serveur proxy le plus connu sous Linux, c'est squid. On l'installe avec « urpmi squid ». Son seul fichier de configuration de squid est : /etc/squid/squid.conf.
chkconfig squid : démarrage automatique de squid
squid -z : Création du cache sur le disque dur
squid -k reconfigure : Relecture de fichier squid.conf. Cela permet de prendre en compte des modifications dans le fichier de configuration sans avoir à relancer squid. Ou « /etc/init.d/squid restart » avec perte du cache. Si Squid ne démarre pas (ou si lorsque vous voulez l'arrêter, il donne une erreur) regardez le fichier /var/log/squid/cache.log il pourra vous informer. Le fichier /var/log/squid/access.log pourra lui vous montrer que les dernières pages sont passées par le cache.
Maintenant, pour obliger le passage par le proxi, regarder le chapitre sur le fire-wall.
Voici mon /etc/squid/squid.conf (juste les lignes décommentées) :
hierarchy_stoplist cgi-bin ?
acl QUERY urlpath_regex cgi-bin \?
no_cache deny QUERY
cache_mem 64 MB # j'ai beaucoup de mémoire sur mon serveur.
maximum_object_size 8192 KB
cache_dir ufs /opt/squid 1024 16 256 # je choisi la place d'un gros DD presque inutilisé
dns_nameservers 127.0.0.1 # pour faire appel au DNS local
auth_param basic children 5
auth_param basic realm Squid proxy-caching web server
auth_param basic credentialsttl 2 hours
refresh_pattern ^ftp: 1 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern . 0 20% 4320
acl chez_moi src 192.168.1.0/255.255.255.0 # Je définis mon réseau local
acl all src 0.0.0.0/0.0.0.0
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
acl to_localhost dst 127.0.0.0/8
acl SSL_ports port 443 563
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 563 # https, snews
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl Safe_ports port 22 # ssh
acl Safe_ports port 115 # sftp
acl CONNECT method CONNECT
http_access allow chez_moi # Je me donne l'accès au réseau
http_access allow manager localhost # suite des permissions
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost
http_reply_access allow all
icp_access allow all # aucun contrôle sur les icp
cache_peer proxy04.chello.fr:8080 sibling 8080 3130 no-query default # PROXI cache de mon FAI
visible_hostname troumad # Nom de mon serveur
httpd_accel_host virtual # Les 4 lignes qui suivent servent à configurer un proxi
httpd_accel_port 80 # transparent grâce à une redirection sur le firewall du routeur
httpd_accel_with_proxy on # HTTP-accelerateur depuis la version 2
httpd_accel_uses_host_header on # HTTP-accelerateur depuis la version 2
httpd_accel_single_host off
error_directory /usr/lib/squid/errors/French
coredump_dir /var/spool/squid
Dans /etc/squid, vous pouvez aussi modifier le lien vers ../../usr/lib/squid/errors/English/ pour mettre par exemple ../../usr/lib/squid/errors/French/.
C'est une erreur qui peut arriver : modifier les serveurs DNS de /etc/resolv.conf .
http://www.linux-france.org/article/web/egraffin/squid.php http://christian.caleca.free.fr/squid/
http://www.ac-creteil.fr/reseaux/systemes/linux/outils-tcp-ip/squid.html
http://stargate.ac-nancy-metz.fr/linux/cache/configuration/configuration.htm
http://cri.univ-tlse1.fr/blacklists/
http://mdvmondelinux.tuxfamily.org/spip.php?page=article_pdf&id_article=57
http://www.coagul.org/spip.php?article570
http://arnofear.free.fr/linux/template.php?tuto=27&page=1#conf_dansguardian
Ce logiciel peut servir de contrôle parental ou de limitation d'accès dans une entreprise. On peut obliger un appel vers un site web (port 80) sur la passerelle de passer par dansguardian de façon transparente en laissant un passage pour les administrateurs (postes de 192.168.2.1 à 192.168.2.15) :
$ipt -t nat -A PREROUTING -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 80 -j DNAT --to-destination 192.168.2.1:8080
On peut interdire un appel https sans passer par dansguardian avec :
$ipt -t nat -A PREROUTING -i eth3 ! -s 192.168.2.0/27 -p tcp --dport 443 -j DROP
On peut couper de plus l'accès internet (ftp, ...) sans passer par le proxi, mais après, ça peut compliquer pas mal de manipulations. Comme une mise à jour : il faudra alors signaler dans la commande « urpmi » le port à utiliser avec l'option « –proxy ».
Il faut lancer dansguardian après le proxi. Sinon, dansguardian ne peut pas se lancer.
Avec les anciennes versions de Linux, sans systemd, ceci peut se faire comme ça par exemple :
[root@troumad][/etc/rc5.d]# ln -s ../init.d/squid S52quid
[root@troumad][/etc/rc5.d]# ln -s ../init.d/dansguardian S64dansguardian
Il faut que le numéro attribué à dansguardian soit inférieur à celui de squid
Avec systemd, il faut regarder dans le répertoire /lib/systemd/system afin de trouver dansguardian :
Mon expérience m’a aussi montré qu’on ne peut pas filtrer tout comme c’est défini par défaut. En effet, j’ai dû retirer des listes de mots interdits pour accéder à des sites pour faire des nichoirs d’oiseaux ! J’ai retiré des listes de mots dans des langues étrangères pour ne conserver que le français et l’anglais (pour le moment).
http://www.ac-creteil.fr/reseaux/systemes/linux/outils-tcp-ip/Linux-dhcp.html
Le DHCP (Dynamique Host Configuration Control) est un service, qui sert à configurer les paramètres réseaux des machines clientes à distance. Ceci permet à l’ordinateur client (celui qui reçoit l’information) d’avoir les bons paramètres pour accéder au réseau. Les informations fournies sont :
Adresse IP
Masque Réseau ( NetMask )
Passerelle ( Gateway )
Adresses des serveurs de Noms ( DNS )
Il peut reconnaître les ordinateurs grâce à leur mac adresse (donnée uniquex inscrite en dur sur la carte réseau, voir plus loin un script pour les trouver) et à partir de là, en donnant toujours la même adresse au même PC, permettre différents accès au réseau en fonction du PC.
La configuration du serveur DHCP consiste à étudier 2 fichiers :
- /etc/dhcpd.conf : ce fichier sert à la configuration même du serveur (plage d’adresses, paramètres distribués…)
- /var/lib/dhcp/dhcpd.leases : ce fichier va servir à l’inscription automatique des clients. Il peut ne pas se trouver dans ce répertoire, cela dépend de la version installée, on peut aussi le trouver dans /var/dhcpd ou dans /etc. Chaque client DHCP, génère l’écriture d’un enregistrement dans ce fichier. Cela permet le suivi de l'activité du serveur (statistiques…) et aussi de repérer les mac adresses des objets qui se sont connectés afin de peaufiner la configuration de /etc/dhcpd.conf.
Sous Mageia on l’installe avec : « urpmi dhcp-server » sur mageia ou « apt-get install isc-dhcp-server » sur debian.
Sous debian : « systemctl restart isc-dhcp-server » pour relancer le serveur dhcp.
Voici un fichier /etc/dhcpd.conf :
ddns-update-style none;
# ici il s'agit du réseau 192.168.1.0
subnet 192.168.1.0 netmask 255.255.255.0 {
#La plage d'adresses disponibles pour les clients
range 192.168.1.50 192.168.1.150;
# Les clients auront cette adresse comme passerelle par défaut
option routers 192.168.1.1;
# Ici c'est le serveur de nom, le serveur privé,
# il faut aussi mettre le DNS donné par votre provider.
option domain-name-servers 192.168.1.1;
option domain-name-servers 212.186.224.9;
option domain-name-servers 212.186.224.10;
# On donne le nom du domaine
option domain-name "lycee.org";
# Et l'adresse utilisée pour la diffusion
option broadcast-address 192.168.1.255;
#Le bail a une durée de 86400 s par défaut, soit 24 h
# On peut configurer les clients pour qu'ils puissent demander une durée de bail spécifique
default-lease-time 86400;
#On le laisse avec un maximum de 7 jours
max-lease-time 604800;
}
host s_travail {
hardware ethernet 00:30:f1:82:35:0f;
fixed-address 192.168.2.10; # donner une adresse fixe au PC identifié par hardware ethernet
# deny booting; # ne pas donner d'adresse au PC identifié par hardware ethernet
}
Le /etc/default/isc-dhcp-server sur debian doit indiquer l’interface sur laquelle agit le serveur :
# Defaults for isc-dhcp-server (sourced by /etc/init.d/isc-dhcp-server)
# Path to dhcpd's config file (default: /etc/dhcp/dhcpd.conf).
#DHCPDv4_CONF=/etc/dhcp/dhcpd.conf
#DHCPDv6_CONF=/etc/dhcp/dhcpd6.conf
# Path to dhcpd's PID file (default: /var/run/dhcpd.pid).
#DHCPDv4_PID=/var/run/dhcpd.pid
#DHCPDv6_PID=/var/run/dhcpd6.pid
# Additional options to start dhcpd with.
# Don't use options -cf or -pf here; use DHCPD_CONF/ DHCPD_PID instead
#OPTIONS=""
# On what interfaces should the DHCP server (dhcpd) serve DHCP requests?
# Separate multiple interfaces with spaces, e.g. "eth0 eth1".
INTERFACESv4="eth1"
#INTERFACESv6=""
« deny booting » empêche de donner une adresse, mais un PC dans ce cas s’il est configuré en DHCP prendra une adresse quelconque. Je propose une autre méthode à la ligne suivante.
On peut définir la plage d’adresses disponibles pour les clients sur une plage non redirigée vers internet par le fire-wall. Ceci permet aux utilisateurs non connus de récupérer une adresse Ip sans accès à internet. On peut même bloquer tous les ports de ces adresses vers le serveur. Cependant, rien ne les empêche de prendre une Ip dans la plage non bloquée par le fire-wall !
Maintenant, comment faire pour interdire l’accès au réseau à une machine par le soft, je n’en sais rien ! Je ne vois que des méthodes matérielles qui empêchent l’accès physique à toute connexion sur le réseau.
Vous pouvez gérer avec deux cartes réseaux différentes, deux réseaux différents (un réseau local et un DMZxi) si toutes fois, les masques associés permettent de bien différencier les deux réseaux. Le serveur DHCP le fait sans problème.
Le fichier /var/lib/dhcp/dhcpd.leases contient les informations suivantes : Début du bail, Fin du bail, adresse MAC du client, le nom d'hôte du client. Attention ce nom est différent du nom Netbios utilisé sur les réseaux Microsoft.
Voici un script fait par svil sur http://www.developpez.net/forums/viewforum.php?f=5
#!/bin/sh
# XXX.XX.XXX ta classe d'adresse
ipdeb=150
ipfin=254
#je recherche les machines allumées !
obtention d'un tableau contenant la liste des ip
adrip=($(fping
-g XXX.XX.XXX.$ipdeb XXX.XX.XXX.$ipfin -C 1 2>/dev/null |awk
'{print $1}'))
#parcours les ip en demandant la mac
correspondante
for ((i=0;i<${#adrip[@]};i++)); do
adrmac=`arp -a ${adrip[$i]}|tr 'a-z' 'A-Z'|awk '{print $4}'`
echo $adrmac
#le traitement que tu veux en faire ...
done
http://www.cryptos.ch/article.php3?id_article=44
Qu’est-ce qu’un Terminal Graphique ? Sur http://fr.wikipedia.org : « Les terminaux en mode graphique sont capables de présenter les sorties sous la forme d’une interface graphique. En plus d’un clavier, ils disposent d’un dispositif de pointage (souris). Pour cela, ils utilisent, par exemple, le protocole X Window pour ceux connectés à des serveurs Unix. »
Les données : un ordinateur puissant type 2,6 Ghz et 512Mo ram : IP = 192.168.0.1 (nom= serveur) Plusieurs ordis type P166 par exemple, 64 Mo mémoire ; je n’ai pas essayé avec moins... L’IP du premier est : 192.168.0.10 (nom = client1)
Il s’agit donc de faire fonctionner les "petits" ordis avec des applications récentes, avec une interface graphique « évoluée »...
Sur les ordis « clients » : : installer une mandriva en mode texte avec X, type IceWM ou Window Maker ou autre interface graphique légère ;
Sur le « serveur » :
- ne pas oublier de déclarer les utilisateurs.
- éditer /etc/kde/kdm/kdmrc et dans la section xdmcp, changer :
[Xdmcp] Enable=false Willing=/etc/X11/xdm/Xwilling Xaccess=/etc/X11/xdm/Xaccess
par :
[Xdmcp] Enable=true Willing=/etc/X11/xdm/Xwilling Xaccess=/etc/X11/xdm/Xaccess
Déporter l’affichage du « serveur » sur le client... Deux procédures :
(Surtout ne pas oublier d’enlever le pare-feu pour les besoins de l’essai et ensuite ouvrir le port 177 nécessaire à xdmcp et les ports 6000-6015 pour Xwindows)
- 1 - lancer le client et ouvrir une
session x avec un nom d’utilisateur qui existe sur le client et sur
le serveur... en console taper : $X -query adresse_du_serveur :1
par exemple : $X -query 192.168.0.1 :1 le :1 est toujours la
machine sur laquelle on se trouve, c’est-à-dire la vieille
machine ;
- 2 - KDE permet nativement la
connexion distante lancer le client et au login cliquer sur
menu->Connexion distante puis taper le nom d’hôte (= IP du
« serveur ») dans notre cas : 192.168.0.1 et cliquer
sur « connexion » ou taper « entrée ». Et
nous nous retrouvons avec le panneau de login de « serveur » :
taper le nom de l’utilisateur et le mot de passe...(L’utilisateur
bien sûr, sera inscrit parmi les utilisateurs du serveur...) Et la
session kde ou autre s’ouvre...
Le vieil ordi bénéficie de l ’affichage et de la puissance du « serveur » et de ses applis... C’est assez bluffant de voir ces vieux ordis tourner avec la rapidité d’un ordi neuf... !!! Toutes les applis de bureautique internet, photo peuvent fonctionner ainsi... En revanche, jeux, vidéo et son, ne fonctionneront pas ; le son fonctionnera à partir du client sur le serveur si sur le serveur est ouverte une session par le même utilisateur que sur le client... Notons aussi que le « serveur » acceptera l’ouverture de plusieurs sessions à la fois... sans problème...
Post Scriptum : Voilà
une solution qui permet de « recycler » de vieux
ordinateurs... D’autres solutions plus élaborées existent qui
permettent en particulier le son sur les clients qui sont classés en
« clients légers » et « clients lourds » :
LTSP, freenx, drakTermServ sur la Mandriva et sûrement d’autres...
Celle qui est présentée ici est sûrement la plus facile mais elle
oblige à installer un système et X sur le client, ce qui n’est
pas forcément facile sur de vieilles machines...
Merci à http://christian.caleca.free.fr et à http://www.security-labs.org/index.php3?page=413
http://www.postfix.org/non-english.html#french
Nous allons installer un MTA : Message (ou Mail) Transfert Agent. Agent de transfert de message (ou de courrier), qui s'occupe de l'acheminement des messages. Le démon est postix. Pour installer : « urpmi postfix » (ne pas oublier imap ou uw-imapd pour la suite… voir le point E). Puis démarrez-le :
[root@troumad][~]$ postfix reload
postfix: warning: My hostname troumad is not a fully qualified name - set myhostname or mydomain in /etc/postfix/main.cf
postfix/postfix-script: warning: My hostname troumad is not a fully qualified name - set myhostname or mydomain in /etc/postfix/main.cf
postfix/postfix-script: refreshing the Postfix mail system
postsuper: warning: My hostname troumad is not a fully qualified name - set myhostname or mydomain in /etc/postfix/main.cf
[root@troumad][~]$ postsuper: warning: My hostname troumad is not a fully qualified name - set myhostname or mydomain in /etc/postfix/main.cf
vi /etc/postfix/aliases
Si vous voulez modifier le nom du domaine ou de l'hôte sur /etc/postfix/main.cf en modifiant les paramètres myhostname ou mydomain. Ceci est obligatoire si le couple PC/domaine est trop peu qualifié comme ici.
Les aliases servent à rediriger les messages entrants pour un utilisateur vers un autre utilisateur. Le fichier /etc/postfix/aliases est là pour définir des sortes de redirections. En l'observant, vous constaterez qu'il existe beaucoup d'utilisateurs "fantômes", tous renvoyés vers "root". Il faut savoir que Postfix n'a en principe pas le droit d'envoyer des messages à root. Vous avez, bien sûr, sur votre machine Linux, un compte d'utilisateur "normal" (pas root). C'est le moment de modifier le fichier des "aliases" pour rediriger "root" vers cet utilisateur. Il faut le faire, c'est impératif. Sur ma configuration, il existe un compte "chris" et la dernière ligne de /etc/postfix/aliases est de la forme :
root: courrier
Faites la modification adaptée à votre utilisateur et vérifiez dans /etc/postfix/main.cf la présence de :
alias_maps = hash:/etc/postfix/aliases (sans le # devant)
Puis exécutez :
postalias /etc/postfix/aliases
postfix reload
Il existe d'autres sortes d'alias ( voir http://www.toolinux.com/linutile/reseau/mail/postfix/index.htm ). Le plus intéressant consiste à rediriger le mail vers une autre boîte aux lettres, avec /etc/postfix/canonical :
troumad@lycee.org troumad@free.fr # adresse gérée par postfix vers une autre adresse
Cette ligne fait suivre le courrier vers l'adresse troumad@free.fr d'un autre serveur de mail. Faire « postmap /etc/postfix/canonical », mettre canonical_maps = hash:/etc/postfix/canonical dans main.cf et relancer postfix : « /etc/init.d/postfix reload ».
Dans /etc/postfix/aliases vous pouvez rediriger vers plusieurs adresses la même adresse :
groupe: toto titi@free.fr toutou@libertysurf.fr tata tonton@chello.fr
Soit il existe un fichier de logs très utile pour nous : /var/log/mail/info et nous utiliserons en permanence dans la suite. Ouvrez une console sous root et faites :
tail -f /var/log/mail/info
Soit nous regarderons avec la commande journalctl (pour les versions de linux avec systemctl) :
journalctl -u postfix -b
Ceci vous permettra de suivre ce qu'il se passe plus facilement.
Nous allons, en restant complètement en local, envoyer un message à root, en étant l'utilisateur normal, celui que nous avons choisi comme alias de root, et que nous avons convenu d'appeler "user".
Ouvrez une deuxième console avec le compte courrier.
Nous allons envoyer un message à "root" avec l'outil, spartiate, certes, mais installé par défaut dans Mandriva/Mageia : « mail » il s’installe avec « apt-get install mailx » sous debian.
mail root
Subject: rien
rien
Cc:
À la fin du texte faire [Entrée] + Ctrl-D pour finir la zone de texte. Ou mettre une ligne avec uniquement un point.
Observons le journal dans la console root :
Oct 11 22:31:32 troumad postfix/pickup[17603]: 5091C1201F9: uid=0 from=<root>
Oct 11 22:31:32 troumad postfix/cleanup[17608]: 5091C1201F9: message-id=<20031011203132.5091C1201F9@lycee.org>
Oct 11 22:31:32 troumad postfix/nqmgr[17604]: 5091C1201F9: from=<root@lycee.org>, size=308, nrcpt=1 (queue active)
Oct 11 22:31:32 troumad postfix/local[17611]: 5091C1201F9: to=<courrier@lycee.org>, orig_to=<root>, relay=local, delay=0, status=sent ("|/usr/bin/procmail -Y -a $DOMAIN")
Tout semble bien s'être passé. Notez que le destinataire n'est pas root mais courrier, le système d'alias a fonctionné correctement. Nous devons donc retrouver ce message dans notre boîte aux lettres (celle de courrier) :
La commande "mail" toute seule permet de consulter ses messages. La partie surlignée indique un nouveau message. Nous tapons :
[courrier@troumad][~]$ mail
Mail version 8.1.1 6/6/93. Type ? for help.
"/var/spool/mail/courrier": 1 message 1 new
>N 1 root@troumad.no-ip.o Sat Oct 11 22:31 14/449 "rien"
& t 1
Message 1:
From root@lycee.org Sat Oct 11 22:31:32 2003
X-Original-To: root
Delivered-To: root@lycee.org
To: root@lycee.org
Subject: rien
Date: Sat, 11 Oct 2003 22:31:32 +0200 (CEST)
From: root@lycee.org (root)
rien
& ?
Mail Commands
t <message list> type messages
n goto and type next message
e <message list> edit messages
f <message list> give head lines of messages
d <message list> delete messages
s <message list> file append messages to file
u <message list> undelete messages
R <message list> reply to message senders
r <message list> reply to message senders and all recipients
pre <message list> make messages go back to /usr/spool/mail
m <user list> mail to specific users
q quit, saving unresolved messages in mbox
x quit, do not remove system mailbox
h print out active message headers
! shell escape
cd [directory] chdir to directory or home if none given
& x
Quand mail nous laisse la main, on a une ligne avec un « & ». On tape alors les commandes. Ici « t 1 » puis « , » et « x ».
Après cet essai, vous pouvez recommencer vers une adresse extérieure. « mail troumad@free.fr ». Il est possible que celui-ci revienne, regardons le journal :
Oct 12 07:29:58 troumad postfix/pickup[24570]: ED7801201F9: uid=501 from=<troumad>
Oct 12 07:29:58 troumad postfix/cleanup[24630]: ED7801201F9: message-id=<20031012052958.ED7801201F9@lycee.org>
Oct 12 07:29:58 troumad postfix/nqmgr[24571]: ED7801201F9: from=<troumad@lycee.org>, size=287, nrcpt=1 (queue active)
Oct 12 07:29:59 troumad postfix/smtp[24632]: ED7801201F9: to=<troumad@free.fr>, relay=mx.free.fr[213.228.0.166], delay=1, status=bounced (host mx.free.fr[213.228.0.166] said: 553 sorry, your envelope sender domain must exist (#5.7.1) (in reply to MAIL FROM command))
Oct 12 07:30:00 troumad postfix/cleanup[24630]: 02B841201FC: message-id=<20031012053000.02B841201FC@lycee.org>
Oct 12 07:30:00 troumad postfix/nqmgr[24571]: 02B841201FC: from=<>, size=2020, nrcpt=1 (queue active)
Oct 12 07:30:00 troumad postfix/local[24634]: 02B841201FC: to=<troumad@lycee.org>, relay=local, delay=0, status=sent ("|/usr/bin/procmail -Y -a $DOMAIN")
Selon la machine qui héberge le MTA, l'expéditeur à une adresse qui n'existe pas : lycee.org n'existe pas, le courrier a donc été refusé ! Il faut donc définir un nom d'envoi correct ! On va changer l'adresse de l'expéditeur en réécrivant la redirection dans le fichier /etc/postfix/sender_canonical : courrier troumad@free.fr
Après, on fait « postmap /etc/postfix/sender_canonical » et on rajoute la ligne
« sender_canonical_maps = hash:/etc/postfix/sender_canonical » à /etc/postfix/main.cf au paragraphe « ADDRESS REWRITING ».
Parfois, dans le journal, on trouve :
Nov 10 14:59:43 troumad postfix/nqmgr[32697]: 7B3B9502D3: to=<______.______@francetelecom.com>, relay=none, delay=0, status=deferred (deferred transport)
Nov 10 14:59:43 troumad postfix/nqmgr[32697]: 7B3B9502D3: to=<troumad@free.fr>, relay=none, delay=0, status=deferred (deferred transport)
Ceci peut être momentanément réparé par :
/etc/init.d/postfix flush
Qui donne dans le journal :
Nov 10 14:59:56 troumad postfix/smtp[5953]: 7B3B9502D3: to=<______.______@francetelecom.com>, relay=relais-inet.francetelecom.com[212.234.67.6], delay=13, status=sent (250 Message received and queued)
Nov 10 14:59:56 troumad postfix/smtp[5955]: 7B3B9502D3: to=<troumad@free.fr>, relay=mx.free.fr[213.228.0.49], delay=13, status=sent (250 ok 1068472817 qp 2927)
Il faut donc reconfigurer /etc/postfix/main.cf, c'est le paramètre « defer_transports = smtp » qu'il fallait commenter car il sert à envoyer le courrier que sur demande : « postfix flush » ou « sendmail -q » avec par exemple un petit script PPP dialout, donc lorsqu'on est pas toujours connecté. Dans les distributions Mandriva, /etc/ppp/if-up contient déjà une commande « sendmail -q » si « /usr/sbin/sendmail » existe. Donc pas la peine de le faire à la main : à chaque connexion, « sendmail -q » devrait être lancé automatiquement.
Après chaque modification de /etc/postfix/main.cf , il faut complètement relancer le service, un simple reload est insuffisant. On doit donc faire :
/etc/init.d/postfix restart
Même valide, si c'est VOTRE nom de domaine, il n'est sûrement pas reconnu, lister dans la liste des serveurs de mails sûr. En effet, il y a tellement de petits domaines que seul les grands serveurs peuvent être reconnus, comme free.fr, aol.com... Si j'achète lycee.org et que je gère moi-même ce domaine il a peu de chance d'être reconnu ! En revanche, s'il est piraté et sert de base d'envoi à des spams, il sera vite mis dans la liste noire des noms de domaine à éviter !
Voici une méthode pour que vos mails arrivent même sur les serveurs qui mènent une politique forte de tri sécurisé ( http://www.linuxorable.net/article.php3?id_article=47 ) :
La règle transport_maps permet de définir quel mode de
transport sera utilisé pour certains domaines ou adresses.
Exemple:
AOL refuse tous les mails qui ne proviennent pas de serveurs SMTP
connus.
Donc, je vais mettre dans ma table « transport » des lignes comme ceci:
mon-ami1@aol.com smtp:smtp.free.fr
mon-amie@aol.com smtp:smtp.free.fr
ou, si je souhaite une règle générale:
ainsi, tout mail à destination de AOL sera relayé par le serveur smtpd de Free après avoir fait les deux commandes suivantes :
# postmap /etc/postfix/transport
# postfix reload
Il faut ouvrir le port 110 vers les ordinateurs qui vont lire leur courrier sur votre serveur. Attention, dès qu'on parle de l'extérieur, il faut se méfier des spameurs qui seraient bien heureux de prendre le contrôle de notre MTA!
Ensuite,
sous
Illustration 4 : Paramétrage d'un compte sous mozilla/
thunderbird
Sous debian : « apt-get install qpopper ».
Il faut faire une modification minimale de la configuration. Dans /etc/postfix/main.cf, le paramètre inet_interfaces doit indiquer d'où on accède au serveur et aussi il peut être utile de relancer ou mettre en route le démon xinetd : /etc/init.d/xinetd restart
Finalement, on doit paramétrer notre lecteur de courriel convenablement :
Pour lire le courriel sur ce serveur : donner le nom du serveur, le nom d'utilisateur (le nom de login du compte que vous avez)
Sous thunderbird, ceci se fait avec l'entrée « Paramètres serveur ». Le port est bien le 110 : attention, prévoir le fire-wall pour que ce port soit ouvert en direction des ordinateurs qui doivent lire le courriel.
Pour envoyer le courrier à partir de mozilla, donner l'adresse de notre serveur pour le courrier sortant : troumad.lycee.org (d'après la configuration du DNS)
Avec thunderbird, Il faut tout d'abord signaler son existence en cliquant sur serveur sortant (SMTP) et en donnant son nom.
Ensuite, il faut signaler que le compte qu'on est en train de tester doit utiliser ce serveur sortant : avec le bouton [Avancé…] en bas à droite lorsque c'est l'entrée du compte qui est sélectionnée.
Vielle remarque : il faut configurer le nom du serveur deux fois car on peut lire son courrier sur tous les serveurs de tous les FAI d'où qu'on soit, mais par mesure de sécurité, les serveurs ne relaient que les mails qui viennent de leur domaine. Par exemple, vous ne pouvez pas utiliser le serveur de l'IUT pour envoyer vos mails de chez vous alors que de chez vous, vous pouvez lire le courrier qui vous est adressé à l'IUT.
Nouvelle remarque : maintenant, pour envoyer des courriels, il faut s'authentifier, donc, pas besoin de changer la configuration en fonction d'où nous sommes connectés à internet.
Votre serveur est en marche ? Alors ouvrez le port 25 vers l'extérieur, c'est tout !
Attention, il faut configurer la ligne suivante dans /etc/postfix/main.cf :
mydestination = $myhostname,$mydomain
Elle interdit le relais à partir de l'extérieur de mail vers d'autres adresses que celles du domaine local. Vous pouvez vous demander « Alors, mais comment mon serveur repère les PC du réseau interne ? ». C'est avec la ligne de /etc/postfix/main.cf :
mynetworks = 127.0.0.0/8,192.168.0.0/16
Cette ligne permet à tous les PC du sous réseau 192.168.XXX.XXX et aussi au serveur lui-même (127.0.0.0/8) d'accéder au serveur de mail pour lui faire envoyer des courriers à n'importe quelle adresse.
Il faut que le fire-wall ouvre le port 25 (comme précédemment) vers l'endroit d'où on envoie le couriel. Ensuite, la configuration du lecteur de courrier est expliquée dans la rubrique : « Troisième test : lire le courrier de l'extérieur ». Il est important de bien maîtriser l'« extérieur » choisi. Je vous conseille de le restreindre à votre réseau local. Dans ce cas « extérieur » sera simplement « aux autres PC ». C'est ce que font les FAI afin de contrôler l'origine des mails pour éviter de servir de relais aux spameurs.
Si notre serveur sert aussi de passerelle (avec une interface vers le réseau local et une autre vers internet, voir chapitre sur le fire-wall), on peut indiquer dans la configuration de postfix, que seul les mails du réseau local seront pris en compte.
Merci à http://www.via.ecp.fr/~alexis/formation-linux/ pour cet exemple et à http://cjovet.free.fr/cours/postfix.htm.
# /etc/postfix/main.cf
# Fichier de configuration de Postfix
# Formation Debian GNU/Linux par Alexis de Lattre
# http://www.via.ecp.fr/~alexis/formation-linux/
# Pour plus d'informations, installer le package "postfix-doc"
# et lire /usr/share/doc/postfix/html/index.html
# ou lire la traduction française disponible à l'adresse
# http://cjovet.free.fr/cours/postfix.htm
# Paramètres de fonctionnement de postfix
# NE PAS CHANGER
command_directory = /usr/sbin
daemon_directory = /usr/lib/postfix
program_directory = /usr/lib/postfix
smtpd_banner = $myhostname $mail_name (Mandriva LINUX)
setgid_group = postdrop
biff = no
# Nom du fichier d'alias
alias_maps = hash:/etc/postfix/aliases
#alias_database = hash:/etc/mail/aliases
# Nom du fichier de correspondance pour les adresses virtuelles
#virtual_maps = hash:/etc/postfix/virtual
# Nom de domaine
# Ce paramètre ne sert pas directement, mais peut être utilisé par la suite.
mydomain = lycee.org
# Nom d'hôte
# Ce paramètre ne sert pas directement, mais peut être utilisé par la suite.
myhostname = troumad.$mydomain
# Extension pour les mails envoyés depuis la machine
myorigin = lycee.org
# Liste des domaines pour lesquels le serveur accepte le mail
# ET délivre le mail en local
mydestination = $myhostname, localhost.$mydomain,localhost
# le paramètre inet_interfaces doit indiquer d'où on accède au serveur pour l'envoi de courrier
inet_interfaces = $myhostname, localhost.$mydomain, localhost,$mydomain
# Liste des domaines pour lesquels le serveur accepte le mail
# ET le relaie à d'autres serveurs de mail
#relay_domains =
# Dans le cas où on a besoin d'un serveur pour relayer les mails sortants :
#relayhost = smtp.free.fr
# #defer_transports = smtp peut être utile si on n'est pas souvent connecté à internet.
# Il Faut alors faire un sendmail -q pour envoyer les mails lors de la connexion.
#defer_transports = smtp
# Réseaux en lesquels j'ai confiance
# i.e. pour lequel mon serveur mail accepte de relayer du mail
# ATTENTION : il ne faut pas mettre n'importe quoi pour que le serveur
# mail ne devienne pas un relai pour le spam !
mynetworks = 127.0.0.0/8,192.168.1.0/24
# Commande à exécuter pour délivrer les mails en local
mailbox_command = /usr/bin/procmail -Y -a $DOMAIN -d $LOGNAME
# Taille maximale pour les mailbox (0 = pas de limite)
mailbox_size_limit = 0
#Les lignes suivantes sont quelque peu paranos...
#connexion d'un client sur le serveur de mail :
# - rejète le client si son adresse IP n'a pas d'enregistrement PTR dans le DNS.
# - juste pour le réseau interne
# - accepte ou rejète le client selon les régles du fichier spécifie hash:/etc/postfix/access
smtpd_client_restrictions = permit_mynetworks,reject_unknown_client,check_client_access hash:/etc/postfix/access
# vérifie le champ MAIL FROM du mail
# - rejète la requête si l'adresse de l'émetteur n'a pas d'enregistrement A ou MX dans le DNS.
# - accepte ou rejète la requête selon les règles du fichier /etc/postfix/access
# - la requête est rejetée si l'adresse email n'est pas un nom de domaine complet
smtpd_sender_restrictions = reject_unknown_sender_domain, check_sender_access hash:/etc/postfix/access,reject_non_fqdn_sender
#
Pour /etc/postfix/access : 'man 5 access' et à chaque
modification 'postmap /etc/postfix/access'
#
Afin de vérifier votre configuration, vous pouvez faire « postconf », ceci affichera TOUS les paramètres de postfix, mêmes ceux choisi par défaut. Pour afficher les différences de votre configuration avec celle par défaut, entrez « postconf -n ». Pour vérifier la configuration du serveur, lancez « postfix check ».
Le fichier access qui indique à partir d'où on peut poster un mail :
192.168 OK
127 OK
10 NO
Pour faire un petit filtre de pièce jointe, dans le fichier main.cf de postfix, il faut ajouter :
header_checks = regexp:/etc/postfix/header_checks
puis créer le fichier /etc/postfix/header_checks qui contient la ligne suivante (sur une seule ligne) :
/^.*name=.*\.(vbe|vbs|shs|vbx|zip|chm|exe|pif|bat|com|scr)/ REJECT "les fichiers : vbe vbs shs vbx chm exe pif bat com scr zip sont interdits comme piece jointe - message refuse"
Vous pouvez, par exemple, tester votre serveur à http://abuse.net/relay.html .
http://spamassassin.apache.org/
http://lea-linux.org/cached/index/Reseau-message-postfix.html
« urpmi spamassassin-spamd » installe le logiciel
« /etc/rc.d/init.d/spamd start » le met en route.
thunderbird et mozilla-mail ont cette fonctionnalité directement implémentée dans leur code avec le tri des indésirables.
Il en existe des utilitaires, testez : « urpmi spamassassin- ».
http://mdk.services-virtuavision.com/article.php3?id_article=60 : Fetchmail - postfix - procmail - razor2 - MUA : les Dalton anti-spam.
http://www.ac-creteil.fr/reseaux/systemes/linux/nis-linux.html
Le
service NIS
(Network Information System), permet de centraliser les connexions
sur un réseau local. L'objectif central de tout
serveur de fichiers d'un réseau local est de permettre aux
utilisateurs du réseau de se connecter au serveur de fichier sous un
compte centralisé au niveau du réseau, et non pas défini machine
par machine et aussi d' accéder à ses fichiers (répertoire
personnel, ...).
Dans un réseau homogène Linux, la connexion et l'authentification sont du ressort du service NIS, tandis que les accès aux répertoires personnels et partagés sont permis par le service complémentaire NFS, qu'il faut aussi mettre en oeuvre. Pour utiliser des stations M$-Windows dialoguant avec un serveur Linux, l'alternative à NIS+NFS est la mise en oeuvre du serveur Samba.
NIS maintient une base de données (ou annuaire) centralisée au niveau d'un groupe de machines appelé domaine NIS. Supposons que le nom NIS attribué soit Maison. Ces informations sont alors stockées dans le répertoire /var/yp/Maison, sous forme d'un ensemble de fichiers binaires appelés cartes ou maps.
Les types d'informations que les stations "clientes", celles des utilisateurs, viennent chercher sont essentiellement les correspondances entre noms et adresse IP des machines du réseau, les vérifications des noms de login, mots de passe et groupes d'appartenance des comptes utilisateurs existants sur le serveur. Toutes ces informations sont contenues habituellement dans les fichiers /etc/hosts (annuaire des machines connues), /etc/passwd, (annuaires des utilisateurs qui contient les répertoires à la connexion) et /etc/group (annuaire des groupes) et /etc/shadow (mots de passe cryptés).
Plus concrètement, soit une station Linux, cliente du serveur NIS. Un utilisateur remplit un formulaire de connexion (demande de login). Le client NIS de cette station cherche à obtenir une réponse du serveur NIS du même domaine, à une question du genre "me connais-tu comme station autorisée, et l'utilisateur que j'accueille possède t-il un compte chez toi, mon serveur?"
Les réponses sont contenues dans 6 maps usuels, situés dans /var/yp/Maison, et appelés hosts.byname, hosts.byaddr, passwd.byname, passwd.byuid, group.byname et group.bygid.
Les applications NIS
utilisent les fonctions RPC =Remote Procedure Calls,
fonctionnalités supplémentaires (logées dans la couche session au
dessus de TCP/IP), gérées par un service (ou démon) appelé
portmap qu'il faut donc installer.
Le rpm à installer est ypserv sur le serveur et yp-tolls et ypbind sur les stations clientes.
Un peu de précision sur le vocabulaire : yp (yellow pages) correspond à l'annuaire, NIS est l'implémentation basée sur RPC pour les mots de passes partagés, les groupes, les services, ... NIS+ est une implémentation plus sécurisée. NYS est la version domaine public de NIS.
Les services à lancer sont dans l'ordre /etc/init.d/portmap, /etc/init.d/ypserv et /etc/init.d/yppasswd. Les fichiers de configuration sont: /etc/ypserv.conf (configuration du serveur) et les fichiers du répertoire /var/yp comme /var/yp/securenets (machines autorisées à accéder au service NIS), /var/yp/Makefile, mais il y a besoin d'en modifier d'autres comme /etc/sysconfig/network.
Il faut déclarer le domaine NIS dans le fichier /etc/sysconfig/network en rajoutant la ligne NISDOMAIN=Maison. Il faut que ce paramettre soit pris en compte, pour le moment, je n'ai trouvé qu'une seule solution : « domainname Maison ».
Ensuite, il faut déclarer les machines qui ont accès au domaine avec le fichier /var/yp/securenets et insérer les lignes suivantes :
# pour permettre l'accès sur le serveur même
255.0.0.0 127.0.0.0
# pour permettre l'accès de toutes les machines du sous-réseau (masque et adresse réseau)
255.255.255.0 192.168.1.0 # le réseau à comme adresse 192.168.1.1, le réseau est 192.168.1.XXX
Préciser les informations que NIS doit gérer en éditant le fichier /var/yp/Makefile et en listant sur la ligne commençant par all: les données à gérer : all: passwd group hosts (au moins). Il est recommandé de ne rien modifier d'autre sauf "si on sait ce que l'on fait ...", car pour l'essentiel il a été correctement paramétré lors de l'installation de la distribution.
Ensuite, on doit générer les 3 cartes (maps) correspondant aux 3 fichiers /etc/passwd, /etc/group et /etc/hosts. L'utilitaire /usr/bin/make doit être exécuté par root dans le répertoire du Makefile :
# cd /var/yp
# make
Il y a création d'un sous-répertoire /var/yp/Maison (portant le nom du domaine NIS, qui doit être pris déjà en compte) contenant les 6 fichiers binaires de permissions 600 : hosts.byname, hosts.byaddr, passwd.byname, passwd.byuid, group.byname et group.bygid.
La dernière manipulation à faire est de renseigner le fichier de configuration de NIS : : /etc/ypserv.conf et indiquer l'adresse IP du réseau comme ci-dessous :
# Host : Domain : Map : Security
#
192.168.1. : Maison : passwd.byname : port
192.168.1. : Maison : passwd.byuid : port
ypxfrd est utile si on a un serveur NIS esclave.
Toujours
dans /etc/sysconfig/network,
il faut mettre NISDOMAIN
= "Maison".
Attention, il faudra activer ce nom!
Dans
/etc/yp.conf,
et il faut ajouter les 2 lignes :
domain Maison server 192.168.1.1
ypserver troumad #nom du serveur NIS
Dans
/etc/nsswitch.conf, veillez à la
présence active des lignes :
passwd: files nis
group: files nis
hosts: files nis dns
En ligne de commande, (re)lancer le service client. On devrait obtenir 2 messages : recherche d'un domaine NIS, puis tentative de liaison à un serveur NIS.
$ /etc/rc.d/init.d/ypbind start
Binding to the NIS domain: [OK]
Listening for an NIS domain server: fctice.ac-creteil.fr
Pour permettre à un compte qui existe uniquement par NIS, mais pas dans le fichier local /etc/passwd de se logger par ssh, dans le fichier /etc/ssh/sshd_config, il faut décommenter la ligne UseLogin et mettre yes comme paramètre.
On rajoute sur le serveur un nouvel utilisateur avec « useradd ». Pour prendre en compte ce nouvel utilisateur; il suffit d'aller dans le répertoire /var/yp et d'exécuter « make ».
Lorsque l'on utilise
NYS et les mots de passe distribués, la commande « passwd »
sur un client risque de ne pas avoir le comportement attendu puisque
qu'elle va éditer le fichier local /etc/passwd.
C'est donc le démon
yppasswd du serveur qui doit se charger de cela. En fait
lorsqu'un utilisateur voudra changer son mot de passe, il utilisera
la commande « yppasswd »,
qui ira modifier le fichier /etc/passwd
du serveur NYS, et qui également mettra à jour les cartes, en
faisant appel aux fonctions de notre bon démon.
Pour que l'utilisation
de « yppasswd »
soit transparente pour les utilisateurs, vous pouvez renommer le
fichier /usr/bin/passwd
en lpasswd
par exemple, et ensuite vous faites un lien passwd
vers yppasswd
avec la commande :
« ln
-sf yppasswd passwd »
Les utilisateurs pourront ainsi changer leur mot de passe sans se rendre compte qu'ils utilisent un compte NYS.
Une imprimante sur un PC peut être partagée entre plusieurs PC en réseau. Pour savoir comment définir son partage, il faut savoir sur quelle sorte de réseau elle est partagée. En effet, sur le PC qui a l'imprimante, on installe déjà un service CUPS (serveur d'impression local) qui peut servir pour tout le réseau s'il est correctement défini. En revanche CUPS est fait uniquement pour les réseaux Linux/Unix. Si il y a des PC sous Windows, le partage se définit avec Samba (voir le chapitre sur samba).
http://people.via.ecp.fr/~alexis/formation-linux/imprimante.html#AEN11363
Il faut installer l'imprimante. Ceci est automatique avec Mandriva, en revanche avec debian, il est recommandé d'installer avant certains paquetages :
# apt-get install cupsys cupsys-client cupsys-bsd foomatic-filters printconf
Cette ligne devrait tout installer, mais je conseille tout de même après un passage par « foomatic-gui » afin de parfaire la configuration.
Avec Mandriva, ce service est directement configuré pour le partage. En revanche sous debian, il faut ouvrir le service à l'extérieur. C'est le fichier /etc/cups/cupsd.conf qu'il faut modifier afin d'avoir :
<Location />
Order Deny,Allow
Deny From All
Allow From 127.0.0.1
Allow From 192.168.0.0/255.255.255.0
</Location>
Puis bien sur, après la modification, il faut relancer le serveur.
/etc/init.d/cupsys restart (ou cups pour Mandriva)
La liste des travaux effectués reste en mémoire avec possibilité de les refaire. Avec la commande, on peut l'effacer avec la liste des travaux en attente :
# cancel -a
Sur Mandriva, tout est encore automatique. Avec debian, il faut installer le programme client de Cups :
# apt-get install cupsys-client
Ensuite, éditez le fichier /etc/cups/client.conf et décommentez la ligne commençant par ServerName. Sur cette ligne, vous devez alors préciser l'adresse IP ou le nom DNS du serveur d'impression.
Par exemple, si votre serveur d'impression a l'adresse IP 192.168.0.42, le fichier /etc/cups/client.conf devra contenir :
ServerName 192.168.0.42
Attention : le champ « emplacement » sur le serveur devra être bien configuré. En effet, il est possible que le client s'en serve pour appeler le serveur. Donc il devra être renseigné de la même façon dans /etc/hosts ou par le serveur DNS, afin que le PC ayant l'imprimante réponde bien au nom défini dans ce champ.
Voir man saned
Il est possible, comme pour les imprimantes de partager un scanner. Voici la manipulation à faire :
Pour le serveur, mettre dans le fichier /etc/sane.d/saned.conf :
192.168.3.0/24 # Pour partager sur toute machine d'adresse 192.168.3.XXX
localhost # Pour le PC local aussi
De son côté, le client doit avoir le fichier /etc/sane.d/net.conf :
nom_du_serveur # ou ip du serveur
De marc guillaume <new at yakati point org>
Adapté à Mandriva par Bernard SIAUD
Voir aussi : http://www.openbsd.org/cgi-bin/man.c...penBSD+Current
Qu’un laboratoire de métrologie, de sismique, de physique aie besoin d’une heure très précise semble évident. Mais pour un particulier ou une petite entreprise l'intérêt peut sauter moins immédiatement aux yeux. Pourtant, ne serait-ce que pour envoyer des mails avec une date cohérente, il est important que vous surveilliez la date de votre PC. Si vous avez des serveurs, cela devient indispensable. Imaginez que tous vos postes aient leur répertoire /home déporté sur un serveur central. Si vous mettez en place un système de mirorring avec rsync par exemple sur un serveur de sauvegarde que va-t-il se passer si vos machines ont des heures différentes ? Vous allez perdre la cohérence entre les fichiers et ne plus savoir au bout d'un moment quelle est la dernière version d'un fichier.
NTP (Network Time Protocol) résout cela en fournissant un moyen simple et efficace de synchroniser tout ce petit monde. Si vous avez un accès permanent à internet (style ADSL ou Câble) vous serez de plus à l'heure mondiale sans effort.
Vous trouverez sur internet de la documentation sur les principes de fonctionnement du protocole Network Time Protocol (ntp) mis au point par l'équipe du professeur David Mills de l'université du Delaware. Ce qui suit est fortement inspiré de http://www.starlinux.net/staticpages/index.php?page=20030924221349147
En gros il s'agit d'une hiérarchie dynamique de serveurs. Au sommet sont des serveurs dits de strate 0. Il s'agit des horloges de précision qui peuvent être des horloges atomiques au césium ou des satellites GPS (globa positionning system) par exemple. Aucun ordinateur ne fait partie de la strate 0. Les ordinateurs dits de strate 1 reçoivent l'heure de ces horloges qui composent la strate 0.
Donc ces ordinateurs de strate 1 reçoivent l'heure des ordinateurs de strate 0. La strate 1 est la précision maximale qui puisse être atteinte sur internet.
Quand un ordinateur prend comme référence un serveur de strate 1 il devient un serveur de strate 2. De manière générale quand un ordinateur prend comme référence un serveur de strate n il devient lui-même un serveur de strate n+1.
Le plus bas niveau est la strate 16 qui signifie en fait que l'ordinateur n'est pas encore synchronisé (ce qui se passe lorsque vous lancez pour la première fois ntpd, ou que votre serveur de référence n'est pas joignable pendant un temps suffisant).
Il y a sur internet une petite centaine de serveurs de strate 1 qui sont pris comme référence par quatre mille (à peu près) serveurs de strate 2 qui à leur tour sont utilisés par un bien plus grand nombre de serveurs de strate 3.
Le système est dynamique dans la mesure où un serveur peut être à un moment en strate 3 ou en strate 2 et même en strate 16 quand il perd sa synchronisation. Tout dépend du serveur sur lequel il parvient à se synchroniser.
Au démarrage du démon ntpd le système lit ses fichiers de configuration, parmi lesquels il trouve :
Les adresses IP ou les noms des serveurs de référence (peers)
Les intervalles maximaux et minimaux entre deux consultations de serveurs (maxpoll et minpoll)
la correction de son horloge interne, si l'information est disponible
D'autres paramètres comme des options de log, des restrictions d'accès etc.
En utilisant la liste des serveurs ou peers, il demande une information horaire à tous. Dans cette information, en plus de l'heure, sont inclues des informations sur le temps pris par le paquet pendant sa traversée du réseau, sur la stabilité et la qualité des serveurs.
En même temps, si le démon a tourné suffisamment longtemps dans une session antérieure, il lit la dernière correction qu'il faut appliquer à la fréquence de l'horloge interne pour maintenir l'heure exacte dans la fourchette adéquate. Chaque horloge de chaque ordinateur compte le temps en cycles donnés par les oscillateurs internes. NTP est capable de renseigner le noyau (kernel) sur les erreurs que peuvent induire ces oscillateurs (problèmes de fréquences de quartz etc.).
En début de session l'ordinateur suppose qu’il n'est pas synchronisé. Il commence à lire l’information horaire des ses "peers" à un rythme rapide de toutes les 16 secondes (en fait 2^minpoll) puis toutes les 32 secondes puis encore plus tard toutes les 64 secondes ainsi jusqu'à un rythme de 2^maxpoll secondes (par défaut maxpoll est réglé à 10).
Chaque fois qu'il reçoit une nouvelle référence de temps d'un de ses peers le démon ntpd reclacule les paramètres de ce peer, c'est à dire son déphasage par rapport à l'horloge locale, le retard sur le réseau et la dispersion des données. A la suite de cela il élit comme référence le meilleur et seulement le meilleur des peers avec lesquels il est en contact, dès qu'ils ont atteint un minimum de qualité.
Quand il estime avoir atteint les conditions minimales de stabilité notre ordinateur se déclare synchronisé et acquière la strate n+1 si le peer élu est en strate n.
Plus le temps passe, plus les corrections que fait ntpd sont fiables, le système est plus stable et l'intervalle entre deux consultations des peers va en augmentant. L'erreur maximale que s'autorise le système est de 128 millisecondes par défaut. Si cette limite est dépassée le système se considère de nouveau comme non synchronisé et tout repart comme au premier lancement. C'est très rare que cela arrive (sauf problème réseau) et un pc standard de particulier peut très facilement conserver une erreur maxi de 2 millisecondes avec une bonne stabilité (ce qui pour tous les usages courants est même "luxueux").
Les corrections d'horloge interne peuvent aller jusqu'à 500 partie par million (ppm). En pratique 12 ppm équivaut à une dérive de 1 seconde par jour. Sur du matériel standard la correction est souvent entre 30 et 150 ppm. Mais cela peut varier grandement si la température des quartz subit des variations importantes. En gros si vous avez une salle machines climatisée vous aller rester plus stable que si votre pc est derrière la fenêtre et que le soleil le chauffe la journée.
Nous allons prendre un cas de figure qui devient courant avec l'ADSL : vous avez un pc sous linux qui sert de passerelle nat et firewall entre internet et les postes clients (le votre sous Linux, le Mac de votre épouse et le PC windows du gamin, ben ouais à cause de jeux...).
Vous voudriez que tout ce petit monde soit à la même heure entre eux et si possible à l'heure avec le reste du monde.
La technique la plus logique est de vous créer un serveur de temps local afin de diminuer le trafic inutile sur internet. Il semble logique d'utiliser la machine passerelle pour fournir ce service. On a vu que plus le démon ntpd tournait longtemps plus il devenait stable et précis. Donc cette machine qui vous relie à internet et ne s'arrête jamais est la place idéale pour ce type de service.
Le schéma que nous avons choisi nous permet de présenter pratiquement toutes les utilisations de ntp pour le particulier ou la PME/PMI. Il nous manquera juste l'ouverture sur internet afin de devenir nous même serveur de temps pour d'autres uilisateurs (mais ce serait très facile si vous aviez une IP fixe et un nom de domaine).
Installation Mandriva : « urpmi ntp ».
Installation debian : « apt-get install openntpd »
On veut que notre passerelle se mette à l'heure sur des serveurs de temps de l'internet et que les machines de notre réseau puissent l'interroger comme elles interrogeraient un serveur de temps externe.
Si vous êtes en France Métropolitaine vous trouverez à l'adresse ci-dessous une liste de serveurs de temps publics dont les précisions sur les conditions d'utilisation sont précisées au cas par cas.
http://www.cru.fr/NTP/serveurs_francais.html ou http://www.pool.ntp.org/zone/europe
Une bonne politique est de choisir 5 serveurs différents pour être certain que l'un d'eux sera toujours accessible en synchronisation. Vous pourriez n'en mettre qu'un, mais si vous perdez la liaison avec lui, vous perdez votre synchro.
Les informations nécessaires à ntpd figurent dans le fichier /etc/ntp.conf pour Mandriva ou /etc/openntpd/ntpd.conf pour debian.
Le fichier présente deux sections, une section qui fournit les informations nécessaires à la mise à l'heure de la machine et une section servant à paramétrer la machine en tant que serveur pour d'autres machines. Regardons un exemple de fichier ntp.conf
##
## Exemple de fichier de configuration ntp '/etc/ntp.conf' pour un poste français
## (c) Marc Guillaume - yakati - 2003
##
## Horloge locale non synchronisée. Il s'agit d'une adresse fictive
## quand aucune autre n'est accessible notre serveur non synchronisé sur internet
## peut tout de même servir de serveur pour notre LAN
##
server 127.127.1.0 # horloge locale(LCL)
fudge 127.127.1.0 stratum 10 # LCL est désynchronisée nous lui donnons la strate 10
##
## il est recommandé dans la liste des serveurs de mettre au moins trois adresses, ce qui est
## en principe suffisant, mais il est préférable d'en avoir cinq.
## Pour le choix des serveurs il est préférable de choisir des serveurs fiables mais qui ne soient
## pas forcement très hauts dans la hiérarchie. Même si vous vous calez sur une strate 3 ou 4
## vous conserverez largement mieux que la seconde de précision. C'est bien assez pour un LAN et
## ainsi vous ne saturez pas les strates 2 dont certains peuvent avoir plus besoin que vous.
## A vous de juger du besoin de précision qui est le vôtre.
## En pratique vous ne pourrez pas vous connecter aux serveurs de strate 1 sans accréditation et
## mot de passe. Voici un choix de serveur qui devrait convenir à beaucoup de monde.
## Les serveurs peuvent être désignés par une adresse IP ou par un nom DNS. La plupart des
## serveurs vous encouragent à utiliser un nom DNS, certaines IP étant sujettes à changement.
## De plus il existe des serveurs de zones géographiques qui sont regroupés sur un même nom et
## DNS vous dirigent au hasard sur l'un de ces serveurs qui sont tous équivalents, de manière à
## les répartir la charge sur ces machines.
##
## maxpoll 12 indique que chaque 2^12=4192 secondes au maximum le démon consultera le serveur.
## La valeur ## ## par défaut est 10.
server ntp.cpsc.ucalgary.ca maxpoll 12
server fr.pool.ntp.org maxpoll 12
server pool.ntp.org maxpoll 12
server europ.pool.ntp.org maxpoll 12
server ntp.shorty.com maxpoll 12
server ntp.ndsoftwarenet.com maxpoll 12 # zone mondiale
server ntp1.tuxfamily.net maxpoll 12 # IP 80.67.177.2
server ntp2.tuxfamily.net maxpoll 12 # IP 80.67.179.2
server ntp.univ-lyon.fr maxpoll 12
server ntp.via.ecp.fr maxpoll 12
## La seconde partie du fichier fournit des informations permettant à la machine de devenir
##un serveur local
##
## Divers
##
## Le fichier /etc/ntp/drift sous Mandriva, qui dans d'autres distributions
## /var/lib/ntp/ntp.drift est celui qui contient la correction qu'il faut appliquer à notre
## horloge locale pour qu'elle soit le plus exacte possible.
## Le chiffre qu'il contient est exprimé en parties par million (ppm). Le maximum par défaut est
## de 500 ppm. Une correction de 12 ppm équivaut à une seconde par jour.
## Vous n'avez pas à intervenir sur ce fichier qui est entretenu par ntpd.
##
## On indique ici où il doit se trouver. Ce chemin est celui proposé par défaut sur Mdv.
##
driftfile /etc/ntp/drift
##
## On peut en principe faire écrire un log à ntpd en décommentant les lignes suivantes,
## mais pour ma part je n'ai jamais réussi à utiliser cette option.
##
## logfile /var/log/ntp # fichier de log # décommenter pour l'utiliser
## logconfig = syncstatus + sysevents
## logconfig =all # décommenter pour l'utiliser
## Il existe aussi la possibilité de faire générer des statistiques à ntpd mais je n'ai jamais
## non plus utilisé cette possibilité aussi n'en parlerai-je pas. En revanche si vous voulez
##ouvrir votre serveur sur internet ce sera indispensable.
## Local users may interrogate the ntp server more closely.
restrict 127.0.0.1 nomodify
#restrict 127.0.0.1 192.168.0.0 mask 255.255.0.0 nomodify
## Clients from this (example!) subnet have unlimited access,
## but only if cryptographically authenticated
#restrict 192.168.0.0 mask 255.255.0.0 notrust
## Il faut tous les paramètres suivants pour que ça marche, la ligne précédente est insuffisante
restrict 192.168.0.0 mask 255.255.0.0 kod nomodify notrap nopeer
## If you want to provide time to your local subnet, change the next line.
## (Again, the address is an example only.)
## L'activation de la ligne suivante coupe l'accès à mon serveur ntp de mon réseau 192.168.X.X
#broadcast 192.168.255.255
Le port par défaut sur lequel circulent les paquets ntp est UDP #123. Si nous voulons accéder à un serveur ou que des machines accèdent à notre serveur nous devons l'ouvrir. Pour les distributions en noyau 2.4.x qui utilisent iptables la règle iptables à appliquer est :
#iptables -I INPUT 1 -m udp -p udp -s 0/0 --sport 123 -d 0/0 --dport 123 -j ACCEPT
Pour ceux qui utilisent encore des noyaux 2.2.x (comme Mandriva 7.2 ou Single Network Firewall (SNF) par exemple) la règle ipchains est :
ipchains -I input -p udp -s 192.168.0.0/24 -d 192.168.0.1 123 -j ACCEPT -b
-s 192.168.0.0/24 est le réseau que l'on veut laisser entrer
-p 192.168.0.1 est la machine serveur elle-même
Suivant que vous serez sur une distribution en noyau 2.2 ou 2.4 le fichier de démarrage sera xntpd ou ntpd. on démarre le service (en root) par :
/etc/init.d/ntpd start ou /etc/init.d/xntpd start
Si l'on veut avoir le service au démarrage :
chkconfig --level 235 ntpd pour avoir le service démarré en init 2 3 et 5 par exemple
Quelques utilitaires sont livrés avec ntpd qui permettent de contrôler certains aspects de son fonctionnement.
Tout d'abord ntptrace qui donne le statut du serveur et du serveur sur lequel il se synchronise. Au démarrage il présente un aspect comme celui-ci (le serveur s'appelle avicenne dans le domaine "en bois" mg.lan) :
[marc]$ /usr/sbin/ntptrace
localhost: stratum 16, offset 0.000073, synch distance 0.00000
0.0.0.0: *Not Synchronized*
au bout de quelques minutes il présente un aspect comme celui-ci :
[marc]$ /usr/sbin/ntptrace
avicenne.mg.lan: stratum 3, offset -0.000842, synch distance 0.26396
hora.oxixares.com: stratum 2, offset 0.001512, synch distance 0.07550
ntp2-rz.rrze.uni-erlangen.de: stratum 1, offset -0.010752, synch distance 0.00021, refid 'GPS'
La signification est que avicenne est passé en serveur de strate 3 synchronisé sur le serveur de strate 2 hora.oxixares.com et que ce dernier est synchronisé sur le strate 1 ntp2-rz.rrze.uni-erlangen.de dont on voit qu'il se cale sur une horloge GPS.
Avicenne est prêt à servir de serveur de temps pour mon réseau LAN.
Un autre utilitaire est ntpq, il fournit des informations sur les serveurs sélectionnés comme peers par exemple :
[marc]$ /usr/sbin/ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
LOCAL(0) LOCAL(0) 10 l 13 64 377 0.000 0.000 10.010
*209.195.3.50 ntp-s1.cise.ufl 2 - 772 1024 377 393.690 -2.350 1.680
-ntp1-rz.rrze.un .DCFp. 1 u 446 512 377 110.762 -9.304 3.525
+fsa.cpsc.ucalga bonehed.lcs.mit 2 - 163 1024 377 283.780 0.122 0.640
le serveur précédé d'un astérisque (*) est celui qui est utilisé, celui précédé d'un + est un serveur dont le temps de réponse est actuellement trop long. Celui dont le nom est précédé d'un - est un candidat possible à la synchronisation.
On obtient également des informations sur chaque peer :
la colonne (remote) donne le nom du serveur (un des serveurs sélectionnés comme peers)
la colonne (refid) indique le serveur ntp qui sert de source au serveur
la colonne (st) indique la strate du serveur,
a colonne (t) indique si il est actif,
la colonne (when) dit depuis combien de temps il n'a pas été appelé en secondes,
a colonne (poll) indique la durée qui doit s'écouler entre chaque requête,
la colonne reach est le masque de requêtes réussies exprimé en octal,
la colonne (delay) exprime le temps, estimé en millisecondes, que met le paquet UDP à nous parvenir,
la colonne (offset) est la différence estimée entre l'heure de notre horloge interne et celle de référence,
la colonne (jitter) exprime la dispersion des valeurs de référence obtenues de ce peer, il exprime la qualité moyenne de cette source.
Pour estimer la qualité de votre connexion au serveur la colonne reach est à surveiller. A chaque contact réussi avec le serveur peer, ce nombre augmente. Comme il est exprimé en octal il va de 0 à 7 puis un second chiffre s’affiche. Lorsque la connexion est stable et de qualité on obtient 377. Pour que le serveur se considère comme synchronisé il faut qu’il ait au moins atteint 177. Ce n’est qu’à partir de là que des clients peuvent commencer à se synchroniser dessus.
Voir aussi : https://www.cyberciti.biz/faq/howto-set-date-time-from-linux-command-prompt/
Comme on s’en doute il faut installer ntpd sur notre machine et configurer ntp.conf. Ce dernier fichier est dans notre cas très simple :
##
## exemple de fichier de configuration '/etc/ntp.conf' pour un client LAN
##
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
## server local (si vous avez un DNS ou des fichiers hosts à jour vous pouvez utiliser son nom
## si ce n'est pas le cas vous utilisez son adresse IP.
server 192.168.0.1 # passerelle avicenne.mg.lan
## chemin du fichier de correction d'horloge
driftfile /etc/ntp/drift
## on indique que le serveur ne demande pas d'identification
authenticate no
Et c’est tout. Votre poste client va se synchroniser avec votre serveur de strate n et devenir un serveur potentiel de strate n+1
Au bout de quelques minutes, vous allez avoir par exemple :
[marc@maimonides marc]$ /usr/sbin/ntptrace
localhost.localdomain: stratum 4, offset 0.000011, synch distance 0.28328
avicenne.mg.lan: stratum 3, offset -0.000099, synch distance 0.27109
hora.oxixares.com: stratum 2, offset 0.001512, synch distance 0.07550
ntp2-rz.rrze.uni-erlangen.de: stratum 1, offset -0.010752, synch distance 0.00021, refid 'GPS'
et
[marc@maimonides marc]$ /usr/sbin/ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
LOCAL(0) LOCAL(0) 10 l 21 64 377 0.000 0.000 0.008
*avicenne.mg.lan 209.195.3.50 3 u 582 1024 377 0.923 -0.108 0.020
Il existe un client ntp pour windows en GPL du nom de NetTime qui permet de se synchroniser facilement sur un serveur de temps (local ou externe). On le trouve en téléchargement sur : http://www.nettime-server-client.net-software-download.com/
Il figure également sur la compilation de logiciels libres pour windows qui complète le serveur free-EOS : http://free-eos.org/
Pour les postes sous WindowsXP, il existe une synchronisation intégrée ntpd. Le serveur par défaut est un serveur microsoft, mais vous pouvez le remplacer par votre serveur local.
Pour les Mac dits "old world", il suffit d'utiliser la procédure suivante :
Tableau de Bord / Date et Heure
Cochez "Utiliser une horloge réseau"
Cliquez sur "Options d'horloge réseau"
Cliquez sur "Apple, Europe..."
et choisissez "Modifier la liste"
Cliquez sur "Ajouter"
Description = le nom de votre serveur (facultatif)
Adresse = l'adresse IP de votre serveur de temps
Cliquez sur "OK"
Supprimez tous les autres serveurs de temps
Cliquez sur "OK"
Cochez "Chaque 12 heures"
Cliquez sur "OK"
N'ayant pas de poste sous MacOSX je n'ai pas pu expérimenter. A priori la fonctionnalité a dû être conservée. Tout retour d'information est le bien venu.
Ce chapitre est très long car on peut revoir la configuration de beaucoup de serveurs précédemment décrit afin de les faire marcher avec LDAP. Malgré cela, il est incomplet et je ne compte pas le finir de si tôt car je ne vais ni enseigner LDAP, ni utiliser LDAP de si tôt sur un réseau.
Je laisse tout de même ce qui a déjà été fait car le début marche (authentification) mais si on n'utilise LDAP que pour ça, le jeu n'en vaut pas la chandelle! Vous êtes libre de me compléter ce chapitre comme le reste de ce cours. J'attends :-) .
LDAP (Lightweight Directory Access Protocol) est le protocole d'annuaire sur TCP/IP. Les annuaires permettent de partager des bases d'informations sur le réseau interne ou externe. Ces bases peuvent contenir toute sorte d'information que ce soit des coordonnées de personnes ou des données systèmes.
LDAP est un protocole d'annuaire standard et extensible. Il fournit :
le protocole permettant d'accéder à l'information contenue dans l'annuaire,
un modèle d'information définissant le type de données contenues dans l'annuaire,
un modèle de nommage définissant comment l'information est organisée et référencée,
un modèle fonctionnel qui définit comment on accède à l'information ,
un modèle de sécurité qui définit comment données et accès sont protégés,
un modèle de duplication qui définit comment la base est répartie entre serveurs,
des APIs pour développer des applications clientes,
LDIF, un format d'échange de données.
Les données LDAP sont structurées dans une arborescence hiérarchique, qu'on peut considérer comme un arbre. Si on prend un parallélisme avec un arbre chaque branche de l'arbre peut être considéré comme un objet de l'annuaire, et chaque feuille de l'arbre est une entrée dans l'annuaire ( une personne , une imprimante, une machine, une règle d'authentification etc.... )
On vérifie d'abord qu' Openldap n'est pas déjà installé sur votre système en tapant :
rpm -qa | grep -i ldap
Il faut rajouter les rpm de LDAP :
libldap2 openldap-server openldap-clients openldap nss_ldap openldap-migration pam_ldap : utilisés pour un serveur ldap comme un systeme NIS.
« urpmi php-ldap libltdl3 libunixODBC2 --auto-select »
Ce fichier est : /etc/openldap/slapd.conf. Voici un exemple commenté :
# inclusion des autres fichiers de configuration
# on utilise ce dont on a besoin ...
include /usr/share/openldap/schema/core.schema
include /usr/share/openldap/schema/cosine.schema
include /usr/share/openldap/schema/inetorgperson.schema
include /usr/share/openldap/schema/nis.schema
include /usr/share/openldap/schema/misc.schema
include /usr/share/openldap/schema/kerberosobject.schema
#include /usr/share/openldap/schema/rfc822-MailMember.schema
# Un include manquant introduira une erreur, il suffit alors de retrouver le fichier
# qui défini la classe manquante et de le rajouter (attention à l'ordre!).
# Pour les autres, gardez les commentaires afin de conserver l'ordre!
# Voir plus loin pour les choix
#include /etc/openldap/schema/local.schema
# Define global ACLs to disable default read access.
include /etc/openldap/slapd.access.conf
# on demande à ldap de vérifier si chaque ajout
# dans l'annuaire respecte bien la structure
schemacheck on
# fichiers qui stockent les arguments et les PID du serveur
pidfile /var/run/ldap/slapd.pid
argsfile /var/run/ldap/slapd.args
#######################################################################
# ldbm database definitions
#######################################################################
# Type de l'annuaire LDAP
database ldbm
#dans quelle "branche" de base on se situe
suffix "dc=troumad,c=org"
rootdn "cn=root,dc=troumad,c=org"
# rootpw secret
rootpw {MD5}je_ne_vais_pas_vous_le_donner!
# choisir le mode md5 pour le mot de passe : slappasswd -h {MD5}
#Ou sera stocke l'annuaire, dans une partition non effacée lors d'un update!
# Attention, ce répertoire devra appartenir à ldap : chown -R ldap:ldap /maison/ldap
directory /maison/ldap
# Indices to maintain
#index objectClass eq
index objectClass,uid,uidNumber,gidNumber eq
index cn,mail,surname,givenname eq,subinitial
password-hash {crypt}
password-crypt-salt-format "$1$%.8s"
# logging
loglevel 256
# Basic ACL
access to attr=userPassword
by self write
by anonymous auth
by dn="cn=root,dc=troumad,c=org" write
by * none
access to *
by dn="uid=root,ou=utilisateurs,dc=troumad,c=org" write
by * read
Après ceci, il faut lancer le démon : « /etc/init.d/ldap restart » ou en cas de problème, nous avons toujours la possibilité de faire : « nohup slapd -d 255 1>/dev/null 2>/dev/null & ».
Je fais un fichier dans lequel je rentre mes données : juste la racine de ma base de données. Ces données doivent comprendre le chemin des données à rentrer (la ligne dn). Comme c'est la racine, elle doit correspondre à la ligne suffix "dc=troumad,c=org" du fichier /etc/openldap/slapd.conf.
Voici une première manipulation commentée.
[root@troumad ldif]# cat racine.ldif
dn: dc=troumad, c=org
objectclass:top
objectclass:organization
o:troumad
description: Informatique Maison
[root@troumad ldif]# ldapadd -x -D "cn=root,dc=troumad,c=org" -W -f racine.ldif
Je rentre les données avec la commande « ldapadd ». Attention, il est important de dire que vous voulez avoir le compte qui est "cn=root,dc=troumad,c=org" avec l'option -D et de demander le mot de passe avec l'option -W. Il en est de même avec ldapdelete.
Enter LDAP Password:
adding new entry "dc=troumad, c=org"
[root@troumad ldif]# slapcat
Je regarde les données avec la commande slapcat.
dn: dc=troumad, c=org
objectClass: top
objectClass: organization
o: troumad
description: Informatique Maison
creatorsName: cn=root,dc=troumad,c=org
createTimestamp: 20031003070930Z
modifiersName: cn=root,dc=troumad,c=org
modifyTimestamp: 20031003070930Z
[root@troumad ldif]# ldapadd -x -f utilisateur.ldif -D "cn=root,dc=troumad,c=org" -W
Je rajoute une donnée dans ldap. Cette donnée doit être nouvelle, si c'est une modification, il faut utiliser ldapmodify. S'il y a une entrée existante, même les nouvelles entrées ne seront pas prises en compte.
Enter LDAP Password:
adding new entry "ou=utilisateurs,dc=troumad,c=org"
[root@troumad ldif]# ldapsearch -x -b "dc=troumad, c=org" 'ou=utilisateurs'
Je n'affiche dans mon arbre, que les données qui vérifient 'ou=utilisateurs'. On peut mettre * comme condition, dans ce cas, on a tout l'arbre.
version: 2
#
# filter: ou=utilisateurs
# requesting: ALL
#
# utilisateurs, troumad, org
dn: ou=utilisateurs,dc=troumad,c=org
objectClass: organizationalUnit
ou: utilisateurs
description: Les utilisateurs du reseau
# search result
search: 2
result: 0 Success
# numResponses: 2
# numEntries: 1
[root@troumad ldif]# cat utilisateur-modif
dn: ou=utilisateurs,dc=troumad,c=org
objectClass:organizationalUnit
ou:utilisateurs
description:Les utilisateurs du reseau LINUX
[root@troumad ldif]# ldapmodify -x -f utilisateur-modif -D "cn=root,dc=troumad,c=org" -W
Je modifie l'entrée utilisateur avec utilisateur-modif , c'est un fichier d'entrée normal au format ldif, puis je vérifie. On ne peut modifier qu'une entrée déjà existante. Si dans le fichier, il existe une entrée nouvelle, elle ne sera pas prise en compte. Avec la remarque faîte sur ldapadd, on en conclu que pour rajouter juste une nouvelle entrée, il faut lui fire un fichier à part.
Enter LDAP Password:
modifying entry "ou=utilisateurs,dc=troumad,c=org"
[root@troumad ldif]# ldapsearch -x -b "dc=troumad, c=org" 'ou=utilisateurs'
version: 2
#
# filter: ou=utilisateurs
# requesting: ALL
#
# utilisateurs, troumad, org
dn: ou=utilisateurs,dc=troumad,c=org
objectClass: organizationalUnit
ou: utilisateurs
description: Les utilisateurs du reseau LINUX
# search result
search: 2
result: 0 Success
# numResponses: 2
# numEntries: 1
[root@troumad ldif]# ldapdelete -x "ou=utilisateurs,dc=troumad,c=org" -W -D "cn=root,dc=troumad,c=org"
J'enlève l'entrée utilisateurs que je venais de modifier et je vérifie (commande suivante).
Enter LDAP Password:
[root@troumad ldif]#slapcat
dn: dc=troumad, c=org
objectClass: top
objectClass: organization
o: troumad
description: Informatique Maison
creatorsName: cn=root,dc=troumad,c=org
createTimestamp: 20031003070930Z
modifiersName: cn=root,dc=troumad,c=org
modifyTimestamp: 20031003070930Z
[root@troumad ldif]# rm-f *.gdbm
J'efface les données de ldap., C'est une manipulation à éviter sur un serveur péniblement configuré !!!!
[root@troumad ldif]# /etc/init.d/ldap restart
Je relance le démon afin d'être sur de ne pas récupérer des données d'un cache et de planter le serveur.
Arrêt du serveur LDAP : [ OK ]
ldaps
Lancement du serveur LDAP (ldap + ldaps) : [ OK ]
[root@troumad ldif]# slapcat
slapcat: could not open database.
La base de données est vide : j'ai bien repéré où étaient les données.
Les objets et leurs attributs sont normalisés par le RCC2256 (http://www.ietf.org/rfc/rfc2256.txt) de sorte à assurer l'interopérabilité entre les logiciels. Ils sont issus du schéma de X500, plus des ajouts du standard LDAP ou d'autres consortium industriels. Ils sont tous référencés par un object identifier (OID) unique dont la liste est tenue à jour par l'Internet Assigned Numbers Authority (IANA : http://www.iana.org/)
Les formes sont prédéfinies dans les « include » du début du fichier /etc/openldap/sldap.conf.
Vous avez différents moyens d'ajouter des données à l'annuaire, pour une meilleure compréhension on va d'abord aborder la méthode manuelle. Pour ajouter des données au serveur LDAP vous devez vous fournir un fichier au format LDIF (pour LDAP Directory Interchange Format), le format est un format texte facilement lisible au contraire du format interne de l'annuaire. Voici un exemple de fichier LDIF, à noter que:
- chaque enregistrement dans le fichier est séparé du précédent et du suivant par une ligne vierge,
- les espaces sont pris en compte. ATTENTION, il est très important qu'il n'y ait aucun espace en fin de ligne.
La syntaxe est la suivante:
dn: description du distinguished name
objetclass: classe d'objet d'origine
... Il faut obligatoirement indiquer la parenté de la classe d'objet
... en partant de l'objet top et en passant par chaque ancêtre de l'objet
objetclass: classe d'objet dérivée
type attribut: valeur
Voici un exemple de définition d'une personne :
dn: cn=Nom Prenom, ou=agenda, o=xenux, dc=net
objectclass: top
objectclass: person
objectclass: inetOrgPerson
mail: nom.prenom@xenux.net
displayName: Nom Prenom
givenName: Prenom
cn: Nom Prenom
sn: Prenom
mobileTelephoneNumber: 06 00 00 00 00
telephoneNumber: 00-00-00-00-00
homeTelephoneNumber: 11-11-11-11-11
homePostalAddress: XX Xenux Street
street: XX Xenux Street
pager: 22-22-22-22-22
postalCode: 99999
title: Job
preferredLanguage: fr
Explications :
-pour avoir une adresse email, il faut que l'objet soit de type inetOrgPerson
A partir de là, on peut chercher quels sont les fichiers de configurations dont on a besoin :
[root@monPC][/usr/share/openldap/schema]$ find . -type f -print |xargs grep inetOrgPerson
./inetorgperson.schema:# inetOrgPerson
./inetorgperson.schema:# The inetOrgPerson represents people who are associated with an
./inetorgperson.schema: NAME 'inetOrgPerson'
./openldap.schema: SUP ( pilotPerson $ inetOrgPerson )
Je vois que inetOrgPerson est défini dans ./inetorgperson.schema. Je dois donc inclure le fichier inetorgperson.schema dans mon fichier de configuration sldap.conf. Maintenant, je vais rechercher la définition dans inetOrgPerson. Je vais tapper les commande suivante : less inetorgperson.schema[Entrée]/[# inetOrgPerson[Entrée].
# inetOrgPerson
# The inetOrgPerson represents people who are associated with an
# organization in some way. It is a structural class and is derived
# from the organizationalPerson which is defined in X.521 [X521].
objectclass ( 2.16.840.1.113730.3.2.2
NAME 'inetOrgPerson'
DESC 'RFC2798: Internet Organizational Person'
SUP organizationalPerson
STRUCTURAL
MAY (
audio $ businessCategory $ carLicense $ departmentNumber $
displayName $ employeeNumber $ employeeType $ givenName $
homePhone $ homePostalAddress $ initials $ jpegPhoto $
labeledURI $ mail $ manager $ mobile $ o $ pager $
photo $ roomNumber $ secretary $ uid $ userCertificate $
x500uniqueIdentifier $ preferredLanguage $
userSMIMECertificate $ userPKCS12 )
)
donc inetOrgPerson dérive de l'objet organizationalPerson : SUP organizationalPerson
- Toujours avec la même méthode, nous cherchons ou est défini organizationalPerson :
./core.schema:objectclass ( 2.5.6.7 NAME 'organizationalPerson' SUP person STRUCTURAL
Il est donc défini dans core.schema et cette fois, comme c'est sur la même ligne, nous pouvons même dire que organizationalPerson dérive quant à lui de person
- person de top toujours dans core.schema : ./core.schema:objectclass ( 2.5.6.6 NAME 'person' SUP top STRUCTURAL
- ./core.schema:objectclass ( 2.5.6.0 NAME 'top' ABSTRACT : top est encore dans core.schema
Nous avons donc déjà besoin de deux includes : inetorgperson.schema et core.schema.
Avec tout ça que peut-on donner comme renseignements sur notre homme? On va encore regarder les includes.
Le fichiers core.schema ne nous apporte rien de particulier sur top : il dit qu'il doit contenir une classe.
Ce même fichier nous donne des informations sur 'person' :
objectclass ( 2.5.6.6 NAME 'person' SUP top STRUCTURAL
MUST ( sn $ cn )
MAY ( userPassword $ telephoneNumber $ seeAlso $ description ) )
On doit (MUST) donner les informations sn et cn. Nous pouvons aussi (MAY) compléter les champs userPassword, telephoneNumber, seeAlso, description. Bien que ce soit de l'anglais, je pense que c'est compréhensible !
Pour sn et cn, on trouve toujours dans ce même fichier :
attributetype ( 2.5.4.3 NAME ( 'cn' 'commonName' ) SUP name )
attributetype ( 2.5.4.4 NAME ( 'sn' 'surname' ) SUP name )
Le premier est le nom commun et le second le nom de famille.
Maintenant, pour organizationalPerson :
objectclass ( 2.5.6.7 NAME 'organizationalPerson' SUP person STRUCTURAL
MAY ( title $ x121Address $ registeredAddress $ destinationIndicator $
preferredDeliveryMethod $ telexNumber $ teletexTerminalIdentifier $
telephoneNumber $ internationaliSDNNumber $
facsimileTelephoneNumber $ street $ postOfficeBox $ postalCode $
postalAddress $ physicalDeliveryOfficeName $ ou $ st $ l ) )
On garde les informations de personn auxquelles on peut (MAY) rajoute : un titre (Mr, Mme, Mlle), et d'autres informations.
Pour inetOrgPerson, on voit qu'un peut rajouter plein d'information comme son adresse électronique et sa langue préférée.
Comme nous venons de le voir, on est vite débordé par les nouveaux termes. Alors voici un petit lexique!
L'ensemble des définitions relatives aux objets que sait gérer un serveur LDAP s'appelle le schéma. Le schéma décrit les classes d'objets, leurs types d'attributs et leur syntaxe. On trouve les définitions des objets dans les includes du fichier de configuration.
Une entrée de l'annuaire contient une suite de couples types d'attributs - valeurs d'attributs. Les attributs sont caractérisés par :
Un nom qui l'identifie
Un Object Identifier (OID) qui l'identifie également
S'il est mono ou multi-valué
Une syntaxe et des règles de comparaison
Un indicateur d'usage
Un format ou une limite de taille de valeur qui lui est associée
Les attributs décrivent généralement des caractéristiques de l'objet, ce sont des attributs dits normaux qui sont accessibles aux utilisateurs. Certains attributs sont dits opérationnels car ils ne servent qu'au serveur pour administrer les données (ex : attribut modifytimestamp).
La syntaxe indique le type de données associées à l'attribut et la manière dont l'annuaire doit comparer les valeurs lors d'une recherche.
Certains serveurs LDAP respectent les standards X500 de hiérarchisation des attributs, qui permettent de décrire un attribut comme étant un sous-type d'un attribut super-type et d'hériter ainsi de ses caractéristiques. Par exemple, les attributs cn, sn, givenname sont des sous-types de l'attribut super-type name. Ces attributs super-types peuvent être utilisés comme critère de recherche générique qui porte sur tous ses sous attributs.
Vous pouvez trouver une liste commentée sur : http://ldap.akbkhome.com/
Les classes d'objets modélisent des objets réels ou abstraits en les caractérisant par une liste d'attributs optionnels ou obligatoires. Une classe d'objet est définie par :
Un nom qui l'identifie
Un OID qui l'identifie également
Des attributs obligatoires
Des attributs optionnels
Un type (structurel, auxiliaire ou abstrait)
Le type d'une classe est lié à la nature des attributs qu'elle utilise.
Une classe structurelle correspond à la description d'objets basiques de l'annuaire : les personnes, les groupes, les unités organisationnelles... Une entrée appartient toujours au moins à une classe d'objet structurelle.
Une classe auxiliaire désigne des objets qui permettent de rajouter des informations complémentaires à des objets structurels. Par exemple l'objet mailRecipient rajoute les attributs concernant la messagerie électronique d'une personne. L'objet labeledURIObject fait de même concernant les infos Web.
Une classe abstraite désigne des objets basiques de LDAP comme les objets top ou alias.
Les classes d'objets forment une hiérarchie, au sommet de laquelle se trouve l'objet top. Chaque objet hérite des propriétés (attributs) de l'objet dont il est le fils. On peut donc enrichir un objet en créant un objet fils qui lui rajoute des attributs supplémentaires.
On précise la classe d'objet d'une entrée à l'aide de l'attribut objectClass.
Chaque entrée est référencée de manière unique dans le DIT par son distinguished name (DN). Le DN représente le nom de l'entrée sous la forme du chemin d'accès à celle-ci depuis le sommet de l'arbre. On peut comparer le DN au path d'un fichier Unix. Par exemple, mon DN est :
uid=mirtain,ou=people,dc=inria,dc=fr
Le DN représente le chemin absolu d'accès à l'entrée. Comme pour le système de fichier Unix, on peut utiliser un relative distinguished names (RDNs) pour désigner l'entrée depuis une position déterminée de l'arbre.
LDAP Data Interchange Format (LDIF) permet de représenter les données LDAP sous format texte standardisé, il est utilisé pour afficher ou modifier les données de la base. Il a vocation à donner une lisibilité des données pour le commun des mortels.
LDIF est utilisé dans deux optiques :
faire des imports/exports de base
faire des modifications sur des entrées.
La syntaxe est un nom d'attribut suivi de : suivi de la valeur (uid: mirtain), le premier attribut d'une entrée étant le DN (dn: uid=mirtain,ou=people,dc=inria,dc=fr). Le format utilisé est le BER ou UTF8, les données binaires étant codés en base 64. C'est pour cela que certaines valeurs doivent etre encodé en base64 dans ce cas l'attribut est suivi de "::" au lieu de ":"
La forme générale est :
dn: <distinguished name c'est la seule ligne avec des signe '='
objectClass: <object class Comme pour les suivantes, les affectations se font avec un ':'
objectClass: <object class
...
<attribute type:<attribute value
<attribute type:<attribute value
...
Changer le gestionnaire des groupes et des utilisateurs n'est pas une mince affaire car on doit refaire la base de données des utilisateurs et des groupes. Ceci n'est pas si facile qu'on pourrais le penser. Pour vous donner une idée, regardez le nombre de groupes présents dans /etc/group et le nombre d'utilisateurs dans /etc/passwd.
Pour cela, nous avons des utilitaires. Je vais utiliser ceux qui sont fournis avec Mandriva. Ils sont décrits sur http://www.Mandrivasecure.net/en/docs/ldap-auth2.php (cette page sera un résumé en français de ce lien). Mais il en existe d'autres comme ceux décrits (en français) sur la page : http://www.xenux.net/?article=22.
Tout d'abord, il faut être sur d'avoir installer les rpm désignés au début de ce chapitre sur ldap.
On commence tout d'abord à configurer correctement son /etc/openldap/slapd.conf comme indiqué juste après la liste des rpm. Surtut, n'oubliez pas de crypter votre mot de passe ldap avec slappasswd -h {MD5} et prenez en un différent du mot de passe utilisateur. Vous comprendrez pourquoi!
Après ceci, il faut redémarer ldap : service ldap restart. Pour voir si vous avez correctement défini vos paramètres, essayez : ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts et regardez la réponse. Si ceci vous semble correct, configurez ldap pour démarrer avec votre ordinateur : chkconfig ldap on.
Maintenant, nous allons utiliser les outils de migrations, des script en Perl, mis à notre disposition par Mandriva. Ils sont dans le répertoire /usr/share/openldap/migration. On va dans ce répertoire car les scripts font appel à d'autres scripts de ce répertoire qui n'est pas dans le PATHxii.
Si on veut tout migrer, on utilise le script migrate_all_online.sh. Cependant, vous aurez peut-être des lignes à commenter en plaçant un dièse (#) devant comme "Migrating protocols..." ou "Migrating services..." car vos sources seront absentes (non installées). On exécute migrate_all_online.sh :
[root@ldap]# ./migrate_all_online.sh
Enter the X.500 naming context you wish to import into: [dc=troumad,o=org]
Enter the name of your LDAP server [ldap]: localhost
Enter the manager DN: [cn=manager,dc=troumad,o=org]: cn=root,dc=troumad,o=org
Enter the credentials to bind with: secret à mettre en clair
Do you wish to generate a DUAConfigProfile [yes|no]? no
Pour mieux comprendre ce qui se fait, on peut exécuter les scripts un par un pour mieux comprendre. Personnellement, pour des raisons de clareté, je conseille de vous faire un répertoire personnel où vous allez stoquer les fichiers ldif générés par ces outils de migration. Leur structure est intéressante, elle vous permettra, par duplication, de créer de nouveaux comptes où de nouveaux groupes.
[root@ldap]# ./migrate_base.pl >/repertoire_stockage/base.ldif
[root@ldap]# ldapadd -x -D "cn=root,dc=troumad,o=org" -W -f /repertoire_stockage/base.ldif
On peut visualiser alors le fichier : cat /repertoire_stockage_perso/base.ldif. On voit la structure de notre base ldap. Cette lecture peut être instructive. Ensuite, on passe aux données elles-mêmes.
[root@ldap]# ./migrate_hosts.pl /etc/hosts /repertoire_stockage/hosts.ldif
[root@ldap]# ldapadd -x -D "cn=root,dc=troumad,o=org" -W -f /repertoire_stockage/hosts.ldif
[root@ldap]# ldapsearch -LL -H ldap://localhost -b "dc=troumad,o=org " -x "(cn=wrkstation)"
Comme ceci, vous importez ordinateurs définis dans hosts dans la base et vous visualisez que l'importation a été correcte. Ensuite, vous exporterez les groupes et les comptes utilisateurs.
[root@ldap]# ./migrate_group.pl /repertoire_stockage/group group.ldif
[root@ldap]# ldapadd -x -D "cn=cn=root,dc=troumad,o=org" -W -f /repertoire_stockage/group.ldif
[root@ldap]# ETC_SHADOW=/etc/shadow ./migrate_passwd.pl /etc/passwd /repertoire_stockage/passwd.ldif
[root@ldap]# ldapadd -x -D "cn=root,dc=troumad,o=org" -W -f /repertoire_stockage/passwd.ldif
On peut compléter à la main le fichier passwd.ldif pour rajouter des informations : celles que j'ai mis en italique. Celle qui est souligée, je l'ai modifiée. En revanche, pour modifier un mot de passe manuellement dans ce fichier, on trouve la version cryptée en faisant : « slappasswd -c crypt » ou « slappasswd -h {crypt} ».
dn: uid=troumad,ou=People,dc=troumad,c=org
uid: troumad
cn: Bernard
sn: SIAUD
title:Monsieur
mail: troumad@libertysurf.fr
mailRoutingAddress: troumad@lycee.org
mailHost: lycee.org
objectClass: mailRecipient
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: account
objectClass: posixAccount
objectClass: top
objectClass: kerberosSecurityObject
objectClass: shadowAccount
userPassword: {crypt}Je_ne_le_donne_pas!
shadowLastChange: 12321
shadowMax: 99999
shadowWarning: 7
krbname: troumad@lycee.org
loginShell: /bin/bash
uidNumber: 501
gidNumber: 501
homeDirectory: /home/bernard
telephoneNumber: xx xx xx xx xx
street: ma rue
postalCode:69XXX
postalAddress:Vers Lyon
Pour vérifier les informations, vous pouvez visualiser un utilisateur en faisant par exemple :
[root@ldap]# ldapsearch -b "dc=troumad,o=org " -x "(uid=troumad)"
Je conseille sur cet exemple de créer un nouvel utilisateur que vous allez rentrer dans ldap : il vous permettra de voir si ldap est bien pris en compte.
C'est fini pour le serveur. Nous pouvons maintenant le tester en apprenant à manipuler les utilisateurs.
Installer chez le client : nss_ldap.
Attention, une erreur dans cette configuration et vous ne pouvez plus vous logger sur votre machine! Une méthode pour tout de même vous rendre la main consiste à arrêter le serveur ldap. Donc, éviter de mettre une authentification ldap sur le serveur même car vous ne pourrez même plus prendre la main pour réparer le plantage!
Il faut définir dans le fichier /etc/hosts le serveur ldap :
192.168.1.1 troumad # c'est lui mon serveur ldap
127.0.0.1 localhost
192.168.1.10 s_travail
Ensuite, on doit configurer le serveur ldap en modifiant le fichier /etc/ldap.conf qui devra avoir les lignes suivantes non commentées (laissez les autres, elles pourront toujours vous informer par la suite).
host 192.168.1.1 # adresse du serveur
base dc=troumad,o=org # votre serveur ldap
rootbinddn cn=root,dc=troumad,o=org # dn du responsable de la base
scope one
pam_filter objectclass=posixaccount
pam_login_attribute uid
pam_member_attribute gid
pam_password md5 # important, initialement, c'est script et ça fait planter!
nss_base_passwd ou=People,dc=troumad,o=org?one
nss_base_shadow ou=People,dc=troumad,o=org ?one
nss_base_group ou=Group,dc=troumad,o=org?one
nss_base_hosts ou=Hosts,dc=troumad,o=org?one
Le clou, c'est le fichier /etc/ldap.secret qui doit juste contenir en clair le mot de passe ! Mettez lui les droits 600, mais bon, c'est pour cela que je vous avais dit d'avoir un mot de passe ldap différent du mot de passe root! Pour le créer il suffit de faire « echo mot_de_passe_secret >ldap.secret ». Sans ce fichier l'authentification ldap est impossible!
On va aussi configurer NSS pour qu'il utilise ldap. Ceci se fait en configurant le fichier /etc/nsswitch.conf :de la façon suivante (si besoin, on enlève les références à nisplus et nis mise pour le serveur NIS):
passwd: files ldap
shadow: files ldap
group: files ldap
hosts: files ldap dns
On peut vérifier si tout est bien pris en compte en examinant les sorties de :
[root@ldap]# getent hosts
[root@ldap]# getent group
[root@ldap]# getent passwd
[root@ldap]# getent shadow
Si ldap est bien pris en compte, vous devez voir que le fichier hosts donne des doublons. Je vous conseille alors de le réduire au minimum vital : localhost et le serveur ldap car il faudra bien trouver ce serveur!
Après il faut aussi paramétrer PAMxiii pour qu'il utilise Ldap. On rajoute les 4 lignes en gras, celles qui contiennent ldap dans le fichier /etc/pam.d/system-auth.
#%PAM-1.0
auth required /lib/security/pam_env.so
auth sufficient /lib/security/pam_unix.so likeauth nullok
auth sufficient /lib/security/pam_ldap.so use_first_pass
auth required /lib/security/pam_deny.so
account required /lib/security/pam_unix.so
account sufficient /lib/security/pam_ldap.so
password required /lib/security/pam_cracklib.so retry=3 minlen=2 dcredit=0 ucredit=0
password sufficient /lib/security/pam_unix.so nullok use_authtok md5 shadow
password sufficient /lib/security/pam_ldap.so use_authtok
password required /lib/security/pam_deny.so
session required /lib/security/pam_limits.so
session required /lib/security/pam_unix.so
session optional /lib/security/pam_ldap.so
/etc/pam.d/passwd ajouter les 4 lignes en gras :
#%PAM-1.0
auth sufficient /lib/security/pam_ldap.so
auth required pam_stack.so service=system-auth
account sufficient /lib/security/pam_ldap.so
account required pam_stack.so service=system-auth
password required /lib/security/pam_cracklib.so retry=3 minlen=4 dcredit=0 ucredit=0
password sufficient /lib/security/pam_ldap.so use_authtok
password required pam_stack.so service=system-auth
http://www.Mandrivasecure.net/en/docs/samba-pdc.php. http://samba.idealx.org/
Comme nous devons avoir en main le minimum vital d'instruction en ligne de commande, nous pouvons maintenant utiliser un GUI pour visualiser les données : GQ. Pour l'installer « urpmi gq ». S'il ne trouve pas gq, c'est que nous n'avons pas installé la source de rpm contrib ce que nous pouvons faire facilement grâce à la page : http://plf.zarb.org/~nanardon/.
Il est possible avec l'intermédiaire de ldap d'avoir la même base de mot de passe aussi bien pour Samba que pour les autres partages. Ceci demande de reconfigurer samba selon les explications qui suivent.
Il faut installer les rpm samba compilés pour ldap. On peut directement les récupérer sur un serveur de samba comme : http://us3.samba.org/samba/ftp/Binary_Packages/Mandriva/RPMS/9.1/. On les installe « urpmi samba-common-ldap-2.2.8a-2mdk.i586.rpm » et « urpmi samba-server-ldap-2.2.8a-2mdk.i586.rpm ».
Après, on rajoute dans smb.conf les lignes suivantes :
ldap admin dn = cn=root,dc=troumad,c=org
ldap server = 192.168.1.1
ldap suffix = dc=troumad,c=org
ldap port = 389
ldap ssl = start tl
sadd user script = /usr/share/samba/scripts/smbldap-useradd.pl -w -d /dev/null -g machines \
-c 'Machine Account' -s /bin/false %u
domain admin group = root Administrator @adm @Administrators @wheel
On rentre le mot de passe administrateur ldap sous Samba : « smbpasswd -w mot_de_passe_en_clair ». Cette manipulation ne peut marcher que si vous avez installé les rpm
Ensuite on modifie un script /usr/share/samba/scripts/import_smbpasswd.pl :
$DN="ou=people,dc=mylan,dc=net";
$ROOTDN="cn=root,dc=mylan,dc=net";
# If you use perl special character in your
# rootpw, escape them:
# $rootpw = "secr\@t" instead of $rootpw = "secr@t"
$rootpw = "n0pass";
$LDAPSERVER="scooby";
Après, nous devons faire une modification à notre base de données d'OpenLDAP. Nous aurons besoin d'une nouvelle unité d'organisation additionnelle (ou). Jusqu'ici nous gardons nos utilisateurs sous l'ou de Peoples mais nous avons besoin d'un endroit pour nos comptes d'ordinateur : windows gére les ordinateurs comme des personnes. Nous appellerons ceci les ou=Computers d'endroit, dc=troumad, c=org comme montré ci-dessous. Créez un dossier des textes avec le contenu suivant appelé ComputersOU.ldif :
dn: ou=Computers,dc=troumad,c=org
ou: Computers
objectClass: top
objectClass: organizationalUnit
objectClass: domainRelatedObject
associatedDomain: Maison
installez pam_ldap et modifiez le fichier /etc/ldap.conf. comme dans l'installation du client pour l'authentification avec une différence :
nss_base_passwd dc=mylan,dc=net?sub
nss_base_shadow ou=People,dc=mylan,dc=net?one
nss_base_group ou=Group,dc=mylan,dc=net?one
nss_base_hosts ou=Hosts,dc=mylan,dc=net?one
[root@ldap samba]# smbldap-groupshow adm
[root@ldap samba]# smbldap-usershow Administrator
Puis dans /etc/openldap/slap.con
include /usr/share/doc/samba-doc-2.2.3a/examples/LDAP/samba.schema
Nous allons rajouter, tester et enlever l'utilisateur test1 :
[root@troumad][~]$ smbldap-useradd -m test1
[root@troumad][/~]$ smbldap-passwd -m test1
Changing password for test1
New password :
Retype new password :
all authentication tokens updated successfully
[root@troumad][~]$exit
Pour tester aussi le mot de passe.
[troumad@troumad][~]$ su - test1
Password:
su: AVERTISSEMENT: ne peut changer de répertoire vers /home/test1: No such file or directory
-bash-2.05b$ exit
logout
[troumad@troumad][~]$su -
[root@troumad][~]$ smbldap-userdel test1
[root@troumad][~]$ su test1
su: L'usager test1 n'existe pas.
Remarques : Ne pas mettre de lettres accentuées sauf si cat dcorral.ldif | recode ISO-8859-15..UTF-8 > dcorral_utf8.ldif
Sur LDAP :
http://www-sop.inria.fr/semir/personnel/Laurent.Mirtain/ldap-livre.html
Cette documentation vous expliquera le fonctionnement interne de LDAP.
http://www.xenux.net/?article=28
L'objectif de cette documentation est d'inclure complètement la gestion du DHCP dans notre Annuaire LDAP
http://annuaire.univ-aix.fr/ldap.doc/
http://www.int-evry.fr/mci/user/procacci/ldap/
http://www.toolinux.com/linutile/reseau/intranet/partie4/index3
http://www.linux-france.org/article/serveur/ldap/ldap.html#toc4
http://listes.cru.fr/wws/arc/ldap-fr/2001-10/msg00024.html
http://www.rycks.com/documentations/ldap/
Ceci est un script que j'ai récupéré sur la liste Mandriva débutant. Il prend en compte plusieurs distributions :
nfo 0.15 -- gather info from various Linux systems
# 6/2003 Christian Perle
#
# set PATH to include /sbin and friends
export PATH=/bin:/usr/bin:/sbin:/usr/sbin:/usr/local/bin:/usr/local/sbin
# english please
export LANG="en_EN"
# we use internal dirname
dirname()
{
echo ${1%/*}
}
echo "gathering system info..."
# which distro are we running?
[ -f /etc/debian_version ] && DISTRO=debian
[ -f /etc/SuSE-release ] && DISTRO=suse
[ -f /etc/redhat-release ] && DISTRO=redhat
[ -f /etc/Mandriva-release ] && DISTRO=Mandriva
# use redhat as default
[ -z $DISTRO ] && DISTRO=redhat
rm -f linf.tgz
mkdir linf
(
cd linf
conflist=" \
/etc/modules /etc/modules.conf /etc/conf.modules /etc/services \
/etc/lilo.conf /etc/fstab /etc/inittab /etc/inetd.conf /etc/hosts \
/var/log/XF*.log /etc/XF86* /etc/X11/XF86* /etc/resolv.conf \
/proc/interrupts /proc/ioports /proc/dma /proc/cmdline \
/proc/devices /proc/partitions /proc/version /proc/cpuinfo "
# include debian specific files
if [ $DISTRO = debian ] ; then
conflist="$conflist /etc/debian_version /etc/network/interfaces "
fi
# include redhat specific files
if [ $DISTRO = redhat -o $DISTRO = Mandriva ] ; then
conflist="$conflist /etc/redhat-release /etc/Mandriva-release \
/etc/sysconfig/network /etc/sysconfig/network-scripts/ifcfg-eth? "
fi
# include suse specific files
if [ $DISTRO = suse ] ; then
conflist="$conflist /etc/SuSE-release /etc/rc.config /etc/route.conf "
fi
# copy files
for file in $conflist
do
if [ -r $file ] ; then
DESTDIR=`dirname $file`
DESTDIR=${DESTDIR#?}
mkdir -p $DESTDIR
cp $file $DESTDIR
fi
done
lsmod > loaded.modules 2> /dev/null
# use /proc/modules as fallback
[ $? != 0 ] && cat /proc/modules > loaded.modules
lspci -v > pci.devices 2> /dev/null
lspci -n >> pci.devices 2> /dev/null
# use /proc/pci as fallback
[ $? != 0 ] && cat /proc/pci > pci.devices
dmesg > dmesg
df > df
cat /proc/mounts > mounted.filesystems
hostname > hostname
ifconfig > ifconfig
route -n > route
uptime > uptime
# /proc/config.gz is more reliable than /usr/src/linux/.config
if [ -r /proc/config.gz ] ; then
gzip -cd /proc/config.gz > kernel.config.proc 2> /dev/null
else
[ -r /usr/src/linux/.config ] && cp /usr/src/linux/.config kernel.config.usrsrc
fi
# distro dependent package managers
if [ $DISTRO = debian ] ; then
COLUMNS=400 dpkg -l | tr -s " " > package.list 2> /dev/null
else
rpm -qa > package.list 2> /dev/null
fi
# visit the /usr/local zoo
ls /usr/local/bin > usrlocal.list
# extract default runlevel from inittab
if [ -r /etc/inittab ] ; then
DEFLV=`grep "^id:" /etc/inittab`
DEFLV=${DEFLV#*:}
DEFLV=${DEFLV%%:*}
fi
# use current runlevel as fallback
if [ -z $DEFLV ] ; then
DEFLV=`runlevel`
DEFLV=${DEFLV#? }
fi
# distro dependent rc directories
case $DISTRO in
suse) RCD=/etc/init.d ;;
redhat|Mandriva) RCD=/etc/rc.d ;;
debian) RCD=/etc ;;
*) ;;
esac
ls $RCD/rc$DEFLV.d > running.services 2> /dev/null
pstree > process.tree 2> /dev/null
ps auxww > running.processes
netstat --inet -nap > connections 2> /dev/null
)
tar czf linf.tgz linf
rm -rf linf
echo "result saved in linf.tgz"
echo "done."
Général : http://lea-linux.org/kernel/kernel.html
Ubuntu : http://doc.ubuntu-fr.org/doc/custom_kernel?s=compilation
Mandriva : http://doc.Mandrivalinux.com/MandrivaLinux/92/fr/Command-Line.html/compiling-kernel-chapter.html ou http://www.Mandrivaclub.com/docs/10.0/fr/Command-Line.html/ch13s02.html
Cette manipulation est sans danger car on conserve les noyaux précédents (en boot automatique) et qu'il faut une manipulation volontaire pour utiliser le nouveau noyau.
Les lignes suivantes indiquent la méthode à suivre pour faire votre propre noyau :
- Installer les sources du noyau : « urpmi kernel-source » avec Mandriva ou « sudo apt-get install linux-source-2.X.X » avec ubuntu (trouvé avec « apt-cache search source 2.6 » )
- Installer aussi pour Mandrivale compilateur c++ : « urpmi gc++ libqt3-devel » et pour debian qt3 : « apt-get install qt3-apps-dev » et ubuntu : « sudo apt-get install build-essential fakeroot kernel-package », sous ubuntu, il faut décompresser les sources : « tar jxvf linux-source-2.XX.XX.tar.bz2 » (l'utilisateur appartenir au groupe src).
- Aller dans le répertoire où sont les sources : cd /usr/src/linux sur Mandriva ou sur « cd /usr/src/linux-source-2.6.16 » en fonction sur noyau installé et/ou choisi (il peut en avoir plusieurs disponibles ) sur debian.
- Modifier l'entête du fichier « Makefile » afin de repérer votre version : l'item EXTRAVERSION servira à repérer votre version. On repérera la version du noyau qui tourne grâce à « uname -r ».
- Lancer l'interface graphique (c'est long, ne pas s'inquiéter) : « make xconfig ». (Ou « make menuconfig » si vous n'avez pas d'interface graphique, sur une console). Notre premier test consistera à choisir votre processeur : entré « Processor type and feature ». Le reste, on n'y touchera pas, déjà certains disent que cette manipulation accélère le système.
- Afin de conserver votre nouvelle configuration, sauvegarder le fichier .config dans un endroit personnel.
- Lancer la compilation : make dep (fait automatiquement avec le noyau 2.6)
make clean bzImage modules
make modules_install install
-Installation du nouveau noyau (fait automatiquement avec le noyau 2.6).
$ cp arch/i386/boot/bzImage /boot/vmlinuz-2.6.3-toto
$ cp System.map /boot/System.map-2.6.3-toto
- Mise à jour de grub ou de LILO (ne pas oublier d'exécuter lilo) en rajoutant les lignes suivantes (fait automatiquement avec le noyau 2.6) :
image=/boot/vmlinuz-2.6.3-toto
label=test
root=/dev/hda1
read-only
Rebooter votre PC en choisissant le nouveau noyau avec lilo (ou grub)... Si vous avez choisi le bon processeur, ça devrait marcher !
Explication de ces étapes :
make xconfig : modifier le fichier « .config », ceci consiste surtout à mettre ou enlever des # en début de ligne (commenter une ligne).
make clean : supprimer tous les fichiers temporaires de compilation
make bzImage : construit l'image de kernel compressé par bzip, créé le kernel non compressé "exécutable" vmlinux dans la racine du répertoire des sources puis il va compresser ce vmlinux en vmlinuz qu'il va placer dans arch/i386/boot/bzImage pour une architecture x86. le bzImage, c'est vmlinuz mais avec un nom différent
make modules : construit tous les modules demandés
make modules_install : installe tous les modules dans /lib/modules/kernel.version/
make install : installe l'image du kernel, les modules si c'est pas déjà fait, le System.map et met à jour le bootloader
Avec la nouvelle version du noyau (2.6), lorsqu'on fait un nouveau « make xconfig », on récupère la dernière version du noyau mémorisée dans le fichier .config. Il est d'autant plus important de conserver la dernière version valide de ce fichier afin de pouvoir reprendre une configuration qui marche : il se fait automatiquement une archive dans /boot/config-<version>. Cette sauvegarde est d'autant plus intéressante que lors d'une mise à jour des sources, le répertoire avec vos sources « périmées » peut être effacé.
En dehors de cette sauvegarde, la démarche est la même. Pensez cependant à nettoyer de temps à autre le répertoire /boot de vos noyaux intermédiaires ainsi que le fichier /etc/lilo.conf ou /boot/grub/menu.lst qui devient vite trop grand !
Note concernant les noyaux de Mdk : tant qu'à compiler son noyau, autant enlever le maximum de modules (inutiles dans la plupart des cas pour son matériel spécifique) et d'options (si on a pas de wifi, pas la peine de le compiler). Cela permet de diminuer considérablement le temps de compilation du noyau et des modules.
Enfin, changer la variable 'EXTRAVERSION' dans le fichier Makefile afin de créer un noyau avec un nom bien distinct de celui de Mdk. Cela permet de faire cohabiter les noyaux de manière beaucoup plus transparente.
Attention : si vous utilisez plusieurs cartes réseau sur votre PC et que vous incluez les drivers dans le noyau, il ne vous sera alors plus possible de définir leur ordre avec les alias.
Il est bien beau de faire le ménage dans le noyau (ceci se voit au moins au temps de compilation). Mais chaque test laisse ses restes ! Il faut donc les enlever !
Pour cela, il faut nettoyer, les entrées du répertoire /boot/, les entrées de lilo ou grub. Et aussi /lib/modules. Pour cela, il est agréable d'avoir une structure logique et simple pour différentier les essais,
[root@localhost][/lib/modules]# ll
total 48
drwxr-xr-x 2 root root 4096 fév 8 12:23 2.6.12-13mdk/
drwxr-xr-x 3 root root 4096 fév 8 11:33 2.6.14-0.mm.7mdk/
drwxr-xr-x 3 root root 4096 fév 8 11:33 2.6.14-0.mm.7mdk-i915-1/
drwxr-xr-x 3 root root 4096 fév 8 14:08 2.6.14i915-1/
drwxr-xr-x 3 root root 4096 fév 8 16:41 2.6.14-i915-2/
drwxr-xr-x 3 root root 4096 fév 8 17:47 2.6.14-i915-3/
drwxr-xr-x 3 root root 4096 fév 8 18:49 2.6.14-i915-4/
drwxr-xr-x 3 root root 4096 fév 9 11:15 2.6.14-i915-5/
drwxr-xr-x 3 root root 4096 fév 9 18:54 2.6.14-i915-6/
drwxr-xr-x 3 root root 4096 fév 11 10:19 2.6.14-i915-7/
drwxr-xr-x 3 root root 4096 fév 11 15:58 2.6.14-i915-8/
[root@localhost][/lib/modules]# ls -1 | grep i915- | grep -v i915-8 | xargs rm -fr
[root@localhost][/lib/modules]# ll
total 16
drwxr-xr-x 2 root root 4096 fév 8 12:23 2.6.12-13mdk/
drwxr-xr-x 3 root root 4096 fév 8 11:33 2.6.14-0.mm.7mdk/
drwxr-xr-x 3 root root 4096 fév 11 15:58 2.6.14-i915-8/
[root@localhost][/lib/modules]# cd /boot
[root@localhost][/boot]# ls -1 | grep i915- | grep -v i915-8 | xargs rm
Notez et cherchez à comprendre ma commande : « ls -1 | grep i915- | grep -v i915-8 | xargs rm -fr ».
Cette partie va vous permettre de sécuriser votre machine Linux, déjà contre des attaques lorsque vous vous connectez sur Internet (surtout si vous faites de l'IRC, les attaques sont fréquentes), si votre machine sert de serveur WEB, etc...
Pour la
sécurité
1- mot de passe root le plus compliqué possible
2-
mettre un mot de passe au BIOS du PC.
3- utiliser le compte root
au strict minimum
4- configurer bien ton firewall
5-
désactiver tous les services dont on n'a pas besoin
6- mettre
à jour les packages et le noyau
7- il faut lire les fichiers
log
8- configurer pour un boot uniquement sur disque dur
9-
mettre un mot de passe au BIOS
10- protéger l'accès physique
au serveur (les 2 derniers points sont facilement détournables avec
un tourne vis et on peut toujours prendre le disque dur -ou PC
entier- pour le travailler tranquillement chez soi). Mettre des vis
spéciales sur le boitier (des petites secondes de plus peuvent
décourager un agresseur éventuel)...
Tout d'abord la sécurité passe par des mots de passes utilisateurs. Il est impensable de laisser un compte utilisateur sans mot de passe. Pour une sécurité accrue je vous conseille fortement de :
- Mettre des mots de passes de 8 caractères minimum.
- Mélanger des caractères minuscules, majuscules et numériques (ex: imDe56T4z).
- Ne pas mettre des mots contenus dans un dictionnaire (style nom propre ou nom commun).
On peut tester la validité des mots de passe avec john (urpmi john) en faisant :
john --user=aline /etc/shadow
Comme je l'ai déjà dit, Mandriva 9.1 empêchait l'utilisation facile de WM sous root. Ceci est tout à fait légitime.
Ce compte est réservé à l'administration de votre machine, ainsi vous devriez toujours être connecté en tant que simple utilisateur. C'est généralement la première grosse erreur sous windows : tout programme peut être exécuté avec les droits complets, ne faîtes pas de même sous Linux.
Si vous devez faire des manipulations avec les droits administrateurs, faîtes les soit sur un des 6 premiers terminaux, soit en faisant un su sur un shell déjà ouvert dans un WM, soit en exécutant un GUI qui vous demandera le mot de passe du super utilisateur (comme Mandriva contrôle Center) ou avec la commande « sudo ».
Il faut enlever l'option « failsafe » bien utile pour les tests, mais géniale pour prendre en main le PC lors du boot ! Pour cela, il faut éditer le fichier /etc/lilo.conf et enlever l'entrée dont le label est « failsafe ». Ensuite on exécute lilo.
On peut commencer par mettre le lilo actuel sur une disquette :
$ fdformat -u /dev/fd0 : formater une disquette
$ lilo -b /dev/fd0 : mettre lilo sur la disquette
Ceci afin de pouvoir booter sur la disquette avec « failsafe » pour réparer d'éventuels problèmes. Là, les points 7 et suivants de la configuration prennent toute leur importance.
Remarque 1 : $ lilo -u : pour enlever lilo du disque dur.
Remarque 2 : Voir aussi Grub.
Un noyau permet de faire bien plus de choses que nécessaire (surtout celui de la Mandriva). On peut donc modifier ses options et ne prendre que les options nécessaires. En effet, le noyau, comme tout autre élément peut contenir des failles, moins on prend d'option dans le noyau, moins il est susceptible d'en avoir (de connues).
Les trous de sécurité sont également dus à des versions de démons (SSH, FTP, WWW, etc ...) qui ne sont pas mis à jour depuis longtemps ou à temps. Si vous avez un minimum de méthode et que vous pensez sécuriser votre machine comme un serveur, vous faîtes sans doute partie de ces personnes qui visitent les sites de sécurité sur des bases régulières. C'est une bonne étape pour voir rapidement si votre distribution favorite est vulnérable.
La seconde option est d'aller sur le site de la distribution que vous possédez et vérifier qu'aucune mise à jour de sécurité n'est disponible depuis votre installation ou dernière mise à jour. Ainsi, dans la liste des applications les plus mises à jour, on notera : Apache, OpenSSH & OpenSSL et les démons FTP. Voici donc une liste de sites de sécurité que je vous conseille de visiter régulièrement : http://www.linuxsecurity.com/ , http://www.securiteam.com/ , http://www.sans.org , http://www.securite.org , http://www.securityfocus.com/
Après avoir mis à jour, il convient de ne laisser ouvert que ce que vous utilisez. Ainsi, si vous faîtes une installation complète de Mandriva, SuSE ou Redhat, vous pouvez vous retrouver avec les démons SSH, Apache, Apache SSL, CVS et encore d'autres choses qui ne vous sont pas vraiment nécessaires. Assurez vous de désactiver tous les services que vous n'utilisez pas et vérifier bien les configurations des autres. Utilisez également SSH (et par conséquent scp, qui vous permet de faire des copies de fichiers sur des machines distantes) et oubliez FTP. FTP transmet vos mots de passe en clair sur le réseau, il pourrait être récupéré rapidement par quelqu'un. Dans le cas de SSH, il est crypté. Si vous voulez un maximum de sécurité, vous pouvez également échanger la clé publique entre vos machines, cela vous permettra de vous connecter sans échanger de mot de passe.
Pour Mandriva, RedHat ou autre distribution qui utilisent les rpm, je conseille de faire exécuter toutes les nuits une mise à jour automatique en mettant dans le répertoire /etc/cron.daily le fichier suivant :
#!/bin/sh
urpmi.update -a;urpmi --auto-select --auto
rpm -qa --qf '%{name}-%{version}-%{release}.%{arch}.rpm\n' 2>&1 | sort > /var/log/rpmpkgs
Si vous avez un serveur de mail, vous avez un retour quotidien sur cette mis à jour.
Un fire wall permet de filtrer les entrées sur votre ordinateur. Il peut permettre certaines opérations sur le réseau privé et les empêcher sur le réseau internet mondial. Comme ça, il y aura moins de démons ouverts sur l'extérieur, donc moins de failles possibles.
Pour la configuration du fire-wall, voir un chapitre précédent.
La meilleure façon de voir les ports sur ouverts est de taper une des commandes :
netstat -vtlnp
iptables -vL
nmap -sS IP
Un nmap sur l'adresse de loopback (nmap -sS 127.0.0.1) ne montrera que les ports ouverts sur l'interface lo 127.0.0.1.. ceci représente donc peu d'intérêt... Un nmap sur sa propre adresse donnera une information sur ce qui tourne localement. Un nmap sur un autre PC donnera des informations sur les ports ouverts de cet autre ordinateur, même s’il n’y a pas de services en face. En revanche un nmap ne parcourt pas tous les ports, pour imposer des ports, il faut l’option -p : <port ranges>: ne scanne que les ports spécifiés
Ex: -p22; -p1-65535; -p U:53,111,137,T:21-25,80,139,8080
nmap -sS netjuke -p1-65535
pour scanner tous les ports.
Après vous être donné du mal pour sécuriser un minimum votre machine, il serait intéressant de constater ce que cela donne. Vous pouvez donc pour ce faire utiliser des logiciels pour scanner votre machine et vous indiquer ce qu'il reste à sécuriser. Je vous conseille les logiciels suivants, dans la catégorie testeurs :
http://www.insecure.org - Le site Officiel de NMAP qui possède de nombreuses fonctions avancées pour scanner votre machine.
http://www.nessus.org - Le site Officiel de Nessus qui bien que fastidieux à installer se révèle très bon pour vous sensibiliser sur les problèmes de sécurité courants.
Si vous n'êtes pas satisfait du résultat, il vous reste encore quelques options pour rendre votre machine plus sécurisée. Ces programmes vous permettent de fermer les portes de votre machine et de sécuriser également un serveur de ses utilisateurs locaux. Voici donc une petite liste :
http://www.bastille-linux.org - A utiliser avec précautions, Bastille sécurise votre machine complètement (et peut même vous empêcher de vous relogger de nouveau ;).
http://www.snort.org - Snort est un sniffer qui scrute votre interface réseau (carte éthernet ou bien modem) pour détecter les machines qui tentent d'obtenir des informations sur les services activés et le type de machine que vous possédez.
http://www.prelude-ids.org/ - Prélude vous permet également de contrôler les intervenants du réseau sur votre machine.
http://www.netfilter.org - Netfilter est un projet mettant à votre disponibilité iptables qui vous servira à construire un firewall sous kernel 2.4.
Les informations se trouvent en majorités dans le répertoire /var/log. On peut modifier la configuration en modifiant le fichier /etc/syslog.conf. Parfois, les informations n'arrivent plus dans les fichiers, essayez de relancer le démon syslog.
Il est possible de rajouter sous un noyau 2.4 la ligne suivante à /etc/syslog.conf :
*.* /dev/tty12
Sous un noyau 2.6 (ou plutôt un système sans /dev/tty12 mais /dev/vc/12) la ligne suivante à /etc/syslog.conf :
*.* /dev/vc/12
Ceci nous permet de faire afficher en temps réel les log sur tty12 accessible par un Ctrl-ALT-F12. Sur un serveur, il peut être intéressant de laisser afficher ces informations en permanence afin d’avoir juste à jeter un coup d’œil en passant pour être informé de son état. On activera cet affichage en relançant le démon sysklogd (sous debian) ou syslog (sous Mandriva) : « /etc/init.d/sysklogd restart ».
Logiciels prévus pour : logsentry, swatch par exemple.
http://www.ac-creteil.fr/reseaux/systemes/linux/outils-tcp-ip/Linux-syslog.html
tail -f /var/log/messages
Utiliser snot : http://frlinux.net/index.php?section=reseau&article=53
fwlogwatch
http://frlinux.net/index.php?section=reseau&article=30
http://jipe.homelinux.org/trucs_en_vrac/antivirus.html
Pour identifier un intrus, « whois ip_de_l'intrus », whois n'est pas installé par défaut : « urpmi whois »
http://olivieraj.free.fr/fr/linux/information/firewall/fw-03-09.html
Les règles netfilter/iptables ont tendances à faire exploser rapidement les fichiers de log. Il existe donc un démon spécialisé pour elles : ulog. Ce démon permet d'envoyer les log d'Iptables dans des fichiers spéciaux. Ces log sont très importants car c'est en les étudiant qu'on peut remarquer si on a été attaqué ou scanné tout simplement.
Installation sur mandriva : « urpmi ulogd » et sous debian « apt-get install ulogd »
http://www.fail2ban.org/wiki/index.php/FAQ_french
http://j2c-s2c.com/informatique/linux/fail2ban.php
Il lit les fichiers de log et bannit les adresses IP qui ont obtenu un trop grand nombre d'échecs lors de l'authentification. Il met à jour les règles du pare-feu pour rejeter cette adresse IP.
Il est disponible dans les sources des distributions « urpmi fail2ban » pour l’installer sous Mandriva. Les fichiers de configuration sont sur /etc/fail2ban/.
Si syslog n’est pas installé, alors les logs sont uniquement dans le journal, et on peut accéder avec la commande journalctl (l'option «-b» permet de n’avoir que les logs depuis le dernier démarrage, et «-u unit» seulement les logs d'un service en particulier). Comme par exemple :
journalctl -u dhcpd
Si on veut les avoir également dans des fichiers textes « à l’ancienne », il faut installer une implémentation de syslog (typiquement rsyslog, ou syslog-ng) et ce sera enregistré aux deux endroits.
http://linuxfocus.org/Francais/March2004/article326.shtml
La sauvegarde est le dernier rempart de défense contre les pannes matérielles, des brèches de sécurité et le danger ultime : les utilisateurs. Je vais essayer de faire la sauvegarde avec un moyen simple et peu onéreux : la commande « rsync » pour plus de renseignement voir http://rsync.samba.org.
rsync -uRavlpg --progress --delete /home/bv --exclude "Desktop/Corbeille" /amoi/svg
Ou plus sofistiqué :
Pour faire une sauvegarde, on demande à rsync de créer un répertoire appelé 'AA-JJ-MM' qui servira à stocker les modifications incrémentales. Ensuite rsync examine les changements intervenus sur les serveurs à sauvegarder. Si un fichier a changé, il copie la version ancienne dans le répertoire incrémental puis copie la version actualisée du fichier dans le répertoire principal de sauvegarde. La base de ce script vient du site Web de rsync. Il n'y a en réalité qu'une seule commande :
rsync --force --ignore-errors --delete --delete-excluded --exclude-from=exclude_file --backup --backup-dir=`date +%Y-%m-%d` -av
Les options clés sont :
--backup : crée des sauvegardes des fichiers avant de les écraser en les écrivant sur eux-mêmes
--backup-dir=`date +%Y-%m-%d` : crée un répertoire de backup pour ces sauvegardes, qui ressemble à ça pour la sauvegarde du 15 août 2003: 2003-08-15
-av : mode archive et mode verbeux.
Le script qui suit peut être lancé chaque nuit en utilisant le système cron
En général, les modifications quotidiennes ne représentent qu'un petit pourcentage du système de fichiers total : le pourcentage moyen ne dépasse pas 0,5% à 1%. Par conséquent vous pouvez, avec un jeu de disques de sauvegarde d'une capacité double de celle des disques à sauvegarder, conserver 50 à 100 jours de sauvegardes incrémentales sur disque dur.
Lorsqu'un disque est plein, on peut :
- faire un ménage
- trouver de la place ailleurs
changer le disque de sauvegarde et mettre l'ancien à l'abri : en dehors de tout PC
Ceci est une version plus simple qui permet seulement d'avoir la configuration de veille. Je commence à « pinger » une machine pour voir si elle est connectée. Ensuite, je monte (ou essaie de monter inutilement) le répertoire qui me sert sur le dit PC afin de faire les transferts. Comme seuls les affichages sont reportés dans les mails systèmes, je les réduits au strict minimum : information de machines non connectées.
#!/bin/sh
if ! ping -c 1 192.168.1.1 > /dev/null 2>&1
then
echo 'machine non pinguable 1'
else
mount /maison_1 2>/dev/null
cd /maison_1
rsync -Cvaub /maison/marie-claire .
cd /sauvegarde
rsync -Cvaub /maison_1/bernard/sites .
fi
if ! ping -c 1 192.168.1.20 > /dev/null 2>&1
then
echo 'machine non pinguable 20'
else
mount /home 2>/dev/null
cd /sauvegarde
rsync -Cvaub /home/bernard .
fi
J'ai créé un script du nom de rsync.cron dans /etc/cron.weekly, puis je l'ai
rendu exécutable par la commande : chmod 755 rsync.cron
Voici le début de ce rsync.cron:
#!/bin/bash
rsync -uRavlpg --delete /home/joel --exclude "Desktop/Corbeille" /mnt/win_c2/
(j'ai fait sur ce modèle une ligne pour chaque partition que je désire sauvegarder)
Ceci a pour effet de sauvegarde une fois par semaine (parce que je l'ai mis dans /etc/cron.weekly) ma partition /home/joel, à l'exclusion du contenu de la Corbeille (option --exclude), sur mon disque /mnt/win_c2/, tout en supprimant de la sauvegarde les fichers de /home/joel qui ont été effacés depuis la dernière fois (option --delete)
Options de rsync (voir man rsync):
r recursif
u mise à jour, n'écrase pas les fichiers plus récents
R noms de chemins relatifs
a mode archivage
v verbose
l copie les liens symboliques
p preserve les permissions
g preserve le groupe
--progress pour suivre la progression de la sauvegarde sur une console
Cela peut effrayer, mais je ne suis pas calé du tout, et pourtant j'y suis arrivé à la seule lecture de man rsync.
De plus, j'ai amélioré mon script : il crée maintenant des liens durs, ce qui permet, lors des sauvegardes successives, de ne pas faire de sauvegarde des fichiers qui n'ont pas été modifiés depuis la précédente sauvegarde, mais de créer des liens pointant sur celle-ci. Ce qui a pour résultat de prendre moins de place sur le DD.
Je ne sais pas si mes explications sont claires. Je mets le début du script, ce sera plus compréhensible :
#!/bin/bash
# se déplacer dans le répertoire des sauvegardes
cd /sauvegarde
#1- on supprime tous ce qu'il y a dans backup.3 (En fait tant qu'il
#reste un lien sur le contenu du fichier, rien n'est supprimé) ;
rm -rf backup.3
#2- On décale tout ;
mv backup.2 backup.3
mv backup.1 backup.2
mv backup.0 backup.1
rsync -a --delete --link-dest=../backup.1 source_directory/
#3- on fait un rsync de "source_directory" vers "backup.0" en faisant des
#liens durs vers "backup.1" pour les fichiers inchangés.
# mise a jour de la sauvegarde d'aujourd'hui
rsync -urRav --progress --delete --link-dest=../backup.1 /documents --exclude
"recycled" --exclude ".Trash-joel" --exclude "irate" --exclude "streamtuner"
--exclude ".Trash-501" --exclude "download" /sauvegarde/backup.0/
grsecurity sous linux offre un niveau de sécurité au moins équivalent à ce qu'on a sous freebsd.
http://www.grsecurity.net/papers.php
http://dmrproject.free.fr/linux.htm
Tu possèdes, sans avoir à installer la suite kaspersky, de nombreux moyens de vérifier l'intégrité de ton système :
tripwire , pour examiner l'intégrité de tes fichiers
*rkhunter pour détecter les rootkit
urpmi rkhunter
rkhunter -c
**nessus* pour vérifier que les programmes sont à jour. (c 'est réellement un outil encore plus complet)
urpmi nessus
/etc/init.d/nessusd
*nikto* est un programme permettant de détecter des failles dans des services lancés.
urpmi nikto
*clamav pour vérifier d'éventuels fichiers infectés (concernant surtout windows)
logcheck pour vérifier en crontab les logs principaux de ta machine
Grub 1 n’est pas utile pour un serveur, mais peut être utile pour tester des serveurs différents sur un PC de test. Il est en effet plus souple et plus facilement modifiable que lilo. En effet, pour modifier grub, il suffit de modifier un fichier. Grub 1 prend automatiquement en compte la modification du noyau même si le nom est le même. Dans les deux cas, avec lilo, il faut lancer « lilo » en ligne de commande afin de prendre en compte ses modifications. De ce fait, grub peut être très intéressant pour faire des disquettes (ou clef USB) de démarrage.
Même si on a complètement raté son menu.lst au point de ne plus pouvoir démarrer son système, grub offre une ligne de commande genre "mini-bash" avec complétion automatique. On peut éditer chaque ligne du menu ou même appeler grub et à partir du prompt tout générer. Ça évite de booter sur une distribution live, de lancer lilo dans un chroot, ...
Sous Mandriva, on commence par installer le rpm : « urpmi grub »
Vu d'un
système linux, une clé usb n'est pas un floppy mais un disque
dur. Il ne faut donc pas employer la procédure de génération d'un
floppy.
Il faut brancher ta clé et la monter.
Ensuite,
lancer grub sous root :
[root@tangerine-64] ~ # grub
GNU GRUB version 0.95 (640K lower / 3072K upper memory)
[ Minimal BASH-like line editing is supported.
For the first word, TAB
lists possible
command completions. Anywhere else TAB lists the possible
completions of a device/filename. ]
grub>
taper alors :
root (<tab> (l'espace et
la parenthèse après le root sont importants)
Il va te donner
la liste des disques disponibles sur le système avec sa
notation propre:
grub> root (hd
Possible disks
are: hd0 hd1 hd2
Chez moi hd0 est hd1 sont des
disques SATA (/dev/sda et /dev/sdb)
hd2 est ma clé : /dev/sdd
On sait maintenant que le disque s'appelle hd2, il faudra
répercuter ça dans le fichier menu.lst (hd2,0) pour la
première partition, etc.
compéter la commande par:
root (hd2,0)
passer alors la commande:
setup (hd2)
Il faut que l'arborescence grub se trouve sur la clé en
question:
device.map menu.lst
reiserfs_stage1_5 stage2
e2fs_stage1_5
xfs_stage1_5 jfs_stage1_5
minix_stage1_5
stage1
soit dans /grub, soit dans /boot/grub
Il
va alors dire (toujours avec hd2 dans mon cas) :
Checking
if "/boot/grub/stage1" exists... no
Checking if
"/grub/stage1" exists... yes
Checking if
"/grub/stage2" exists... yes
Running "install
/grub/stage1 d (hd2) /grub/stage2 p /grub/menu.lst"...
succeeded
Done.
grub>
taper quit
pour vider les buffer et sortir.
Je pense que la
commande grub-install /dev/sdd (toujours dans mon cas doit
faire le même effet)
Il vous faudra sur votre clé
un fichier menu.lst, le fichier mini est :
title
Linux
root (hd2,1)
kernel
/vmlinuz root=/dev/sdd1 ro
Jeter un oeil à-dessus
aussi :
http://d-i.alioth.debian.org/manual/fr.i386/ch04s04.html
Booter sur la clé demande ensuite à aller dans le
BIOS. En effet, comme il s'agit d'un "disque dur" il
ne le connait que lorsqu'il est branché.
Une fois grub installé sur le xiv de système qui va booter, il suffit de modifier juste le fichier /boot/grub/menu.lst pour modifier sa configuration. Voici un fichier d'exemple qui permet 4 système sur un seul PC (debian, Mandriva10.0, Mandriva 10.1 et windows) :
# menu.lstd /usr/share/doc/grub-doc/.
default 0
timeout 5
# Pretty colours
color cyan/blue white/blue
title Debian GNU/Linux, kernel 2.6.8-1-k7
root (hd0,5)
kernel /boot/vmlinuz-2.6.8-1-k7 root=/dev/hda6 ro
initrd /boot/initrd.img-2.6.8-1-k7
savedefault
boot
title Debian GNU/Linux, kernel 2.6.8-1-k7 (recovery mode)
root (hd0,5)
kernel /boot/vmlinuz-2.6.8-1-k7 root=/dev/hda6 ro single
initrd /boot/initrd.img-2.6.8-1-k7
savedefault
boot
title Debian GNU/Linux
root (hd0,5)
kernel /boot/vmlinuz_deb.img root=/dev/hda6 ro
initrd /boot/initrd_deb.img
savedefault
boot
title Mandriva 10.0
root (hd0,8)
kernel /boot/vmlinuz_10.0 root=/dev/hda9 ro
initrd /boot/initrd_10.0.img
savedefault
boot
title Mandriva 10.1
root (hd0,7)
kernel /boot/vmlinuz_10.1 root=/dev/hda8 ro
initrd /boot/initrd_10.1.img
savedefault
boot
### meme s'il n'y en a pas sur mon PC###
title Microsoft Windows
root (hd0,0)
savedefault
makeactive
chainloader +1
http://lebricabrac.wordpress.com/2009/10/20/linux-securiser-grub/
Il est très simple avec grub d'avoir un accès root à la machine sans mot de passe. Il suffit sous grub d'entrer dans le mode édition lors du boot. Ceci se fait simplement en tapant la touche « e » (comme edit) du clavier. Après, on rajoute à la fin de la ligne débutant par kernel la commande suivante (avec un espace devant) :
1
Une fois cette modification faite, on valide en tapant sur « Entrée » puis on boote en pressant la touche “b”. Et là miracle, au bout de quelques secondes on arrive sur un shell bash tout beau sans qu’aucune identification ne soit requise. À partir de là on peut imaginer effectuer tout un tas d’action comme modifier le mot de passe d’un utilisateur à l’aide de la commande passwd. Notez d’ailleurs que cette technique est parfaitement utilisable quand vous avez oublié votre mot de passe root par exemple.
Pour mettre un mot de passe à grub il va tout débord falloir générer un hash md5 du mot de passe que vous désirez utiliser, pour cela il faut passer par l’utilitaire grub-md5-crypt :
[nassim@Laptop_Nassim
~]$ grub-md5-crypt
Password:
Retype
password:
$1$XF1ZG/$Hry.mmJjvlJ1DeH4/4EG9.
La chaine de caractère en vert est votre mot de passe en crypté, vous devez le copier. Il ne reste plus qu’à éditer le fichier menu.lst de Grub et y insérer la ligne suivante au niveau des configurations générales (en début de fichier et non à la fin du fichier) :
password --md5 1$XF1ZG/$Hry.mmJjvlJ1DeH4/4EG9.
Ceci oblige de taper le mot de passe pour entrer dans le mode édition.
Pour interdire l'accès à une entrée du menu sans mot de passe il faut rajouter comme ceci la ligne « lock » après le titre :
title linux recup
lock
kernel (hd0,4)/boot/vmlinuz BOOT_IMAGE=linux root=LABEL=mandriva splash=silent resume=UUID=111ec26b-8722-406f-bb6c-0d380c6aad82 vga=788 init=/bin/bash
initrd (hd0,4)/boot/initrd.img
Si les utilisateurs vont disposer de quotas identiques, tu peux définir des modèles de quotas en te basant sur certains utilisateurs, puis appliquer ces modèles sur les autres.
Par exemple au boulot j'ai créé les utilisateurs qthese pour les quotas des thésards et qstage pour les quotas des stagiaires. Ensuite, via les commandes "edquota qthese" puis "edquota qstage", j'ai défini les quotas pour ces modèles ; enfin, pour chaque utilisateur réel, j'ai fait (c'est l'option -p qui est importante, cf. la page de manuel):
edquota -pqthese <utilisateur-en-these>
edquota -pqstage <utilisateur-en-stage>
C'est setquota que l'on peut aisement scripter. Voila ce que ça donne pour infos des fois que ca puisse resservir :) .Pour ma part j'ai un annuaire ldap mais ca doit etre transposable je pense.
------------
#!/bin/bash
#Couleurs
COLTITRE="\033[1;35m"
# Rose
COLPARTIE="\033[1;34m" #
Bleu
COLTXT="\033[0;37m" # Gris
COLCHOIX="\033[1;33m" # Jaune
COLDEFAUT="\033[0;33m" # Brun-jaune
COLSAISIE="\033[1;32m" # Vert
COLCMD="\033[1;37m" # Blanc
COLERREUR="\033[1;31m" # Rouge
COLINFO="\033[0;36m" # Cyan
ERREUR()
{
echo -e
"$COLERREUR"
echo "ERREUR!"
echo -e "$1"
echo
-e "$COLTXT"
exit 1
}
if [ $# -ne 4 ]; then
echo -e "$0
a besoin d'arguments pour fonctionner"
echo
"Passer en arguments dans l'ordre :"
echo
"- le nom du groupe dont vous voulez fixer le quota"
echo "- le quota soft a fixer"
echo "- le quota hard a fixer"
echo "- la partition sur laquelle
on aplique le quota"
echo ""
echo "ex : ./quota.sh Profs 200000
200000 /home"
echo "fixera un
quota de 200Mo sur home pour chaque prof"
exit
1
fi
TST_PARAM_OK=$(ldapsearch -xLLL cn="$1"
| grep memberUid)
if [ -z "$TST_PARAM_OK" ]; then
ERREUR "Impossible de trouver le groupe passé en
paramètre dans l'annuaire Ldap"
fi
ldapsearch
-x -LLL cn=$1 | grep memberUid | cut -d " " -f2 | while
read A
do
echo "je fixe le
quota pour" $A
setquota -F xfs $A
$2 $3 0 0 $4
done
exit 0
Je viens de constater que mon système (une Sarge mise à jour aujourd'hui, avec un noyau 2.6.8, dans sa configuration presque par défaut), est vulnérable à l'attaque d'une forkbomb, même lancée par un utilisateur sans privilèges. Après quelques secondes d'exécution du code suivant, il m'est impossible de lancer un nouveau processus, même en root, et donc en particulier de tuer la forkbomb :
> int main()
> {
> while(1)
> fork();
> return 0;
> }
Le soin de se protéger des forkbombs est-il laissé à l'administrateur, ou bien devrais-je remplir un rapport de bug ? Si c'est le cas, quel est le paquet concerné ? Ce bug est-il suffisament grave pour recevoir le tag security ?
C'est à l'administrateur de gérer ça en fixant un nombre maxi de processus par utilisateurs. Cela se fait, si ma mémoire est bonne par la commande ulimit (qui semble être une commande interne de certains shells [bash et zsh notamment]), ou en éditant le fichier /etc/security/limits.conf .à installer hostapd qui fera de ton ordinateur un vrai point d’accès
http://www.lea-linux.org/cached/index/Cr%C3%A9er_un_point_d'acc%C3%A8s_s%C3%A9curis%C3%A9_avec_hostAPd.html
urpmi hostapd ou apt-get install hostapd
Ensuite, on va aller configurer hostAPd, le fichier /etc/hostapd/hostapd.conf . Le plus dur est de lire tous les commentaires en fait :) Mais pour aller un peu plus vite, voici les lignes qui servent dans MON cas (simple WPA-PSK) :
#La carte Wifi, forcément indispensable :) interface=ath0 #Si la carte est bridgée et utilise madwifi, il faut préciser le nom du bridge bridge=bridge_local # Le driver nécessité par la carte driver=madwifi #Options de log par défaut, elles sont très bien :) logger_syslog=-1 logger_syslog_level=1 logger_stdout=-1 logger_stdout_level=2 debug=2 dump_file=/tmp/hostapd.dump #Contrôle du programme, encore une fois, le réglage par défaut est nickel :) ctrl_interface=/var/run/hostapd ctrl_interface_group=0 #Le nom de votre réseau. C'est important. Choisissez un nom à peu près reconnaissable et pas trop long. ssid=MADOUIFI #Comment gérer les adresses MAC (adresse Hardware des cartes réseaux) # C'est une sécurité qui peut facilement être contournée, mais est # néanmoins pratique, car elle est facile à mettre en place # En effet, hostAPd va vérifier l'adresse MAC de la carte Wifi qui fait une # demande d'accès et pourra alors, sur cette seule adresse, soit continuer le # processus d'identification, soit s'arrêter et refuser la carte. # Les paramètres possibles sont les suivants : # 0 : Tout accepter à moins qu'elle ne soit dans la liste noire # 1 : Tout refuser, à moins qu'elle ne soit dans la liste blanche # 2 : Vérifier l'adresse auprès d'un serveur RADIUS (honnêtement, pour son réseau local, ça ne sert à rien) # Le meilleur paramètre pour commencer est 1. Ça réduit de beaucoup les risques de piratage. macaddr_acl=1 #Chemin des fichiers pour les listes noire et blanche # Je vous conseille de les créer tout de suite, on verra plus tard pour les remplir correctement accept_mac_file=/etc/hostapd/hostapd.accept deny_mac_file=/etc/hostapd/hostapd.deny # La description anglaise pour les curieux :) auth_algs=1 #Celui là, je sais pas trop... Je crois qu'on peut l'enlever, mais bon je suis pas sûr, j'ai pas testé :) eap_server=0 #Dis qu'on veut faire du WPA-PSK wpa=1 # Votre clé, le coeur de la sécurité du WPA-PSK :) wpa_passphrase=SupèRecléDelAmor,Avecdetrucch3l0us;) # Pour un petit peu plus de sécurité, vous pouvez attribuer une clé WPA par adresse MAC (donc par ordinateur). #C'est quand même un peu plus embêtant à maintenir... #wpa_psk_file=/etc/hostapd/wpa_psk # On définit ce qu'on veut comme WPA wpa_key_mgmt=WPA-PSK # Et l'algo de cryptage wpa_pairwise=TKIP # Quelques options temporelles. Pas forcément nécessaire pour que ça marche :) wpa_group_rekey=600 wpa_gmk_rekey=86400
Et la touche finale. Éditez le fichier /etc/default/hostapd et décommentez la ligne suivante :
RUN_DAEMON=yes
et configurez la ligne :
DAEMON_CONF="/etc/hostapd/hostapd.conf"
Et voilà. C’est fini. Enfin, non, ce n’est pas tout à fait exact. La configuration du serveur est finie. Il reste à la tester et à configurer des clients :) En avant toute !
« urpmi --auto-update » suffit pour télécharger la liste des paquets à jour et à l’installer. On peut rajouter l’option « --auto » pour éviter les questions et l’option « --keep » pour ne rien enlever. La dernière option n’est pas recommandée, mais elle permet par exemple de ne pas passer à la dernière version de firefox tant que la traduction française n’est pas disponible.
On peut automatiser cette mise à jour avec le script suivant qu’on ferra exécuter par cron à l’heure voulue :
date '+%d/%m/%Y à %H %M' >> /root/maj
urpmi --auto-update --auto --keep >> /root/maj
if [[ `grep restart /root/maj | grep -v restarting | wc -l` != 0 ]]; then { mv -f /root/maj ; grep restart /root/maj > /root/maj.reboot ; reboot ; } ; fiOn génère un nouveau fichier /root/maj.anc et /root/maj.reboot si lors de lamise à jour on a un message qui indique de redémarrer l’ordinateur. Il est important aussi de vérifier régulièrement dans /root/maj si l’option –keep n’a pas posée de problèmes.
https://forum.ubuntu-fr.org/viewtopic.php?id=1026731
Il faut installer cron-apt : « aptitude install cron-apt » et mettre dans le fichier /etc/cron-apt/config :
APTCOMMAND=/usr/bin/aptitudeOPTIONS="-o quiet=1 -o Dir::Etc::SourceList=/etc/apt/sources.list"RUNSLEEP=10TEMP="/tmp/cron-apt_templog"
Ensuite on met dans le fichier /etc/cron-apt/action.d/3-download :
full-upgrade -y -o APT::Get::Show-Upgraded=trueautoclean -yclean
Pour info, la première ligne fait une mise à jour totale et les deux dernières font le ménage après.
Finalement, on vérifie que le fichier /etc/cron.d/cron-apt est bien configuré pour un lancement à 4 heure du matin tous les jours :
# # Regular cron jobs for the cron-apt package # # Every night at 4 o'clock. 0 4 * * * root test -x /usr/sbin/cron-apt && /usr/sbin/cron-apt # Every hour. # 0 * * * * root test -x /usr/sbin/cron-apt && /usr/sbin/cron-apt /etc/cron-apt/config2 # Every five minutes. # */5 * * * * root test -x /usr/sbin/cron-apt && /usr/sbin/cron-apt /etc/cron-apt/config2
Les
log seront dans /var/log/cron-apt/log
et /var/log/aptitude.
Un article plus complet se trouve sur : http://linux.developpez.com/cours/upsusb
Pour installer le gestionnaire à distance puis le serveur pour les onduleurs :
urpmi nut
urpmi nut-server
L’onduleur est défini dans /etc/ups/ups.conf (sous debian, ubuntu, j’ai l’impression que le répertoire est /etc/nut)
[MGE_UPS_with_PnP_INTERFACE]
#nom donné à l’onduleur
port = /dev/ttyS0
# port où est branché l’onduleur
driver = mge-shut
# driver de l’onduleur
Dans le même répertoire le fichier upsd.users contient les utilisateurs :
[troumad]
password = troumad
allowfrom = localhost lan
upsmon master
La surveillance est gérée par le fichier : upsmon.conf
RUN_AS_USER ups # nom de l’utilisateur de UPS
MONITOR MGE_UPS_with_PnP_INTERFACE@192.168.2.1 1 troumad troumad master # identification de l’UPS
MINSUPPLIES 1 # valeur par défaut acceptable
SHUTDOWNCMD "/sbin/shutdown -h +0" # commande d'arrêt de l’ordinateur
NOTIFYCMD /usr/sbin/upssched # envoie de messages
POLLFREQ 5 # appel de upsd toutes les 5 secondes
POLLFREQALERT 5 # appel de upsd toutes les 5 secondes quand l’onduleur est sur batteries
HOSTSYNC 15 # temps en s d’attente avant de déconnecter les esclaves
DEADTIME 15 # 15 secondes sans réponses de l’onduleur => il est mort
POWERDOWNFLAG /etc/killpower # fichier drapeau pour indiquer que l’onduleur est en mode extinction
# envoyer un commentaire + exécutable
NOTIFYFLAG ONLINE SYSLOG+EXEC # si l’UPS est de retour sur le secteur
NOTIFYFLAG ONBATT SYSLOG+EXEC # si il est sur batterie
NOTIFYFLAG REPLBATT SYSLOG+EXE # si les batteries sont à remplacer
RBWARNTIME 43200 # temps entre deux alertes de batteries en mauvais état
NOCOMMWARNTIME 300 # temps entre deux alertes de non communication avec un onduleur
FINALDELAY 5 # temps entre le signal d’arret ( NOTIFY_SHUTDOWN ) et l’arrêt effectif du serveur
Le fichier upsd.conf, quant à lui configure le démon. Ici, je laisse accès à l’ordinateur et au réseau local :
ACL all 0.0.0.0/0
ACL localhost 127.0.0.1/32
ACL lan 192.168.0.0/16
ACCEPT localhost lan
#ACCEPT 192.168.0.0/16
REJECT all
ACCESS grant monitor localhost
ACCESS grant monitor lan
ACCESS deny all all
Pour lancer le démon :
/etc/init.d/upsd restart
(Il me semble que c’est /etc/init.d/nut pour debian/ubuntu).
Pour tester que le service marche, on peut faire la commande suivante :
upsc MGE_UPS_with_PnP_INTERFACE@localhost
Un petit code de mon cru qui teste l’état de l’onduleur et envoie des messages suivant 2 états différents :
a=`upsc MGE_UPS_with_PnP_INTERFACE@192.168.2.1 | grep battery.charge: | cut -c17-`
if ( test $a -eq 100) then
drapeau=0
elif ( test $a -lt 75) then
drapeau=1
echo éteindre satellites
else
drapeau=2
echo éteindre satellites
fi
while ( test 1 -eq 1 )
do
a=`upsc MGE_UPS_with_PnP_INTERFACE@192.168.2.1 | grep battery.charge: | cut -c17-`
echo $drapeau $a
case $drapeau in
0)
if ( test $a -eq 100) then
echo rien ne change
elif ( test $a -lt 75) then
drapeau=1
echo éteindre satellites
else
drapeau=2
echo "Chute brutale de l'onduleur ! Attention !"
echo éteindre satellites
fi
;;
1)
if ( test $a -eq 100) then
drapeau=0
echo "remonté du serveur"
elif ( test $a -lt 75) then
echo rien ne change
elif ( test $a -le 25) then
drapeau=2
echo "Chute brutale de l'onduleur ! Attention !"
echo éteindre satellites
fi
;;
2)
if ( test $a -eq 100) then
drapeau=0
echo "Attention : remonté trop brutale du serveur"
elif ( test $a -lt 75) then
echo "remonté du serveur"
drapeau=1
echo rien ne change
elif ( test $a -le 25) then
echo éteindre serveur
fi
;;
esac
sleep 60
done
Il peut être intéressant de savoir comment est utilisé la mémoire de son ordinateur : regarder le fichier /proc/meminfo .
Voir : http://www.sygus.net/dotclear/index.php?post/2008/04/25/La-memoire-sous-Linux-proc-meminfo
Le changement de port, ça sert juste à bloquer des pauvres vers, ça sert en rien à la sécurité, un simple nmap -sV sur l'ip te dit tout.
Pas si évident ! Je viens de faire le test chez moi !
Il n’a pas trouvé le port sur lequel j'ai détourné mon ssh.
J'ai du faire un nmap -sV 192.168.2.1 -p le_port_en_question, et là, j'ai bien eu ssh comme réponse.
- La liste de diffusion de Mandriva débutant qui a su me donner des idées et répondre à mes questions.
- "LINUX Initiation et utilisation" pour 1er et 2e cycles - IUT - Ecoles d'ingénieurs de Jean-Paul Armspach, Pierre Colin et Frédérique Ostré-Waerzeggers chez DUNOD (attention erreur : page 6 Mandriva est gratuite)
- Les sites internet cités tout au long de ce document au moment où je m'en sert.
- http://www.via.ecp.fr/~alexis/formation-linux/ (C'est sur débian, mais même pour Mandriva, il y a de bonnes choses!)
- Alain Térieur pour ses remarques
- Henry CHERMETTE pour quelque remarques et surtout pour une grosse correction orthographique.
- Christophe Jenaux pour le chapitre sur les partitions
- Marc Guillaume <new@yakati.org> pour le chapitre sur le serveur NTP
Copyright (c) 2003, 2004, 2005, 2006, 2011, 2018 Bernard SIAUD.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
chapitre sur le serveur NTP :
(c) Guillermo Ballester Valor, 2003
Version 0.1.2 24/09/2003
Licencia GPL
adaptation en français (c) 2003 Marc Guillaume
version 0.0.1 12/12/2003
licence GFDL
Chapitre sur les partitions :
Copyright (c) 2003 Christophe JENAUX.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
Chapitre sur https :
Copyright (c) 2004 Emmuel BETTLER.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
Permission is granted to copy, distribute and/or modify this document
under the terms of the GNU Free Documentation License, Version 1.2
or any later version published by the Free Software Foundation;
with no Invariant Sections, no Front-Cover Texts, and no Back-Cover
Texts. A copy of the license is included in the section entitled
"GNU Free Documentation License".
addgroup 22
anacron 25
anacrontab 25
apache 47
apt-get 28
bashrc 39
bg 24
BIND 74
cancel 93
case 16
cat 12
cd 11
chgrp 23
chkconfig 26
chmod 23
chown 23
compiler le noyau 112
contrôle parental 81
cp 12
cron 25
crontab 25
Cups 93
cyrus-imapd 87
Dansguardian 81
Debian 6
DHCP 82
distributions 6
distributions lives 7
DNS 74
emacs 13
exports 57
fail2ban 116
Fedora 6
fg 24
Fichiers 10
formater une disquette 114
forum 55
FQDN 74
fstab 59
fuser 60
Gentoo 6
GNU 5
gproftpd 37
group 22
groupadd 22
groupdel 22
Grub 119
hda 8
httpd 47
HTTPS 51
if 14
imap 87
imprimante 93
Indexes 47
insecure 59
interfaces graphiques 5
jobs 24
kerberos 60
kill 24
killall 24
la 11
LDAP 100
ldapadd 101
ldapdelete 102
ldapmodify 102
ldapsearch 102
less 12
LFS 6
liens 10
lilo 114, 119
Linux 5
ll 11
ln 13
localhost 47
log 116
ls 11
LUFS 61
mac adresse 34, 82
Mageia 6
man 10
Mandrake 6
Mandriva 6
md 12
mdir 12
menu.lst 120
mkdir 12
more 12
mount 60
MTA 85
mv 12
MyDNS-Admin 77
MySQL 53
netstat 115
newgrp 22
nfs 57
NIS 91
nmap 34, 115
NTP 30
nut 125
Onduleur 124
Openldap 100
partitions 8
passwd 22
php 47, 49
phpinfo 49
phpMyAdmin 54
port forwarding 42
portmap 58
postix 85
Proxy 79
ps 24
pwd 11
Redhat 6
Répertoires 10
Rescuecd 7
rm 12
rmdir 12
rpm 27
rsync 116
run level 26
rwx 23
saned 94
scanner 94
scp 40
sed 16
sg 22
SGID 23
shfs 61
Slackware 6
slapcat 101
smart 28
smb.conf 108
smbldap-passwd 109
smbldap-useradd 109
smbldap-userdel 109
squid 79
SSHFS 62
su 22
su - 22
SUID 23
SuSE 6
syslog 116
syslog.conf 116
System rescue 7
system V init 17
systemctl 16, 116
systemd 16
Terminal serveur X 84
top 24
transport_maps 87
Tunnel ssh 42
Tunneling ». 42
Ubuntu 6
ulog 116
umount 60
Unix 5
UPS 124
urpme 28
urpmi 27
useradd 21
userdel 22
usermod 22
vi 13
VirtualHost 48
WebDAV 50
wiki 55
WM 6
X 6
.bash_profile 21
.bashrc 21
/etc/motd 38
& 24
iUNIX : système d'exploitation multi-utilisateur et multi-tâche
iiiXfree86 ou xorg : programme qui fournit des services graphiques.
iv même si c'est dangereux,on peut être logé en root sous X sur TTY1 se logé en root puis « startx -- :0 » (0 = TTY7 ; 1 = TTY8 etc... )
vDe http://www.linux-france.org/article/sys/boot.html.
Un run level peut être vu comme une configuration de contexte d'exploitation bien particulier, c'est-à-dire un ensemble de processus qui doivent être présent dans ce run level, et d'autres processus qui doivent impérativement être tués.
À la fin de la séquence de boot, le kernel va exécuter la commande /bin/init, qui va se charger de lancer certains services nécessaires (c'est-à-dire de placer le système dans un run level particulier). La première chose que cette commande va faire, est de scanner le fichier /etc/inittab. Ce fichier contient, entre autres, la définition du run level par défaut (cherchez la ligne qui contient initdefault)
Dans mon cas, c'est :
# The default runlevel.
id:2:initdefault:
Il y a différents run levels, qui correspondent chez moi à (le 0, 1, 6 est normalisé) :
0 - halt : tous les processus sont tués, les systèmes de fichiers sont démontés, et la machine se bloque, sans rebooter.
1 - mode "utilisateur unique".
2 - multi-utilisateur, sans la possibilité de partager des répertoires par NFS.
3 - idem que le 2, mais avec le NFS cette fois.
4 - inutilisé (on pourrait s'en resservir si nécessaire).
5 - idem que le 3, mais on lance le système de fenêtrage X Window.
6 - reboot : tous les processus sont tués, les systèmes de fichiers sont démontés, et la machine reboote.
S - Single : mode "utilisateur unique", utilisé pour la maintenance.
La fonction principale de /bin/init est de mettre le système dans un run level particulier, avant de rendre la main à l'utilisateur. Par exemple, chez moi, le run level 3 correspond chez moi au mode multi-utilisateur, et le 5 au même mode, mais avec démarage de X-Window.
Un conseil : n'allez pas mettre 0 ou 6 comme run level : dès le boot, votre système se bloquerait, et vous devriez alors passer par la bidouille pour le restaurer.
Enfin, /bin/init peut être utilisé pour changer le run level actuel : un petit "init 6" mettra le système dans le run level 6 (et donc la machine reboote).
viODBC (Open Database Connectivity) est une norme de protocole permettant aux applications d'accéder à des systèmes de bases de données. Le langage de requête utilisé est le SQL (Structured Query Language).
viikerberos : http://www.linux-france.org/prj/jargonf/K/Kerberos.html
Système de sécurité et d'authentification des utilisateurs, mis au point par le projet Athena au MIT. Le principe est de s'adresser à un serveur d'authentification, qui vous remet un « ticket » (on parle plutôt de certificat), avec lequel vous allez pouvoir accéder à la ressource que vous demandez. En pratique, c'est infiniment plus compliqué que ça... Il ne semble pas avoir été piraté depuis sa mise en service, il y a une dizaine d'années.
viiiL'Autorité d'Affectation de Numéros sur Internet (IANA) a réservé les 3 blocs suivants dans l'espace d'adressage pour des réseaux internes.
10.0.0.0 à 10.255.255.255 (10/8 prefix), 172.16.0.0 à 172.31.255.255 (172.16/12 prefix) et 192.168.0.0 à 192.168.255.255 (192.168/16 prefix)
Voir : http://www.eisti.fr/res/res/rfc1918/1918.htm
Ces adresses, qui ne sont jamais visibles sur internet mondial, servent donc pour les réseaux locaux.
ixFQDN : Fully Qualified Domain Name. Le nom complet d'un hôte, sur l'Internet, c'est-à-dire du serveur jusqu'au domaine, en passant par les sous-domaines, en langage à peu près clair, il est en effet nettement plus facile de se souvenir de « www.machin.fr ». que de 194.27.45.254 (numéro tapé au pif). Voir domaine, DNS. Exemple : www.linux-france.com (par opposition au domaine linux-france.org).
voir : http://www.linux-france.org/prj/jargonf/F/FQDN.html
xAdresse unique identifiant un élément actif sur un réseau, constituée de l'OUI de la société l'ayant fabriqué, et d'un nombre à 24 bits attribué par la société en question.
Il est possible de modifier cette adresse et c'est un danger à prendre en compte : http://www.alobbs.com/modules.php?op=modload&name=macc&file=index ou http://www.klcconsulting.net/smac/
xiDMZ : Zone Démilitarisée. C'est le brin de réseau physique compris entre le point d'entrée et le Firewall, où l'on connecte des machines (bastions) proposant des services informatiques publics ou contrôlés. L'offre faite par ces ordinateurs n'est pas considérée comme sensible. Les bastions sont néanmoins installés de façon très sécurisée afin d'éviter des restaurations de système trop souvent.
xiiPATH : Liste des chemins d'accès contenant les commandes. Chaque chemin d'accès est séparé par le caractère : .L'ordre dans la liste correspond à l'ordre de recherche des fichiers exécutables. Ainsi une valeur du PATH=/usr/bin:/usr/sbin:. indique une recherche de la commande dans le répertore /usr/bin, puis /usr/sbin et enfin dans le répertoire conrant indiqué par le point. Normalement, le répertoire courant n'est pas pas le path pour des raisons de sécurité. De ce fait, pour exécuter un fichier dans le répertoire courant, on doit faire ./nom_du_fichier.
xiiiPAM : Des programmes qui permettent à des utilisateurs d'accéder à un système vérifient préalablement l'identité de l'utilisateur au moyen d'un processus d'authentification. Dans le passé, chaque programme de ce genre effectuait les opérations d'authentification d'une manière qui lui était propre. Maintenant, un grand nombre de ces programmes sont configurés de telle sorte qu'ils utilisent un processus d'authentification centralisé appelé modules d'authentification enfichables (ou PAM de l'anglais 'Pluggable Authentication Modules').
PAM offre entre autres les avantages suivants:
il fournit un système d'authentification commun qui pouvant être utilisé avec un vaste éventail d'applications;
il offre un haut degrés de flexibilité et de contrôle en ce qui concerne l'authentification aussi bien au niveau de l'administrateur système qu'au niveau du développeur d'applications;
il permet aux développeurs d'applications de concevoir des programmes sans avoir à créer leur propre système d'authentification.
xivMBR : [amorçage] Master Boot Record. Le premier secteur absolu sur un disque dur de PC : tête 0, piste 0, secteur 1 (parfois 0 lui aussi). Il contient la table des Partitions ou un simple Boot. Voir boot et sa famille. (© VIRUS-L FAQ). Autrefois, la plupart des virus attaquaient par là. Il suffit de configurer la CMOS pour booter systématiquement en premier sur le HD, et au revoir ces virus...
Articles liés à celui-ci : boot sector, LILO, MBP. ( http://www.linux-france.org/prj/jargonf/ )